–†–∞–±–Њ—В–∞ —Б Postgresql: –љ–∞—Б—В—А–Њ–є–Ї–∞, –Љ–∞—Б—И—В–∞–±–Є—А–Њ–≤–∞–љ–Є–µ
=0.1
–Т–∞—Б–Є–ї—М–µ–≤ –Р.–Ѓ.
–†–∞–±–Њ—В–∞ —Б Postgresql
–љ–∞—Б—В—А–Њ–є–Ї–∞, –Љ–∞—Б—И—В–∞–±–Є—А–Њ–≤–∞–љ–Є–µ
—Б–њ—А–∞–≤–Њ—З–љ–Њ–µ –њ–Њ—Б–Њ–±–Є–µ
2010
CREATIVE COMMONS ATTRIBUTION-NONCOMMERCIAL 2.5
–Я—А–Є –љ–∞–њ–Є—Б–∞–љ–Є–Є –Ї–љ–Є–≥–Є(–Љ–∞–љ—Г–∞–ї–∞, –Є–ї–Є –њ—А–Њ—Б—В–Њ —И–њ–∞—А–≥–∞–ї–Ї–Є) –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–ї–Є—Б—М –Љ–∞—В–µ—А–Є–∞–ї—Л:
- PostgreSQL: –љ–∞—Б—В—А–Њ–є–Ї–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є. –Р–ї–µ–Ї—Б–µ–є –С–Њ—А–Ј–Њ–≤ (Sad Spirit) borz_off@cs.msu.su,
http://www.phpclub.ru/detail/store/pdf/postgresql-performance.pdf - –Э–∞—Б—В—А–Њ–є–Ї–∞ —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є –≤ PostgreSQL —Б –њ–Њ–Љ–Њ—Й—М—О —Б–Є—Б—В–µ–Љ—Л Slony-I, Eugene Kuzin eugene@kuzin.net,
http://www.kuzin.net/work/sloniki-privet.html - –£—Б—В–∞–љ–Њ–≤–Ї–∞ Londiste –≤ –њ–Њ–і—А–Њ–±–љ–Њ—Б—В—П—Е, Sergey Konoplev gray.ru@gmail.com,
http://gray-hemp.blogspot.com/2010/04/londiste.html - –£—З–µ–±–љ–Њ–µ —А—Г–Ї–Њ–≤–Њ–і—Б—В–≤–Њ –њ–Њ pgpool-II, Dmitry Stasyuk,
http://undenied.ru/2009/03/04/uchebnoe-rukovodstvo-po-pgpool-ii/ - –У–Њ—А–Є–Ј–Њ–љ—В–∞–ї—М–љ–Њ–µ –Љ–∞—Б—И—В–∞–±–Є—А–Њ–≤–∞–љ–Є–µ PostgreSQL —Б –њ–Њ–Љ–Њ—Й—М—О PL/Proxy, –І–Є—А–Ї–Є–љ –Ф–Є–Љ–∞ dmitry.chirkin@gmail.com,
http://habrahabr.ru/blogs/postgresql/45475/ - Hadoop, –Ш–≤–∞–љ –С–ї–Є–љ–Ї–Њ–≤ wordpress@insight-it.ru,
http://www.insight-it.ru/masshtabiruemost/hadoop/ - Up and Running with HadoopDB, Padraig O'Sullivan,
http://posulliv.github.com/2010/05/10/hadoopdb-mysql.html - –Ь–∞—Б—И—В–∞–±–Є—А–Њ–≤–∞–љ–Є–µ PostgreSQL: –≥–Њ—В–Њ–≤—Л–µ —А–µ—И–µ–љ–Є—П –Њ—В Skype, –Ш–≤–∞–љ –Ч–Њ–ї–Њ—В—Г—Е–Є–љ,
http://postgresmen.ru/articles/view/25 - Streaming Replication,
http://wiki.postgresql.org/wiki/Streaming_Replication - –®–∞—А–і–Є–љ–≥, –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ, —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П - –Ј–∞—З–µ–Љ –Є –Ї–Њ–≥–і–∞?, Den Golotyuk,
http://highload.com.ua/index.php/2009/05/06/—И–∞—А–і–Є–љ–≥-–њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ-—А–µ–њ–ї–Є–Ї–∞—Ж/
ell
Contents
- 1 –Т–≤–µ–і–µ–љ–Є–µ
- 2 –Э–∞—Б—В—А–Њ–є–Ї–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є
- 1 –Т–≤–µ–і–µ–љ–Є–µ
- 2 –Э–∞—Б—В—А–Њ–є–Ї–∞ —Б–µ—А–≤–µ—А–∞
- 3 –Ф–Є—Б–Ї–Є –Є —Д–∞–є–ї–Њ–≤—Л–µ —Б–Є—Б—В–µ–Љ—Л
- 4 –Я—А–Є–Љ–µ—А—Л –љ–∞—Б—В—А–Њ–µ–Ї
- 1 –°—А–µ–і–љ–µ—Б—В–∞—В–Є—Б—В–Є—З–µ—Б–Ї–∞—П –љ–∞—Б—В—А–Њ–є–Ї–∞ –і–ї—П –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–є –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є
- 2 –°—А–µ–і–љ–µ—Б—В–∞—В–Є—Б—В–Є—З–µ—Б–Ї–∞—П –љ–∞—Б—В—А–Њ–є–Ї–∞ –і–ї—П –Њ–Ї–Њ–љ–љ–Њ–≥–Њ –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П (1–°), 2 –У–С –њ–∞–Љ—П—В–Є
- 3 –°—А–µ–і–љ–µ—Б—В–∞—В–Є—Б—В–Є—З–µ—Б–Ї–∞—П –љ–∞—Б—В—А–Њ–є–Ї–∞ –і–ї—П Web –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П, 2 –У–С –њ–∞–Љ—П—В–Є
- 4 –°—А–µ–і–љ–µ—Б—В–∞—В–Є—Б—В–Є—З–µ—Б–Ї–∞—П –љ–∞—Б—В—А–Њ–є–Ї–∞ –і–ї—П Web –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П, 8 –У–С –њ–∞–Љ—П—В–Є
- 5 –Р–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Њ–µ —Б–Њ–Ј–і–∞–љ–Є–µ –Њ–њ—В–Є–Љ–∞–ї—М–љ—Л—Е –љ–∞—Б—В—А–Њ–µ–Ї: pgtune
- 6 –Ю–њ—В–Є–Љ–Є–Ј–∞—Ж–Є—П –С–Ф –Є –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П
- 7 –Ч–∞–Ї–ї—О—З–µ–љ–Є–µ
- 3 –Я–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ
- 1 –Т–≤–µ–і–µ–љ–Є–µ
- 2 –Ґ–µ–Њ—А–Є—П
- 3 –Я—А–∞–Ї—В–Є–Ї–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П
- 4 –Ч–∞–Ї–ї—О—З–µ–љ–Є–µ
- 4 –†–µ–њ–ї–Є–Ї–∞—Ж–Є—П
- 5 –®–∞—А–і–Є–љ–≥
- 6 –Ь—Г–ї—М—В–Є–њ–ї–µ–Ї—Б–Њ—А—Л —Б–Њ–µ–і–Є–љ–µ–љ–Є–є
- 7 –С—Н–Ї–∞–њ –Є –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ PostgreSQL
1 –Т–≤–µ–і–µ–љ–Є–µ

–Ф–∞–љ–љ–∞—П –Ї–љ–Є–≥–∞ –љ–µ –і–∞–µ—В –Њ—В–≤–µ—В—Л –љ–∞ –≤—Б–µ –≤–Њ–њ—А–Њ—Б—Л –њ–Њ —А–∞–±–Њ—В–µ —Б PostgreSQL. –У–ї–∞–≤–љ–Њ–µ –µ—С –Ј–∞–і–∞–љ–Є–µ -- –њ–Њ–Ї–∞–Ј–∞—В—М –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є PostgreSQL, –Љ–µ—В–Њ–і–Є–Ї–Є –љ–∞—Б—В—А–Њ–є–Ї–Є –Є –Љ–∞—Б—И—В–∞–±–Є—А—Г–µ–Љ–Њ—Б—В–Є —Н—В–Њ–є –°–£–С–Ф. –Т –ї—О–±–Њ–Љ —Б–ї—Г—З–∞–µ, –≤—Л–±–Њ—А –Љ–µ—В–Њ–і–∞ —А–µ—И–µ–љ–Є—П –њ–Њ—Б—В–∞–≤–ї–µ–љ–љ–Њ–є –Ј–∞–і–∞—З–Є –Њ—Б—В–∞–µ—В—Б—П –Ј–∞ —А–∞–Ј—А–∞–±–Њ—В—З–Є–Ї–Њ–Љ –Є–ї–Є –∞–і–Љ–Є–љ–Є—Б—В—А–∞—В–Њ—А–Њ–Љ –°–£–С–Ф.
2 –Э–∞—Б—В—А–Њ–є–Ї–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є
1 –Т–≤–µ–і–µ–љ–Є–µ
–°–Ї–Њ—А–Њ—Б—В—М —А–∞–±–Њ—В—Л, –≤–Њ–Њ–±—Й–µ –≥–Њ–≤–Њ—А—П, –љ–µ —П–≤–ї—П–µ—В—Б—П –Њ—Б–љ–Њ–≤–љ–Њ–є –њ—А–Є—З–Є–љ–Њ–є –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П —А–µ–ї—П—Ж–Є–Њ–љ–љ—Л—Е –°–£–С–Ф. –С–Њ–ї–µ–µ —В–Њ–≥–Њ, –њ–µ—А–≤—Л–µ —А–µ–ї—П—Ж–Є–Њ–љ–љ—Л–µ –±–∞–Ј—Л —А–∞–±–Њ—В–∞–ї–Є –Љ–µ–і–ї–µ–љ–љ–µ–µ —Б–≤–Њ–Є—Е –њ—А–µ–і—И–µ—Б—В–≤–µ–љ–љ–Є–Ї–Њ–≤. –Т—Л–±–Њ—А —Н—В–Њ–є —В–µ—Е–љ–Њ–ї–Њ–≥–Є–Є –±—Л–ї –≤—Л–Ј–≤–∞–љ —Б–Ї–Њ—А–µ–µ- –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М—О –≤–Њ–Ј–ї–Њ–ґ–Є—В—М –њ–Њ–і–і–µ—А–ґ–Ї—Г —Ж–µ–ї–Њ—Б—В–љ–Њ—Б—В–Є –і–∞–љ–љ—Л—Е –љ–∞ –°–£–С–Ф;
- –љ–µ–Ј–∞–≤–Є—Б–Є–Љ–Њ—Б—В—М—О –ї–Њ–≥–Є—З–µ—Б–Ї–Њ–є —Б—В—А—Г–Ї—В—Г—А—Л –і–∞–љ–љ—Л—Е –Њ—В —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є.
–≠—В–Є –Њ—Б–Њ–±–µ–љ–љ–Њ—Б—В–Є –њ–Њ–Ј–≤–Њ–ї—П—О—В —Б–Є–ї—М–љ–Њ —Г–њ—А–Њ—Б—В–Є—В—М –љ–∞–њ–Є—Б–∞–љ–Є–µ –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є, –љ–Њ —В—А–µ–±—Г—О—В –і–ї—П —Б–≤–Њ–µ–є —А–µ–∞–ї–Є–Ј–∞—Ж–Є–Є –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л—Е —А–µ—Б—Г—А—Б–Њ–≤.
–Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, –њ—А–µ–ґ–і–µ, —З–µ–Љ –Є—Б–Ї–∞—В—М –Њ—В–≤–µ—В –љ–∞ –≤–Њ–њ—А–Њ—Б «–Ї–∞–Ї –Ј–∞—Б—В–∞–≤–Є—В—М –†–°–£–С–Ф —А–∞–±–Њ—В–∞—В—М –±—Л—Б—В—А–µ–µ –≤ –Љ–Њ–µ–є –Ј–∞–і–∞—З–µ?» —Б–ї–µ–і—Г–µ—В –Њ—В–≤–µ—В–Є—В—М –љ–∞ –≤–Њ–њ—А–Њ—Б «–љ–µ—В –ї–Є –±–Њ–ї–µ–µ –њ–Њ–і—Е–Њ–і—П—Й–µ–≥–Њ —Б—А–µ–і—Б—В–≤–∞ –і–ї—П —А–µ—И–µ–љ–Є—П –Љ–Њ–µ–є –Ј–∞–і–∞—З–Є, —З–µ–Љ –†–°–£–С–Ф?» –Ш–љ–Њ–≥–і–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –і—А—Г–≥–Њ–≥–Њ —Б—А–µ–і—Б—В–≤–∞ –њ–Њ—В—А–µ–±—Г–µ—В –Љ–µ–љ—М—И–µ —Г—Б–Є–ї–Є–є, —З–µ–Љ –љ–∞—Б—В—А–Њ–є–Ї–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є.
–Ф–∞–љ–љ–∞—П –≥–ї–∞–≤–∞ –њ–Њ—Б–≤—П—Й–µ–љ–∞ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—П–Љ –њ–Њ–≤—Л—И–µ–љ–Є—П –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є PostgreSQL. –У–ї–∞–≤–∞ –љ–µ –њ—А–µ—В–µ–љ–і—Г–µ—В –љ–∞ –Є—Б—З–µ—А–њ—Л–≤–∞—О—Й–µ–µ –Є–Ј–ї–Њ–ґ–µ–љ–Є–µ –≤–Њ–њ—А–Њ—Б–∞, –љ–∞–Є–±–Њ–ї–µ–µ –њ–Њ–ї–љ—Л–Љ –Є —В–Њ—З–љ—Л–Љ —А—Г–Ї–Њ–≤–Њ–і—Б—В–≤–Њ–Љ –њ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—О PostgreSQL —П–≤–ї—П–µ—В—Б—П, –Ї–Њ–љ–µ—З–љ–Њ, –Њ—Д–Є—Ж–Є–∞–ї—М–љ–∞—П –і–Њ–Ї—Г–Љ–µ–љ—В–∞—Ж–Є—П –Є –Њ—Д–Є—Ж–Є–∞–ї—М–љ—Л–є FAQ. –Ґ–∞–Ї–ґ–µ —Б—Г—Й–µ—Б—В–≤—Г–µ—В –∞–љ–≥–ї–Њ—П–Ј—Л—З–љ—Л–є —Б–њ–Є—Б–Њ–Ї —А–∞—Б—Б—Л–ї–Ї–Є postgresql-performance, –њ–Њ—Б–≤—П—Й—С–љ–љ—Л–є –Є–Љ–µ–љ–љ–Њ —Н—В–Є–Љ –≤–Њ–њ—А–Њ—Б–∞–Љ. –У–ї–∞–≤–∞ —Б–Њ—Б—В–Њ–Є—В –Є–Ј –і–≤—Г—Е —А–∞–Ј–і–µ–ї–Њ–≤, –њ–µ—А–≤—Л–є –Є–Ј –Ї–Њ—В–Њ—А—Л—Е –Њ—А–Є–µ–љ—В–Є—А–Њ–≤–∞–љ —Б–Ї–Њ—А–µ–µ –љ–∞ –∞–і–Љ–Є–љ–Є—Б—В—А–∞—В–Њ—А–∞, –≤—В–Њ—А–Њ–є -- –љ–∞ —А–∞–Ј—А–∞–±–Њ—В—З–Є–Ї–∞ –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є. –†–µ–Ї–Њ–Љ–µ–љ–і—Г–µ—В—Б—П –њ—А–Њ—З–µ—Б—В—М –Њ–±–∞ —А–∞–Ј–і–µ–ї–∞: –Њ—В–љ–µ—Б–µ–љ–Є–µ –Љ–љ–Њ–≥–Є—Е –≤–Њ–њ—А–Њ—Б–Њ–≤ –Ї –Ї–∞–Ї–Њ–Љ—Г-—В–Њ –Њ–і–љ–Њ–Љ—Г –Є–Ј –љ–Є—Е –≤–µ—Б—М–Љ–∞ —Г—Б–ї–Њ–≤–љ–Њ.
1 –Э–µ –Є—Б–њ–Њ–ї—М–Ј—Г–є—В–µ –љ–∞—Б—В—А–Њ–є–Ї–Є –њ–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О
–Я–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О PostgreSQL —Б–Ї–Њ–љ—Д–Є–≥—Г—А–Є—А–Њ–≤–∞–љ —В–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, —З—В–Њ–±—Л –Њ–љ –Љ–Њ–≥ –±—Л—В—М –Ј–∞–њ—Г—Й–µ–љ –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–Є –љ–∞ –ї—О–±–Њ–Љ –Ї–Њ–Љ–њ—М—О—В–µ—А–µ –Є –љ–µ —Б–ї–Є—И–Ї–Њ–Љ –Љ–µ—И–∞–ї –њ—А–Є —Н—В–Њ–Љ —А–∞–±–Њ—В–µ –і—А—Г–≥–Є—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є. –≠—В–Њ –Њ—Б–Њ–±–µ–љ–љ–Њ –Ї–∞—Б–∞–µ—В—Б—П –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ–Њ–є –њ–∞–Љ—П—В–Є. –Э–∞—Б—В—А–Њ–є–Ї–Є –њ–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О –њ–Њ–і—Е–Њ–і—П—В —В–Њ–ї—М–Ї–Њ –і–ї—П —Б–ї–µ–і—Г—О—Й–µ–≥–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П: —Б –љ–Є–Љ–Є –≤—Л —Б–Љ–Њ–ґ–µ—В–µ –њ—А–Њ–≤–µ—А–Є—В—М, —А–∞–±–Њ—В–∞–µ—В –ї–Є —Г—Б—В–∞–љ–Њ–≤–Ї–∞ PostgreSQL, —Б–Њ–Ј–і–∞—В—М —В–µ—Б—В–Њ–≤—Г—О –±–∞–Ј—Г —Г—А–Њ–≤–љ—П –Ј–∞–њ–Є—Б–љ–Њ–є –Ї–љ–Є–ґ–Ї–Є –Є –њ–Њ—В—А–µ–љ–Є—А–Њ–≤–∞—В—М—Б—П –њ–Є—Б–∞—В—М –Ї –љ–µ–є –Ј–∞–њ—А–Њ—Б—Л. –Х—Б–ї–Є –≤—Л —Б–Њ–±–Є—А–∞–µ—В–µ—Б—М —А–∞–Ј—А–∞–±–∞—В—Л–≤–∞—В—М (–∞ —В–µ–Љ –±–Њ–ї–µ–µ –Ј–∞–њ—Г—Б–Ї–∞—В—М –≤ —А–∞–±–Њ—В—Г) —А–µ–∞–ї—М–љ—Л–µ –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П, —В–Њ –љ–∞—Б—В—А–Њ–є–Ї–Є –њ—А–Є–і—С—В—Б—П —А–∞–і–Є–Ї–∞–ї—М–љ–Њ –Є–Ј–Љ–µ–љ–Є—В—М. –Т –і–Є—Б—В—А–Є–±—Г—В–Є–≤–µ PostgreSQL, –Ї —Б–Њ–ґ–∞–ї–µ–љ–Є—О, –љ–µ –њ–Њ—Б—В–∞–≤–ї—П–µ—В—Б—П —Д–∞–є–ї–Њ–≤ —Б «—А–µ–Ї–Њ–Љ–µ–љ–і—Г–µ–Љ—Л–Љ–Є» –љ–∞—Б—В—А–Њ–є–Ї–∞–Љ–Є. –Т–Њ–Њ–±—Й–µ –≥–Њ–≤–Њ—А—П, —В–∞–Ї–Є–µ —Д–∞–є–ї—Л —Б–Њ–Ј–і–∞—В—М –≤–µ—Б—М–Љ–∞ —Б–ї–Њ–ґ–љ–Њ, —В.–Ї. –Њ–њ—В–Є–Љ–∞–ї—М–љ—Л–µ –љ–∞—Б—В—А–Њ–є–Ї–Є –Ї–Њ–љ–Ї—А–µ—В–љ–Њ–є —Г—Б—В–∞–љ–Њ–≤–Ї–Є PostgreSQL –±—Г–і—Г—В –Њ–њ—А–µ–і–µ–ї—П—В—М—Б—П:- –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–µ–є –Ї–Њ–Љ–њ—М—О—В–µ—А–∞;
- –Њ–±—К—С–Љ–Њ–Љ –Є —В–Є–њ–Њ–Љ –і–∞–љ–љ—Л—Е, —Е—А–∞–љ—П—Й–Є—Е—Б—П –≤ –±–∞–Ј–µ;
- –Њ—В–љ–Њ—И–µ–љ–Є–µ–Љ —З–Є—Б–ї–∞ –Ј–∞–њ—А–Њ—Б–Њ–≤ –љ–∞ —З—В–µ–љ–Є–µ –Є –љ–∞ –Ј–∞–њ–Є—Б—М;
- —В–µ–Љ, –Ј–∞–њ—Г—Й–µ–љ—Л –ї–Є –і—А—Г–≥–Є–µ —В—А–µ–±–Њ–≤–∞—В–µ–ї—М–љ—Л–µ –Ї —А–µ—Б—Г—А—Б–∞–Љ –њ—А–Њ—Ж–µ—Б—Б—Л (–љ–∞–њ—А–Є–Љ–µ—А, –≤–µ–±—Б–µ—А–≤–µ—А).
2 –Ш—Б–њ–Њ–ї—М–Ј—Г–є—В–µ –∞–Ї—В—Г–∞–ї—М–љ—Г—О –≤–µ—А—Б–Є—О —Б–µ—А–≤–µ—А–∞
–Х—Б–ї–Є —Г –≤–∞—Б —Б—В–Њ–Є—В —Г—Б—В–∞—А–µ–≤—И–∞—П –≤–µ—А—Б–Є—П PostgreSQL, —В–Њ –љ–∞–Є–±–Њ–ї—М—И–µ–≥–Њ —Г—Б–Ї–Њ—А–µ–љ–Є—П —А–∞–±–Њ—В—Л –≤—Л —Б–Љ–Њ–ґ–µ—В–µ –і–Њ–±–Є—В—М—Б—П, –Њ–±–љ–Њ–≤–Є–≤ –µ—С –і–Њ —В–µ–Ї—Г—Й–µ–є. –£–Ї–∞–ґ–µ–Љ –ї–Є—И—М –љ–∞–Є–±–Њ–ї–µ–µ –Ј–љ–∞—З–Є—В–µ–ї—М–љ—Л–µ –Є–Ј —Б–≤—П–Ј–∞–љ–љ—Л—Е —Б –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М—О –Є–Ј–Љ–µ–љ–µ–љ–Є–є.- –Т –≤–µ—А—Б–Є–Є 7.1 –њ–Њ—П–≤–Є–ї—Б—П –ґ—Г—А–љ–∞–ї —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є, –і–Њ —В–Њ–≥–Њ –і–∞–љ–љ—Л–µ –≤ —В–∞–±–ї–Є—Ж—Г —Б–±—А–∞—Б—Л–≤–∞–ї–Є—Б—М –Ї–∞–ґ–і—Л–є —А–∞–Ј –њ—А–Є —Г—Б–њ–µ—И–љ–Њ–Љ –Ј–∞–≤–µ—А—И–µ–љ–Є–Є —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є.
- –Т –≤–µ—А—Б–Є–Є 7.2 –њ–Њ—П–≤–Є–ї–Є—Б—М:
- –љ–Њ–≤–∞—П –≤–µ—А—Б–Є—П –Ї–Њ–Љ–∞–љ–і—Л VACUUM, –љ–µ —В—А–µ–±—Г—О—Й–∞—П –±–ї–Њ–Ї–Є—А–Њ–≤–Ї–Є;
- –Ї–Њ–Љ–∞–љ–і–∞ ANALYZE, —Б—В—А–Њ—П—Й–∞—П –≥–Є—Б—В–Њ–≥—А–∞–Љ–Љ—Г —А–∞—Б–њ—А–µ–і–µ–ї–µ–љ–Є—П –і–∞–љ–љ—Л—Е –≤ —Б—В–Њ–ї–±—Ж–∞—Е, —З—В–Њ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –≤—Л–±–Є—А–∞—В—М –±–Њ–ї–µ–µ –±—Л—Б—В—А—Л–µ –њ–ї–∞–љ—Л –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Ј–∞–њ—А–Њ—Б–Њ–≤;
- –њ–Њ–і—Б–Є—Б—В–µ–Љ–∞ —Б–±–Њ—А–∞ —Б—В–∞—В–Є—Б—В–Є–Ї–Є.
- –Т –≤–µ—А—Б–Є–Є 7.4 –±—Л–ї–∞ —Г—Б–Ї–Њ—А–µ–љ–∞ —А–∞–±–Њ—В–∞ –Љ–љ–Њ–≥–Є—Е —Б–ї–Њ–ґ–љ—Л—Е –Ј–∞–њ—А–Њ—Б–Њ–≤ (–≤–Ї–ї—О—З–∞—П –њ–µ—З–∞–ї—М–љ–Њ –Є–Ј–≤–µ—Б—В–љ—Л–µ –њ–Њ–і–Ј–∞–њ—А–Њ—Б—Л IN/NOT IN).
- –Т –≤–µ—А—Б–Є–Є 8.0 –±—Л–ї–Њ –≤–љ–µ–і—А–µ–љ–Њ –Љ–µ—В–Ї–Є –≤–Њ—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є—П, —Г–ї—Г—З—И–µ–љ–Є–µ —Г–њ—А–∞–≤–ї–µ–љ–Є—П –±—Г—Д–µ—А–Њ–Љ, CHECKPOINT –Є VACUUM —Г–ї—Г—З—И–µ–љ—Л.
- –Т –≤–µ—А—Б–Є–Є 8.1 –±—Л–ї–Њ —Г–ї—Г—З—И–µ–љ–Њ –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ—Л–є –і–Њ—Б—В—Г–њ –Ї —А–∞–Ј–і–µ–ї—П–µ–Љ–Њ–є –њ–∞–Љ—П—В–Є, –∞–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Є –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –Є–љ–і–µ–Ї—Б–Њ–≤ –і–ї—П MIN() –Є MAX(), pg_autovacuum –≤–љ–µ–і—А–µ–љ –≤ —Б–µ—А–≤–µ—А (–∞–≤—В–Њ–Љ–∞—В–Є–Ј–Є—А–Њ–≤–∞–љ), –њ–Њ–≤—Л—И–µ–љ–Є–µ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є –і–ї—П —Б–µ–Ї—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–љ—Л—Е —В–∞–±–ї–Є—Ж.
- –Т –≤–µ—А—Б–Є–Є 8.2 –±—Л–ї–Њ —Г–ї—Г—З—И–µ–љ–Њ —Б–Ї–Њ—А–Њ—Б—В—М –Љ–љ–Њ–ґ–µ—Б—В–≤–∞ SQL –Ј–∞–њ—А–Њ—Б–Њ–≤, —Г—Б–Њ–≤–µ—А—И–µ–љ—Б—В–≤–Њ–≤–∞–љ —Б–∞–Љ —П–Ј—Л–Ї –Ј–∞–њ—А–Њ—Б–Њ–≤.
- –Т –≤–µ—А—Б–Є–Є 8.3 –≤–љ–µ–і—А–µ–љ –њ–Њ–ї–љ–Њ—В–µ–Ї—Б—В–Њ–≤—Л–є –њ–Њ–Є—Б–Ї, –њ–Њ–і–і–µ—А–ґ–Ї–∞ SQL/XML —Б—В–∞–љ–і–∞—А—В–∞, –њ–∞—А–∞–Љ–µ—В—А—Л –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–Є —Б–µ—А–≤–µ—А–∞ –Љ–Њ–≥—Г—В –±—Л—В—М —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ—Л –љ–∞ –Њ—Б–љ–Њ–≤–µ –Њ—В–і–µ–ї—М–љ—Л—Е —Д—Г–љ–Ї—Ж–Є–є.
- –Т –≤–µ—А—Б–Є–Є 8.4 –±—Л–ї–Њ –≤–љ–µ–і—А–µ–љ–Њ –Њ–±—Й–Є–µ —В–∞–±–ї–Є—З–љ—Л–µ –≤—Л—А–∞–ґ–µ–љ–Є—П, —А–µ–Ї—Г—А—Б–Є–≤–љ—Л–µ –Ј–∞–њ—А–Њ—Б—Л, –њ–∞—А–∞–ї–ї–µ–ї—М–љ–Њ–µ –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ, —Г–ї—Г—З—И–µ–љ–љ–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М –і–ї—П EXISTS/NOT EXISTS –Ј–∞–њ—А–Њ—Б–Њ–≤.
- –Т –≤–µ—А—Б–Є–Є 9.0 «—А–µ–њ–ї–Є–Ї–∞—Ж–Є—П –Є–Ј –Ї–Њ—А–Њ–±–Ї–Є», VACUUM/VACUUM FULL —Б—В–∞–ї–Є –±—Л—Б—В—А–µ–µ, —А–∞—Б—И–Є—А–µ–љ—Л —Е—А–∞–љ–Є–Љ—Л–µ –њ—А–Њ—Ж–µ–і—Г—А—Л.
3 –°—В–Њ–Є—В –ї–Є –і–Њ–≤–µ—А—П—В—М —В–µ—Б—В–∞–Љ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є
–Я–µ—А–µ–і —В–µ–Љ, –Ї–∞–Ї –Ј–∞–љ–Є–Љ–∞—В—М—Б—П –љ–∞—Б—В—А–Њ–є–Ї–Њ–є —Б–µ—А–≤–µ—А–∞, –≤–њ–Њ–ї–љ–µ –µ—Б—В–µ—Б—В–≤–µ–љ–љ–Њ –Њ–Ј–љ–∞–Ї–Њ–Љ–Є—В—М—Б—П —Б –Њ–њ—Г–±–ї–Є–Ї–Њ–≤–∞–љ–љ—Л–Љ–Є –і–∞–љ–љ—Л–Љ–Є –њ–Њ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є, –≤ —В–Њ–Љ —З–Є—Б–ї–µ –≤ —Б—А–∞–≤–љ–µ–љ–Є–Є —Б –і—А—Г–≥–Є–Љ–Є –°–£–С–Ф. –Ъ —Б–Њ–ґ–∞–ї–µ–љ–Є—О, –Љ–љ–Њ–≥–Є–µ —В–µ—Б—В—Л —Б–ї—Г–ґ–∞—В –љ–µ —Б—В–Њ–ї—М–Ї–Њ –і–ї—П –Њ–±–ї–µ–≥—З–µ–љ–Є—П –≤–∞—И–µ–≥–Њ –≤—Л–±–Њ—А–∞, —Б–Ї–Њ–ї—М–Ї–Њ –і–ї—П –њ—А–Њ–і–≤–Є–ґ–µ–љ–Є—П –Ї–Њ–љ–Ї—А–µ—В–љ—Л—Е –њ—А–Њ–і—Г–Ї—В–Њ–≤ –≤ –Ї–∞—З–µ—Б—В–≤–µ «—Б–∞–Љ—Л—Е –±—Л—Б—В—А—Л—Е». –Я—А–Є –Є–Ј—Г—З–µ–љ–Є–Є –Њ–њ—Г–±–ї–Є–Ї–Њ–≤–∞–љ–љ—Л—Е —В–µ—Б—В–Њ–≤ –≤ –њ–µ—А–≤—Г—О –Њ—З–µ—А–µ–і—М –Њ–±—А–∞—В–Є—В–µ –≤–љ–Є–Љ–∞–љ–Є–µ, —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –ї–Є –≤–µ–ї–Є—З–Є–љ–∞ –Є —В–Є–њ –љ–∞–≥—А—Г–Ј–Ї–Є, –Њ–±—К—С–Љ –і–∞–љ–љ—Л—Е –Є —Б–ї–Њ–ґ–љ–Њ—Б—В—М –Ј–∞–њ—А–Њ—Б–Њ–≤ –≤ —В–µ—Б—В–µ —В–Њ–Љ—Г, —З—В–Њ –≤—Л —Б–Њ–±–Є—А–∞–µ—В–µ—Б—М –і–µ–ї–∞—В—М —Б –±–∞–Ј–Њ–є? –Я—Г—Б—В—М, –љ–∞–њ—А–Є–Љ–µ—А, –Њ–±—Л—З–љ–Њ–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –≤–∞—И–µ–≥–Њ –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П –њ–Њ–і—А–∞–Ј—Г–Љ–µ–≤–∞–µ—В –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ–Њ —А–∞–±–Њ—В–∞—О—Й–Є—Е –Ј–∞–њ—А–Њ—Б–Њ–≤ –љ–∞ –Њ–±–љ–Њ–≤–ї–µ–љ–Є–µ –Ї —В–∞–±–ї–Є—Ж–µ –≤ –Љ–Є–ї–ї–Є–Њ–љ—Л –Ј–∞–њ–Є—Б–µ–є. –Т —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ –°–£–С–Ф, –Ї–Њ—В–Њ—А–∞—П –≤ –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ —А–∞–Ј –±—Л—Б—В—А–µ–µ –≤—Б–µ—Е –Њ—Б—В–∞–ї—М–љ—Л—Е –Є—Й–µ—В –Ј–∞–њ–Є—Б—М –≤ —В–∞–±–ї–Є—Ж–µ –≤ —В—Л—Б—П—З—Г –Ј–∞–њ–Є—Б–µ–є, –Љ–Њ–ґ–µ—В –Њ–Ї–∞–Ј–∞—В—М—Б—П –љ–µ –ї—Г—З—И–Є–Љ –≤—Л–±–Њ—А–Њ–Љ. –Э—Г –Є –љ–∞–Ї–Њ–љ–µ—Ж, –≤–µ—Й–Є, –Ї–Њ—В–Њ—А—Л–µ –і–Њ–ї–ґ–љ—Л —Б—А–∞–Ј—Г –љ–∞—Б—В–Њ—А–Њ–ґ–Є—В—М:- –Ґ–µ—Б—В–Є—А–Њ–≤–∞–љ–Є–µ —Г—Б—В–∞—А–µ–≤—И–µ–є –≤–µ—А—Б–Є–Є –°–£–С–Ф.
- –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –љ–∞—Б—В—А–Њ–µ–Ї –њ–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О (–Є–ї–Є –Њ—В—Б—Г—В—Б—В–≤–Є–µ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Є –Њ –љ–∞—Б—В—А–Њ–є–Ї–∞—Е).
- –Ґ–µ—Б—В–Є—А–Њ–≤–∞–љ–Є–µ –≤ –Њ–і–љ–Њ–њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М—Б–Ї–Њ–Љ —А–µ–ґ–Є–Љ–µ (–µ—Б–ї–Є, –Ї–Њ–љ–µ—З–љ–Њ, –≤—Л –љ–µ –њ—А–µ–і–њ–Њ–ї–∞–≥–∞–µ—В–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –°–£–С–Ф –Є–Љ–µ–љ–љ–Њ —В–∞–Ї).
- –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —А–∞—Б—И–Є—А–µ–љ–љ—Л—Е –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–µ–є –Њ–і–љ–Њ–є –°–£–С–Ф –њ—А–Є –Є–≥–љ–Њ—А–Є—А–Њ–≤–∞–љ–Є–Є —А–∞—Б—И–Є—А–µ–љ–љ—Л—Е –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–µ–є –і—А—Г–≥–Њ–є.
- –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –Ј–∞–≤–µ–і–Њ–Љ–Њ –Љ–µ–і–ї–µ–љ–љ–Њ —А–∞–±–Њ—В–∞—О—Й–Є—Е –Ј–∞–њ—А–Њ—Б–Њ–≤ (—Б–Љ. –њ—Г–љ–Ї—В 3.4).
2 –Э–∞—Б—В—А–Њ–є–Ї–∞ —Б–µ—А–≤–µ—А–∞
–Т —Н—В–Њ–Љ —А–∞–Ј–і–µ–ї–µ –Њ–њ–Є—Б–∞–љ—Л —А–µ–Ї–Њ–Љ–µ–љ–і—Г–µ–Љ—Л–µ –Ј–љ–∞—З–µ–љ–Є—П –њ–∞—А–∞–Љ–µ—В—А–Њ–≤, –≤–ї–Є—П—О—Й–Є—Е –љ–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М –°–£–С–Ф. –≠—В–Є –њ–∞—А–∞–Љ–µ—В—А—Л –Њ–±—Л—З–љ–Њ —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—О—В—Б—П –≤ –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–Њ–љ–љ–Њ–Љ —Д–∞–є–ї–µ postgresql.conf –Є –≤–ї–Є—П—О—В –љ–∞ –≤—Б–µ –±–∞–Ј—Л –≤ —В–µ–Ї—Г—Й–µ–є —Г—Б—В–∞–љ–Њ–≤–Ї–µ.
1 –Ш—Б–њ–Њ–ї—М–Ј—Г–µ–Љ–∞—П –њ–∞–Љ—П—В—М
1 –Ю–±—Й–Є–є –±—Г—Д–µ—А —Б–µ—А–≤–µ—А–∞: shared_buffers
PostgreSQL –љ–µ —З–Є—В–∞–µ—В –і–∞–љ–љ—Л–µ –љ–∞–њ—А—П–Љ—Г—О —Б –і–Є—Б–Ї–∞ –Є –љ–µ –њ–Є—И–µ—В –Є—Е —Б—А–∞–Ј—Г –љ–∞ –і–Є—Б–Ї. –Ф–∞–љ–љ—Л–µ –Ј–∞–≥—А—Г–ґ–∞—О—В—Б—П –≤ –Њ–±—Й–Є–є –±—Г—Д–µ—А —Б–µ—А–≤–µ—А–∞, –љ–∞—Е–Њ–і—П—Й–Є–є—Б—П –≤ —А–∞–Ј–і–µ–ї—П–µ–Љ–Њ–є –њ–∞–Љ—П—В–Є, —Б–µ—А–≤–µ—А–љ—Л–µ –њ—А–Њ—Ж–µ—Б—Б—Л —З–Є—В–∞—О—В –Є –њ–Є—И—Г—В –±–ї–Њ–Ї–Є –≤ —Н—В–Њ–Љ –±—Г—Д–µ—А–µ, –∞ –Ј–∞—В–µ–Љ —Г–ґ–µ –Є–Ј–Љ–µ–љ–µ–љ–Є—П —Б–±—А–∞—Б—Л–≤–∞—О—В—Б—П –љ–∞ –і–Є—Б–Ї.–Х—Б–ї–Є –њ—А–Њ—Ж–µ—Б—Б—Г –љ—Г–ґ–µ–љ –і–Њ—Б—В—Г–њ –Ї —В–∞–±–ї–Є—Ж–µ, —В–Њ –Њ–љ —Б–љ–∞—З–∞–ї–∞ –Є—Й–µ—В –љ—Г–ґ–љ—Л–µ –±–ї–Њ–Ї–Є –≤ –Њ–±—Й–µ–Љ –±—Г—Д–µ—А–µ. –Х—Б–ї–Є –±–ї–Њ–Ї–Є –њ—А–Є—Б—Г—В—Б—В–≤—Г—О—В, —В–Њ –Њ–љ –Љ–Њ–ґ–µ—В –њ—А–Њ–і–Њ–ї–ґ–∞—В—М —А–∞–±–Њ—В—Г, –µ—Б–ї–Є –љ–µ—В -- –і–µ–ї–∞–µ—В—Б—П —Б–Є—Б—В–µ–Љ–љ—Л–є –≤—Л–Ј–Њ–≤ –і–ї—П –Є—Е –Ј–∞–≥—А—Г–Ј–Ї–Є. –Ч–∞–≥—А—Г–ґ–∞—В—М—Б—П –±–ї–Њ–Ї–Є –Љ–Њ–≥—Г—В –Ї–∞–Ї –Є–Ј —Д–∞–є–ї–Њ–≤–Њ–≥–Њ –Ї—Н—И–∞ –Ю–°, —В–∞–Ї –Є —Б –і–Є—Б–Ї–∞, –Є —Н—В–∞ –Њ–њ–µ—А–∞—Ж–Є—П –Љ–Њ–ґ–µ—В –Њ–Ї–∞–Ј–∞—В—М—Б—П –≤–µ—Б—М–Љ–∞ «–і–Њ—А–Њ–≥–Њ–є».
–Х—Б–ї–Є –Њ–±—К—С–Љ –±—Г—Д–µ—А–∞ –љ–µ–і–Њ—Б—В–∞—В–Њ—З–µ–љ –і–ї—П —Е—А–∞–љ–µ–љ–Є—П —З–∞—Б—В–Њ –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ—Л—Е —А–∞–±–Њ—З–Є—Е –і–∞–љ–љ—Л—Е, —В–Њ –Њ–љ–Є –±—Г–і—Г—В –њ–Њ—Б—В–Њ—П–љ–љ–Њ –њ–Є—Б–∞—В—М—Б—П –Є —З–Є—В–∞—В—М—Б—П –Є–Ј –Ї—Н—И–∞ –Ю–° –Є–ї–Є —Б –і–Є—Б–Ї–∞, —З—В–Њ –Ї—А–∞–є–љ–µ –Њ—В—А–Є—Ж–∞—В–µ–ї—М–љ–Њ —Б–Ї–∞–ґ–µ—В—Б—П –љ–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є.
–Т —В–Њ –ґ–µ –≤—А–µ–Љ—П –љ–µ —Б–ї–µ–і—Г–µ—В —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М —Н—В–Њ –Ј–љ–∞—З–µ–љ–Є–µ —Б–ї–Є—И–Ї–Њ–Љ –±–Њ–ї—М—И–Є–Љ: —Н—В–Њ –Э–Х –≤—Б—П –њ–∞–Љ—П—В—М, –Ї–Њ—В–Њ—А–∞—П –љ—Г–ґ–љ–∞ –і–ї—П —А–∞–±–Њ—В—Л PostgreSQL, —Н—В–Њ —В–Њ–ї—М–Ї–Њ —А–∞–Ј–Љ–µ—А —А–∞–Ј–і–µ–ї—П–µ–Љ–Њ–є –Љ–µ–ґ–і—Г –њ—А–Њ—Ж–µ—Б—Б–∞–Љ–Є PostgreSQL –њ–∞–Љ—П—В–Є, –Ї–Њ—В–Њ—А–∞—П –љ—Г–ґ–љ–∞ –і–ї—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –∞–Ї—В–Є–≤–љ—Л—Е –Њ–њ–µ—А–∞—Ж–Є–є. –Ю–љ–∞ –і–Њ–ї–ґ–љ–∞ –Ј–∞–љ–Є–Љ–∞—В—М –Љ–µ–љ—М—И—Г—О —З–∞—Б—В—М –Њ–њ–µ—А–∞—В–Є–≤–љ–Њ–є –њ–∞–Љ—П—В–Є –≤–∞—И–µ–≥–Њ –Ї–Њ–Љ–њ—М—О—В–µ—А–∞, —В–∞–Ї –Ї–∞–Ї PostgreSQL –њ–Њ–ї–∞–≥–∞–µ—В—Б—П –љ–∞ —В–Њ, —З—В–Њ –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–∞—П —Б–Є—Б—В–µ–Љ–∞ –Ї—Н—И–Є—А—Г–µ—В —Д–∞–є–ї—Л, –Є –љ–µ —Б—В–∞—А–∞–µ—В—Б—П –і—Г–±–ї–Є—А–Њ–≤–∞—В—М —Н—В—Г —А–∞–±–Њ—В—Г. –Ъ—А–Њ–Љ–µ —В–Њ–≥–Њ, —З–µ–Љ –±–Њ–ї—М—И–µ –њ–∞–Љ—П—В–Є –±—Г–і–µ—В –Њ—В–і–∞–љ–Њ –њ–Њ–і –±—Г—Д–µ—А, —В–µ–Љ –Љ–µ–љ—М—И–µ –Њ—Б—В–∞–љ–µ—В—Б—П –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–Њ–є —Б–Є—Б—В–µ–Љ–µ –Є –і—А—Г–≥–Є–Љ –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П–Љ, —З—В–Њ –Љ–Њ–ґ–µ—В –њ—А–Є–≤–µ—Б—В–Є –Ї —Б–≤–Њ–њ–њ–Є–љ–≥—Г.
–Ъ —Б–Њ–ґ–∞–ї–µ–љ–Є—О, —З—В–Њ–±—Л –Ј–љ–∞—В—М —В–Њ—З–љ–Њ–µ —З–Є—Б–ї–Њ shared_buffers, –љ—Г–ґ–љ–Њ —Г—З–µ—Б—В—М –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –Њ–њ–µ—А–∞—В–Є–≤–љ–Њ–є –њ–∞–Љ—П—В–Є –Ї–Њ–Љ–њ—М—О—В–µ—А–∞, —А–∞–Ј–Љ–µ—А –±–∞–Ј—Л –і–∞–љ–љ—Л—Е, —З–Є—Б–ї–Њ —Б–Њ–µ–і–Є–љ–µ–љ–Є–є –Є —Б–ї–Њ–ґ–љ–Њ—Б—В—М –Ј–∞–њ—А–Њ—Б–Њ–≤, —В–∞–Ї —З—В–Њ –ї—Г—З—И–µ –≤–Њ—Б–њ–Њ–ї—М–Ј—Г–µ–Љ—Б—П –љ–µ—Б–Ї–Њ–ї—М–Ї–Є–Љ–Є –њ—А–Њ—Б—В—Л–Љ–Є –њ—А–∞–≤–Є–ї–∞–Љ–Є –љ–∞—Б—В—А–Њ–є–Ї–Є.
–Э–∞ –≤—Л–і–µ–ї–µ–љ–љ—Л—Е —Б–µ—А–≤–µ—А–∞—Е –њ–Њ–ї–µ–Ј–љ—Л–Љ –Њ–±—К–µ–Љ–Њ–Љ –±—Г–і–µ—В –Ј–љ–∞—З–µ–љ–Є–µ –Њ—В 8 –Ь–С –і–Њ 2 –У–С. –Ю–±—К–µ–Љ –Љ–Њ–ґ–µ—В –±—Л—В—М –≤—Л—И–µ, –µ—Б–ї–Є —Г –≤–∞—Б –±–Њ–ї—М—И–Є–µ –∞–Ї—В–Є–≤–љ—Л–µ –њ–Њ—А—Ж–Є–Є –±–∞–Ј—Л –і–∞–љ–љ—Л—Е, —Б–ї–Њ–ґ–љ—Л–µ –Ј–∞–њ—А–Њ—Б—Л, –±–Њ–ї—М—И–Њ–µ —З–Є—Б–ї–Њ –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ—Л—Е —Б–Њ–µ–і–Є–љ–µ–љ–Є–є, –і–ї–Є—В–µ–ї—М–љ—Л–µ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є, –≤–∞–Љ –і–Њ—Б—В—Г–њ–µ–љ –±–Њ–ї—М—И–Њ–є –Њ–±—К–µ–Љ –Њ–њ–µ—А–∞—В–Є–≤–љ–Њ–є –њ–∞–Љ—П—В–Є –Є–ї–Є –±–Њ–ї—М—И–µ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–Њ–≤. –Ш, –Ї–Њ–љ–µ—З–љ–Њ –ґ–µ, –љ–µ –Ј–∞–±—Л–≤–∞–µ–Љ –Њ–± –Њ—Б—В–∞–ї—М–љ—Л—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П—Е. –Т—Л–і–µ–ї–Є–≤ —Б–ї–Є—И–Ї–Њ–Љ –Љ–љ–Њ–≥–Њ –њ–∞–Љ—П—В–Є –і–ї—П –±–∞–Ј—Л –і–∞–љ–љ—Л—Е, –Љ—Л –Љ–Њ–ґ–µ–Љ –њ–Њ–ї—Г—З–Є—В—М —Г—Е—Г–і—И–µ–љ–Є–µ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є. –Т –Ї–∞—З–µ—Б—В–≤–µ –љ–∞—З–∞–ї—М–љ—Л—Е –Ј–љ–∞—З–µ–љ–Є–є –Љ–Њ–ґ–µ—В–µ –њ–Њ–њ—А–Њ–±–Њ–≤–∞—В—М —Б–ї–µ–і—Г—О—Й–Є–µ:
- –Э–∞—З–љ–Є—В–µ —Б 4 –Ь–С (512) –і–ї—П —А–∞–±–Њ—З–µ–є —Б—В–∞–љ—Ж–Є–Є
- –°—А–µ–і–љ–Є–є –Њ–±—К—С–Љ –і–∞–љ–љ—Л—Е –Є 256-512 –Ь–С –і–Њ—Б—В—Г–њ–љ–Њ–є –њ–∞–Љ—П—В–Є: 16-32 –Ь–С (2048-4096)
- –С–Њ–ї—М—И–Њ–є –Њ–±—К—С–Љ –і–∞–љ–љ—Л—Е –Є 1-4 –У–С –і–Њ—Б—В—Г–њ–љ–Њ–є –њ–∞–Љ—П—В–Є: 64-256 –Ь–С (8192-32768)
–Ф–ї—П —В–Њ–љ–Ї–Њ–є –љ–∞—Б—В—А–Њ–є–Ї–Є –њ–∞—А–∞–Љ–µ—В—А–∞ —Г—Б—В–∞–љ–Њ–≤–Є—В–µ –і–ї—П –љ–µ–≥–Њ –±–Њ–ї—М—И–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ –Є –њ–Њ—В–µ—Б—В–Є—А—Г–є—В–µ –±–∞–Ј—Г –њ—А–Є –Њ–±—Л—З–љ–Њ–є –љ–∞–≥—А—Г–Ј–Ї–µ.
–Я—А–Њ–≤–µ—А—П–є—В–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —А–∞–Ј–і–µ–ї—П–µ–Љ–Њ–є –њ–∞–Љ—П—В–Є –њ—А–Є –њ–Њ–Љ–Њ—Й–Є ipcs –Є–ї–Є –і—А—Г–≥–Є—Е —Г—В–Є–ї–Є—В(–љ–∞–њ—А–Є–Љ–µ—А, free –Є–ї–Є vmstat).
–†–µ–Ї–Њ–Љ–µ–љ–і—Г–µ–Љ–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ –њ–∞—А–∞–Љ–µ—В—А–∞
–±—Г–і–µ—В –њ—А–Є–Љ–µ—А–љ–Њ –≤ 1,2 -2 —А–∞–Ј–∞ –±–Њ–ї—М—И–µ, —З–µ–Љ –Љ–∞–Ї—Б–Є–Љ—Г–Љ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–љ–Њ–є –њ–∞–Љ—П—В–Є. –Ю–±—А–∞—В–Є—В–µ –≤–љ–Є–Љ–∞–љ–Є–µ, —З—В–Њ –њ–∞–Љ—П—В—М –њ–Њ–і –±—Г—Д–µ—А
–≤—Л–і–µ–ї—П—В—Б—П –њ—А–Є –Ј–∞–њ—Г—Б–Ї–µ —Б–µ—А–≤–µ—А–∞, –Є –µ—С –Њ–±—К—С–Љ –њ—А–Є —А–∞–±–Њ—В–µ –љ–µ –Є–Ј–Љ–µ–љ—П–µ—В—Б—П. –£—З—В–Є—В–µ —В–∞–Ї–ґ–µ, —З—В–Њ –љ–∞—Б—В—А–Њ–є–Ї–Є —П–і—А–∞ –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–Њ–є
—Б–Є—Б—В–µ–Љ—Л –Љ–Њ–≥—Г—В –љ–µ –і–∞—В—М –≤–∞–Љ –≤—Л–і–µ–ї–Є—В—М –±–Њ–ї—М—И–Њ–є –Њ–±—К—С–Љ –њ–∞–Љ—П—В–Є. –Т —А—Г–Ї–Њ–≤–Њ–і—Б—В–≤–µ –∞–і–Љ–Є–љ–Є—Б—В—А–∞—В–Њ—А–∞ PostgreSQL –Њ–њ–Є—Б–∞–љ–Њ, –Ї–∞–Ї
–Љ–Њ–ґ–љ–Њ –Є–Ј–Љ–µ–љ–Є—В—М —Н—В–Є –љ–∞—Б—В—А–Њ–є–Ї–Є:
http://developer.postgresql.org/docs/postgres/kernel-resources.html
–Т–Њ—В –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –њ—А–Є–Љ–µ—А–Њ–≤, –њ–Њ–ї—Г—З–µ–љ–љ—Л—Е –љ–∞ –ї–Є—З–љ–Њ–Љ –Њ–њ—Л—В–µ –Є –њ—А–Є —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є–Є:
- Laptop, Celeron processor, 384 –Ь–С RAM, –±–∞–Ј–∞ –і–∞–љ–љ—Л—Е 25 –Ь–С: 12 –Ь–С
- Athlon server, 1 –У–С RAM, –±–∞–Ј–∞ –і–∞–љ–љ—Л—Е –њ–Њ–і–і–µ—А–ґ–Ї–Є –њ—А–Є–љ—П—В–Є—П —А–µ—И–µ–љ–Є–є 10 –У–С: 200 –Ь–С
- Quad PIII server, 4 –У–С RAM, 40 –У–С, 150 —Б–Њ–µ–і–Є–љ–µ–љ–Є–є, «—В—П–ґ–µ–ї—Л–µ» —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є: 1 –У–С
- Quad Xeon server, 8 –У–С RAM, 200 –У–С, 300 —Б–Њ–µ–і–Є–љ–µ–љ–Є–є, «—В—П–ґ–µ–ї—Л–µ» —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є: 2 –У–С
2 –Я–∞–Љ—П—В—М –і–ї—П —Б–Њ—А—В–Є—А–Њ–≤–Ї–Є —А–µ–Ј—Г–ї—М—В–∞—В–∞ –Ј–∞–њ—А–Њ—Б–∞: work_mem
–†–∞–љ–µ–µ –Є–Ј–≤–µ—Б—В–љ–Њ–µ –Ї–∞–Ї sort_mem, –±—Л–ї–Њ –њ–µ—А–µ–Є–Љ–µ–љ–Њ–≤–∞–љ–Њ, —В–∞–Ї –Ї–∞–Ї —Б–µ–є—З–∞—Б –Њ–њ—А–µ–і–µ–ї—П–µ—В –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –Њ–њ–µ—А–∞—В–Є–≤–љ–Њ–є –њ–∞–Љ—П—В–Є, –Ї–Њ—В–Њ—А–Њ–µ –Љ–Њ–ґ–µ—В –≤—Л–і–µ–ї–Є—В—М –Њ–і–љ–∞ –Њ–њ–µ—А–∞—Ж–Є—П —Б–Њ—А—В–Є—А–Њ–≤–Ї–Є, –∞–≥—А–µ–≥–∞—Ж–Є–Є –Є –і—А. –≠—В–Њ –љ–µ —А–∞–Ј–і–µ–ї—П–µ–Љ–∞—П –њ–∞–Љ—П—В—М, work_mem –≤—Л–і–µ–ї—П–µ—В—Б—П –Њ—В–і–µ–ї—М–љ–Њ –љ–∞ –Ї–∞–ґ–і—Г—О –Њ–њ–µ—А–∞—Ж–Є—О (–Њ—В –Њ–і–љ–Њ–≥–Њ –і–Њ –љ–µ—Б–Ї–Њ–ї—М–Ї–Є—Е —А–∞–Ј –Ј–∞ –Њ–і–Є–љ –Ј–∞–њ—А–Њ—Б). –†–∞–Ј—Г–Љ–љ–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ –њ–∞—А–∞–Љ–µ—В—А–∞ –Њ–њ—А–µ–і–µ–ї—П–µ—В—Б—П —Б–ї–µ–і—Г—О—Й–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ: –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –і–Њ—Б—В—Г–њ–љ–Њ–є –Њ–њ–µ—А–∞—В–Є–≤–љ–Њ–є –њ–∞–Љ—П—В–Є (–њ–Њ—Б–ї–µ —В–Њ–≥–Њ, –Ї–∞–Ї –Є–Ј –Њ–±—Й–µ–≥–Њ –Њ–±—К–µ–Љ–∞ –≤—Л—З–ї–Є –њ–∞–Љ—П—В—М, —В—А–µ–±—Г–µ–Љ—Г—О –і–ї—П –і—А—Г–≥–Є—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є, –Є shared_buffers) –і–µ–ї–Є—В—Б—П –љ–∞ –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–µ —З–Є—Б–ї–Њ –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ—Л—Е –Ј–∞–њ—А–Њ—Б–Њ–≤ —Г–Љ–љ–Њ–ґ–µ–љ–љ–Њ–µ –љ–∞ —Б—А–µ–і–љ–µ–µ —З–Є—Б–ї–Њ –Њ–њ–µ—А–∞—Ж–Є–є –≤ –Ј–∞–њ—А–Њ—Б–µ, –Ї–Њ—В–Њ—А—Л–µ —В—А–µ–±—Г—О—В –њ–∞–Љ—П—В–Є.–Х—Б–ї–Є –Њ–±—К—С–Љ –њ–∞–Љ—П—В–Є –љ–µ–і–Њ—Б—В–∞—В–Њ—З–µ–љ –і–ї—П —Б–Њ—А—В–Є—А–Њ–Ї–Є –љ–µ–Ї–Њ—В–Њ—А–Њ–≥–Њ —А–µ–Ј—Г–ї—М—В–∞—В–∞, —В–Њ —Б–µ—А–≤–µ—А–љ—Л–є –њ—А–Њ—Ж–µ—Б—Б –±—Г–і–µ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –≤—А–µ–Љ–µ–љ–љ—Л–µ —Д–∞–є–ї—Л. –Х—Б–ї–Є –ґ–µ –Њ–±—К—С–Љ –њ–∞–Љ—П—В–Є —Б–ї–Є—И–Ї–Њ–Љ –≤–µ–ї–Є–Ї, —В–Њ —Н—В–Њ –Љ–Њ–ґ–µ—В –њ—А–Є–≤–µ—Б—В–Є –Ї —Б–≤–Њ–њ–њ–Є–љ–≥—Г.
–Ю–±—К—С–Љ –њ–∞–Љ—П—В–Є –Ј–∞–і–∞—С—В—Б—П –њ–∞—А–∞–Љ–µ—В—А–Њ–Љ work_mem –≤ —Д–∞–є–ї–µ postgresql.conf. –Х–і–Є–љ–Є—Ж–∞ –Є–Ј–Љ–µ—А–µ–љ–Є—П –њ–∞—А–∞–Љ–µ—В—А–∞ -- 1 –Ї–С. –Ч–љ–∞—З–µ–љ–Є–µ –њ–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О -- 1024. –Т –Ї–∞—З–µ—Б—В–≤–µ –љ–∞—З–∞–ї—М–љ–Њ–≥–Њ –Ј–љ–∞—З–µ–љ–Є—П –і–ї—П –њ–∞—А–∞–Љ–µ—В—А–∞ –Љ–Њ–ґ–µ—В–µ –≤–Ј—П—В—М 2-4% –і–Њ—Б—В—Г–њ–љ–Њ–є –њ–∞–Љ—П—В–Є. –Ф–ї—П –≤–µ–±-–њ—А–Є–ї–Њ–ґ–µ–љ–Є–є –Њ–±—Л—З–љ–Њ —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—О—В –љ–Є–Ј–Ї–Є–µ –Ј–љ–∞—З–µ–љ–Є—П work_mem, —В–∞–Ї –Ї–∞–Ї –Ј–∞–њ—А–Њ—Б–Њ–≤ –Њ–±—Л—З–љ–Њ –Љ–љ–Њ–≥–Њ, –љ–Њ –Њ–љ–Є –њ—А–Њ—Б—В—Л–µ, –Њ–±—Л—З–љ–Њ —Е–≤–∞—В–∞–µ—В –Њ—В 512 –і–Њ 2048 –Ъ–С. –° –і—А—Г–≥–Њ–є —Б—В–Њ—А–Њ–љ—Л, –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П –і–ї—П –њ–Њ–і–і–µ—А–ґ–Ї–Є –њ—А–Є–љ—П—В–Є—П —А–µ—И–µ–љ–Є–є —Б —Б–Њ—В–љ—П–Љ–Є —Б—В—А–Њ–Ї –≤ –Ї–∞–ґ–і–Њ–Љ –Ј–∞–њ—А–Њ—Б–µ –Є –і–µ—Б—П—В–Ї–∞–Љ–Є –Љ–Є–ї–ї–Є–Њ–љ–Њ–≤ —Б—В–Њ–ї–±—Ж–Њ–≤ –≤ —В–∞–±–ї–Є—Ж–∞—Е —Д–∞–Ї—В–Њ–≤ —З–∞—Б—В–Њ —В—А–µ–±—Г—О—В work_mem –њ–Њ—А—П–і–Ї–∞ 500 –Ь–С. –Ф–ї—П –±–∞–Ј –і–∞–љ–љ—Л—Е, –Ї–Њ—В–Њ—А—Л–µ –Є—Б–њ–Њ–ї—М–Ј—Г—О—В—Б—П –Є —В–∞–Ї, –Є —В–∞–Ї, —Н—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А –Љ–Њ–ґ–љ–Њ —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М –і–ї—П –Ї–∞–ґ–і–Њ–≥–Њ –Ј–∞–њ—А–Њ—Б–∞ –Є–љ–і–Є–≤–Є–і—Г–∞–ї—М–љ–Њ, –Є—Б–њ–Њ–ї—М–Ј—Г—П –љ–∞—Б—В—А–Њ–є–Ї–Є —Б–µ—Б—Б–Є–Є. –Э–∞–њ—А–Є–Љ–µ—А, –њ—А–Є –њ–∞–Љ—П—В–Є 1-4 –У–С —А–µ–Ї–Њ–Љ–µ–љ–і—Г–µ—В—Б—П —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М 32-128 MB.
3 –Я–∞–Љ—П—В—М –і–ї—П —А–∞–±–Њ—В—Л –Ї–Њ–Љ–∞–љ–і—Л VACUUM: maintenance_work_mem
–Я—А–µ–і—Л–і—Г—Й–µ–µ –љ–∞–Ј–≤–∞–љ–Є–µ –≤ PostgreSQL 7.x vacuum_mem. –≠—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А –Ј–∞–і–∞—С—В –Њ–±—К—С–Љ –њ–∞–Љ—П—В–Є, –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ—Л–є –Ї–Њ–Љ–∞–љ–і–∞–Љ–Є VACUUM, ANALYZE, CREATE INDEX, –Є –і–Њ–±–∞–≤–ї–µ–љ–Є—П –≤–љ–µ—И–љ–Є—Е –Ї–ї—О—З–µ–є. –І—В–Њ–±—Л –Њ–њ–µ—А–∞—Ж–Є–Є –≤—Л–њ–Њ–ї–љ—П–ї–Є—Б—М –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ –±—Л—Б—В—А–Њ, –љ—Г–ґ–љ–Њ —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М —Н—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А —В–µ–Љ –≤—Л—И–µ, —З–µ–Љ –±–Њ–ї—М—И–µ —А–∞–Ј–Љ–µ—А —В–∞–±–ї–Є—Ж –≤ –≤–∞—И–µ–є –±–∞–Ј–µ –і–∞–љ–љ—Л—Е. –Э–µ–њ–ї–Њ—Е–Њ –±—Л —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М –µ–≥–Њ –Ј–љ–∞—З–µ–љ–Є–µ –Њ—В 50 –і–Њ 75% —А–∞–Ј–Љ–µ—А–∞ –≤–∞—И–µ–є —Б–∞–Љ–Њ–є –±–Њ–ї—М—И–Њ–є —В–∞–±–ї–Є—Ж—Л –Є–ї–Є –Є–љ–і–µ–Ї—Б–∞ –Є–ї–Є, –µ—Б–ї–Є —В–Њ—З–љ–Њ –Њ–њ—А–µ–і–µ–ї–Є—В—М –љ–µ–≤–Њ–Ј–Љ–Њ–ґ–љ–Њ, –Њ—В 32 –і–Њ 256 –Ь–С. –°–ї–µ–і—Г–µ—В —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М –±–Њ–ї—М—И–µ–µ –Ј–љ–∞—З–µ–љ–Є–µ, —З–µ–Љ –і–ї—П work_mem. –°–ї–Є—И–Ї–Њ–Љ –±–Њ–ї—М—И–Є–µ –Ј–љ–∞—З–µ–љ–Є—П –њ—А–Є–≤–µ–і—Г—В –Ї –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—О —Б–≤–Њ–њ–∞. –Э–∞–њ—А–Є–Љ–µ—А, –њ—А–Є –њ–∞–Љ—П—В–Є 1-4 –У–С —А–µ–Ї–Њ–Љ–µ–љ–і—Г–µ—В—Б—П —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М 128-512 MB.
4 Free Space Map: –Ї–∞–Ї –Є–Ј–±–∞–≤–Є—В—М—Б—П –Њ—В VACUUM FULL
–Ю—Б–Њ–±–µ–љ–љ–Њ—Б—В—П–Љ–Є –≤–µ—А—Б–Є–Њ–љ–љ—Л—Е –і–≤–Є–ґ–Ї–Њ–≤ –С–Ф (–Ї –Ї–Њ—В–Њ—А—Л–Љ –Њ—В–љ–Њ—Б–Є—В—Б—П –Є –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ—Л–є –≤ PostgreSQL) —П–≤–ї—П–µ—В—Б—П —Б–ї–µ–і—Г—О—Й–µ–µ:- –Ґ—А–∞–љ–Ј–∞–Ї—Ж–Є–Є, –Є–Ј–Љ–µ–љ—П—О—Й–Є–µ –і–∞–љ–љ—Л–µ –≤ —В–∞–±–ї–Є—Ж–µ, –љ–µ –±–ї–Њ–Ї–Є—А—Г—О—В —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є, —З–Є—В–∞—О—Й–Є–µ –Є–Ј –љ–µ—С –і–∞–љ–љ—Л–µ, –Є –љ–∞–Њ–±–Њ—А–Њ—В (—Н—В–Њ —Е–Њ—А–Њ—И–Њ);
- –Я—А–Є –Є–Ј–Љ–µ–љ–µ–љ–Є–Є –і–∞–љ–љ—Л—Е –≤ —В–∞–±–ї–Є—Ж–µ (–Ї–Њ–Љ–∞–љ–і–∞–Љ–Є UPDATE –Є–ї–Є DELETE) –љ–∞–Ї–∞–њ–ї–Є–≤–∞–µ—В—Б—П –Љ—Г—Б–Њ—А1 (–∞ —Н—В–Њ –њ–ї–Њ—Е–Њ).
–Ф–Њ –≤–µ—А—Б–Є–Є 7.2 –Ї–Њ–Љ–∞–љ–і–∞ VACUUM –њ–Њ–ї–љ–Њ—Б—В—М—О –±–ї–Њ–Ї–Є—А–Њ–≤–∞–ї–∞ —В–∞–±–ї–Є—Ж—Г. –Э–∞—З–Є–љ–∞—П —Б –≤–µ—А—Б–Є–Є 7.2, –Ї–Њ–Љ–∞–љ–і–∞ VACUUM –љ–∞–Ї–ї–∞–і—Л–≤–∞–µ—В –±–Њ–ї–µ–µ —Б–ї–∞–±—Г—О –±–ї–Њ–Ї–Є—А–Њ–≤–Ї—Г, –њ–Њ–Ј–≤–Њ–ї—П—О—Й—Г—О –њ–∞—А–∞–ї–ї–µ–ї—М–љ–Њ –≤—Л–њ–Њ–ї–љ—П—В—М –Ї–Њ–Љ–∞–љ–і—Л SELECT, INSERT, UPDATE –Є DELETE –љ–∞–і –Њ–±—А–∞–±–∞—В—Л–≤–∞–µ–Љ–Њ–є —В–∞–±–ї–Є—Ж–µ–є. –°—В–∞—А—Л–є –≤–∞—А–Є–∞–љ—В –Ї–Њ–Љ–∞–љ–і—Л –љ–∞–Ј—Л–≤–∞–µ—В—Б—П —В–µ–њ–µ—А—М VACUUM FULL.
–Э–Њ–≤—Л–є –≤–∞—А–Є–∞–љ—В –Ї–Њ–Љ–∞–љ–і—Л –љ–µ –њ—Л—В–∞–µ—В—Б—П —Г–і–∞–ї–Є—В—М –≤—Б–µ —Б—В–∞—А—Л–µ –≤–µ—А—Б–Є–Є –Ј–∞–њ–Є—Б–µ–є –Є, —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–µ–љ–љ–Њ, —Г–Љ–µ–љ—М—И–Є—В—М —А–∞–Ј–Љ–µ—А —Д–∞–є–ї–∞, —Б–Њ–і–µ—А–ґ–∞—Й–µ–≥–Њ —В–∞–±–ї–Є—Ж—Г, –∞ –ї–Є—И—М –њ–Њ–Љ–µ—З–∞–µ—В –Ј–∞–љ–Є–Љ–∞–µ–Љ–Њ–µ –Є–Љ–Є –Љ–µ—Б—В–Њ –Ї–∞–Ї —Б–≤–Њ–±–Њ–і–љ–Њ–µ. –Ф–ї—П –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Є –Њ —Б–≤–Њ–±–Њ–і–љ–Њ–Љ –Љ–µ—Б—В–µ –µ—Б—В—М —Б–ї–µ–і—Г—О—Й–Є–µ –љ–∞—Б—В—А–Њ–є–Ї–Є:
- max_fsm_relations
–Ь–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —В–∞–±–ї–Є—Ж, –і–ї—П –Ї–Њ—В–Њ—А—Л—Е –±—Г–і–µ—В –Њ—В—Б–ї–µ–ґ–Є–≤–∞—В—М—Б—П —Б–≤–Њ–±–Њ–і–љ–Њ–µ –Љ–µ—Б—В–Њ –≤ –Њ–±—Й–µ–є –Ї–∞—А—В–µ —Б–≤–Њ–±–Њ–і–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞. –≠—В–Є –і–∞–љ–љ—Л–µ —Б–Њ–±–Є—А–∞—О—В—Б—П VACUUM. –Я–∞—А–∞–Љ–µ—В—А max_fsm_relations –і–Њ–ї–ґ–µ–љ –±—Л—В—М –љ–µ –Љ–µ–љ—М—И–µ –Њ–±—Й–µ–≥–Њ –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ —В–∞–±–ї–Є—Ж –≤–Њ –≤—Б–µ—Е –±–∞–Ј–∞—Е –і–∞–љ–љ–Њ–є —Г—Б—В–∞–љ–Њ–≤–Ї–Є (–ї—Г—З—И–µ —Б –Ј–∞–њ–∞—Б–Њ–Љ).
- max_fsm_pages
–Ф–∞–љ–љ—Л–є –њ–∞—А–∞–Љ–µ—В—А –Њ–њ—А–µ–і–µ–ї—П–µ—В —А–∞–Ј–Љ–µ—А —А–µ–µ—Б—В—А–∞, –≤ –Ї–Њ—В–Њ—А–Њ–Љ —Е—А–∞–љ–Є—В—Б—П –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –Њ —З–∞—Б—В–Є—З–љ–Њ –Њ—Б–≤–Њ–±–Њ–ґ–і—С–љ–љ—Л—Е —Б—В—А–∞–љ–Є—Ж–∞—Е –і–∞–љ–љ—Л—Е, –≥–Њ—В–Њ–≤—Л—Е –Ї –Ј–∞–њ–Њ–ї–љ–µ–љ–Є—О –љ–Њ–≤—Л–Љ–Є –і–∞–љ–љ—Л–Љ–Є. –Ч–љ–∞—З–µ–љ–Є–µ —Н—В–Њ–≥–Њ –њ–∞—А–∞–Љ–µ—В—А–∞ –љ—Г–ґ–љ–Њ —Г—Б—В–∞–љ–Њ–≤–Є—В—М —З—Г—В—М –±–Њ–ї—М—И–µ, —З–µ–Љ –њ–Њ–ї–љ–Њ–µ —З–Є—Б–ї–Њ —Б—В—А–∞–љ–Є—Ж, –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–≥—Г—В –±—Л—В—М –Ј–∞—В—А–Њ–љ—Г—В—Л –Њ–њ–µ—А–∞—Ж–Є—П–Љ–Є –Њ–±–љ–Њ–≤–ї–µ–љ–Є—П –Є–ї–Є —Г–і–∞–ї–µ–љ–Є—П –Љ–µ–ґ–і—Г –≤—Л–њ–Њ–ї–љ–µ–љ–Є–µ–Љ VACUUM. –І—В–Њ–±—Л –Њ–њ—А–µ–і–µ–ї–Є—В—М —Н—В–Њ —З–Є—Б–ї–Њ, –Љ–Њ–ґ–љ–Њ –Ј–∞–њ—Г—Б—В–Є—В—М VACUUM VERBOSE ANALYZE –Є –≤—Л—П—Б–љ–Є—В—М –Њ–±—Й–µ–µ —З–Є—Б–ї–Њ —Б—В—А–∞–љ–Є—Ж, –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ—Л—Е –±–∞–Ј–Њ–є –і–∞–љ–љ—Л—Е. max_fsm_pages –Њ–±—Л—З–љ–Њ —В—А–µ–±—Г–µ—В –љ–µ–Љ–љ–Њ–≥–Њ –њ–∞–Љ—П—В–Є, —В–∞–Ї —З—В–Њ –љ–∞ —Н—В–Њ–Љ –њ–∞—А–∞–Љ–µ—В—А–µ –ї—Г—З—И–µ –љ–µ —Н–Ї–Њ–љ–Њ–Љ–Є—В—М.
–Х—Б–ї–Є —Н—В–Є –њ–∞—А–∞–Љ–µ—В—А—Л —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ–љ—Л –≤–µ—А–љ–Њ –Є –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –Њ–±–Њ –≤—Б–µ—Е –Є–Ј–Љ–µ–љ–µ–љ–Є—П—Е –њ–Њ–Љ–µ—Й–∞–µ—В—Б—П –≤ FSM, —В–Њ –Ї–Њ–Љ–∞–љ–і—Л VACUUM –±—Г–і–µ—В –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –і–ї—П —Б–±–Њ—А–Ї–Є –Љ—Г—Б–Њ—А–∞, –µ—Б–ї–Є –љ–µ—В - –њ–Њ–љ–∞–і–Њ–±–Є—В—Б—П VACUUM FULL, –≤–Њ –≤—А–µ–Љ—П —А–∞–±–Њ—В—Л –Ї–Њ—В–Њ—А–Њ–є –љ–Њ—А–Љ–∞–ї—М–љ–Њ–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –С–Ф —Б–Є–ї—М–љ–Њ –Ј–∞—В—А—Г–і–љ–µ–љ–Њ.
–Т–Э–Ш–Ь–Р–Э–Ш–Х! –Э–∞—З–Є–љ–∞—П —Б 8.4 –≤–µ—А—Б–Є–Є fsm –њ–∞—А–∞–Љ–µ—В—А—Л –±—Л–ї–Є —Г–±—А–∞–љ—Л, –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г Free Space Map —Б–Њ—Е—А–∞–љ—П–µ—В—Б—П –љ–∞ –ґ–µ—Б—В–Ї–Є–є –і–Є—Б–Ї, –∞ –љ–µ –≤ –њ–∞–Љ—П—В—М.
5 –Я—А–Њ—З–Є–µ –љ–∞—Б—В—А–Њ–є–Ї–Є
- temp_buffers
–С—Г—Д–µ—А –њ–Њ–і –≤—А–µ–Љ–µ–љ–љ—Л–µ –Њ–±—К–µ–Ї—В—Л, –≤ –Њ—Б–љ–Њ–≤–љ–Њ–Љ –і–ї—П –≤—А–µ–Љ–µ–љ–љ—Л—Е —В–∞–±–ї–Є—Ж. –Ь–Њ–ґ–љ–Њ —Г—Б—В–∞–љ–Њ–≤–Є—В—М –њ–Њ—А—П–і–Ї–∞ 16 –Ь–С.
- max_prepared_transactions
–Ъ–Њ–ї–Є—З–µ—Б—В–≤–Њ –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ–Њ –њ–Њ–і–≥–Њ—В–∞–≤–ї–Є–≤–∞–µ–Љ—Л—Е —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є (PREPARE TRANSACTION). –Ь–Њ–ґ–љ–Њ –Њ—Б—В–∞–≤–Є—В—М –њ–Њ –і–µ—Д–Њ–ї—В—Г -- 5.
- vacuum_cost_delay
–Х—Б–ї–Є —Г –≤–∞—Б –±–Њ–ї—М—И–Є–µ —В–∞–±–ї–Є—Ж—Л, –Є –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В—Б—П –Љ–љ–Њ–≥–Њ –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ—Л—Е –Њ–њ–µ—А–∞—Ж–Є–є –Ј–∞–њ–Є—Б–Є, –≤–∞–Љ –Љ–Њ–ґ–µ—В –њ—А–Є–≥–Њ–і–Є—В—М—Б—П —Д—Г–љ–Ї—Ж–Є—П, –Ї–Њ—В–Њ—А–∞—П —Г–Љ–µ–љ—М—И–∞–µ—В –Ј–∞—В—А–∞—В—Л –љ–∞ I/O –і–ї—П VACUUM, —А–∞—Б—В—П–≥–Є–≤–∞—П—П –µ–≥–Њ –њ–Њ –≤—А–µ–Љ–µ–љ–Є. –І—В–Њ–±—Л –≤–Ї–ї—О—З–Є—В—М —Н—В—Г —Д—Г–љ–Ї—Ж–Є–Њ–љ–∞–ї—М–љ–Њ—Б—В—М, –љ—Г–ґ–љ–Њ –њ–Њ–і–љ—П—В—М –Ј–љ–∞—З–µ–љ–Є–µ vacuum_cost_delay –≤—Л—И–µ 0. –Ш—Б–њ–Њ–ї—М–Ј—Г–є—В–µ —А–∞–Ј—Г–Љ–љ—Г—О –Ј–∞–і–µ—А–ґ–Ї—Г –Њ—В 50 –і–Њ 200 –Љ—Б. –Ф–ї—П –±–Њ–ї–µ–µ —В–Њ–љ–Ї–Њ–є –љ–∞—Б—В—А–Њ–є–Ї–Є –њ–Њ–≤—Л—И–∞–є—В–µ vacuum_cost_page_hit –Є –њ–Њ–љ–Є–ґ–∞–є—В–µ vacuum_cost_page_limit. –≠—В–Њ –Њ—Б–ї–∞–±–Є—В –≤–ї–Є—П–љ–Є–µ VACUUM, —Г–≤–µ–ї–Є—З–Є–≤ –≤—А–µ–Љ—П –µ–≥–Њ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П. –Т —В–µ—Б—В–∞—Е —Б –њ–∞—А–∞–ї–ї–µ–ї—М–љ—Л–Љ–Є —В—А–∞–љ–Ј–∞–Ї—Ж–Є—П–Љ–Є –ѓ–љ –Т–Є–Ї (Jan Wieck) –њ–Њ–ї—Г—З–Є–ї, —З—В–Њ –њ—А–Є –Ј–љ–∞—З–µ–љ–Є—П—Е delay -- 200, page_hit -- 6 –Є –њ—А–µ–і–µ–ї -- 100 –≤–ї—П–љ–Є–µ VACUUM —Г–Љ–µ–љ—М—И–Є–ї–Њ—Б—М –±–Њ–ї–µ–µ —З–µ–Љ –љ–∞ 80%, –љ–Њ –µ–≥–Њ –і–ї–Є—В–µ–ї—М–љ–Њ—Б—В—М —Г–≤–µ–ї–Є—З–Є–ї–∞—Б—М –≤—В—А–Њ–µ.
- max_stack_depth
–°–њ–µ—Ж–Є–∞–ї—М–љ—Л–є —Б—В–µ–Ї –і–ї—П —Б–µ—А–≤–µ—А–∞, –≤ –Є–і–µ–∞–ї–µ –Њ–љ –і–Њ–ї–ґ–µ–љ —Б–Њ–≤–њ–∞–і–∞—В—М —Б —А–∞–Ј–Љ–µ—А–Њ–Љ —Б—В–µ–Ї–∞, –≤—Л—Б—В–∞–≤–ї–µ–љ–љ–Њ–Љ –≤ —П–і—А–µ –Ю–°. –£—Б—В–∞–љ–Њ–≤–Ї–∞ –±–Њ–ї—М—И–µ–≥–Њ –Ј–љ–∞—З–µ–љ–Є—П, —З–µ–Љ –≤ —П–і—А–µ, –Љ–Њ–ґ–µ—В –њ—А–Є–≤–µ—Б—В–Є –Ї –Њ—И–Є–±–Ї–∞–Љ. –†–µ–Ї–Њ–Љ–µ–љ–і—Г–µ—В—Б—П —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М 2-4 MB.
- max_files_per_process
–Ь–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Д–∞–є–ї–Њ–≤, –Њ—В–Ї—А—Л–≤–∞–µ–Љ—Л—Е –њ—А–Њ—Ж–µ—Б—Б–Њ–Љ –Є –µ–≥–Њ –њ–Њ–і–њ—А–Њ—Ж–µ—Б—Б–∞–Љ–Є –≤ –Њ–і–Є–љ –Љ–Њ–Љ–µ–љ—В –≤—А–µ–Љ–µ–љ–Є. –£–Љ–µ–љ—М—И–Є—В–µ –і–∞–љ–љ—Л–є –њ–∞—А–∞–Љ–µ—В—А, –µ—Б–ї–Є –≤ –њ—А–Њ—Ж–µ—Б—Б–µ —А–∞–±–Њ—В—Л –љ–∞–±–ї—О–і–∞–µ—В—Б—П —Б–Њ–Њ–±—Й–µ–љ–Є–µ «Too many open files».
2 –Ц—Г—А–љ–∞–ї —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –Є –Ї–Њ–љ—В—А–Њ–ї—М–љ—Л–µ —В–Њ—З–Ї–Є
–Ц—Г—А–љ–∞–ї —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є PostgreSQL —А–∞–±–Њ—В–∞–µ—В —Б–ї–µ–і—Г—О—Й–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ: –≤—Б–µ –Є–Ј–Љ–µ–љ–µ–љ–Є—П –≤ —Д–∞–є–ї–∞—Е –і–∞–љ–љ—Л—Е (–≤ –Ї–Њ—В–Њ—А—Л—Е –љ–∞—Е–Њ–і—П—В—Б—П —В–∞–±–ї–Є—Ж—Л –Є –Є–љ–і–µ–Ї—Б—Л) –њ—А–Њ–Є–Ј–≤–Њ–і—П—В—Б—П —В–Њ–ї—М–Ї–Њ –њ–Њ—Б–ї–µ —В–Њ–≥–Њ, –Ї–∞–Ї –Њ–љ–Є –±—Л–ї–Є –Ј–∞–љ–µ—Б–µ–љ—Л –≤ –ґ—Г—А–љ–∞–ї —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є, –њ—А–Є —Н—В–Њ–Љ –Ј–∞–њ–Є—Б–Є –≤ –ґ—Г—А–љ–∞–ї–µ –і–Њ–ї–ґ–љ—Л –±—Л—В—М –≥–∞—А–∞–љ—В–Є—А–Њ–≤–∞–љ–љ–Њ –Ј–∞–њ–Є—Б–∞–љ—Л –љ–∞ –і–Є—Б–Ї.–Т —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ –љ–µ—В –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ—Б—В–Є —Б–±—А–∞—Б—Л–≤–∞—В—М –љ–∞ –і–Є—Б–Ї –Є–Ј–Љ–µ–љ–µ–љ–Є—П –і–∞–љ–љ—Л—Е –њ—А–Є –Ї–∞–ґ–і–Њ–Љ —Г—Б–њ–µ—И–љ–Њ–Љ –Ј–∞–≤–µ—А—И–µ–љ–Є–Є —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є: –≤ —Б–ї—Г—З–∞–µ —Б–±–Њ—П –С–Ф –Љ–Њ–ґ–µ—В –±—Л—В—М –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–∞ –њ–Њ –Ј–∞–њ–Є—Б—П–Љ –≤ –ґ—Г—А–љ–∞–ї–µ. –Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, –і–∞–љ–љ—Л–µ –Є–Ј –±—Г—Д–µ—А–Њ–≤ —Б–±—А–∞—Б—Л–≤–∞—О—В—Б—П –љ–∞ –і–Є—Б–Ї –њ—А–Є –њ—А–Њ—Е–Њ–і–µ –Ї–Њ–љ—В—А–Њ–ї—М–љ–Њ–є —В–Њ—З–Ї–Є: –ї–Є–±–Њ –њ—А–Є –Ј–∞–њ–Њ–ї–љ–µ–љ–Є–Є –љ–µ—Б–Ї–Њ–ї—М–Ї–Є—Е (–њ–∞—А–∞–Љ–µ—В—А checkpoint_segments, –њ–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О 3) —Б–µ–≥–Љ–µ–љ—В–Њ–≤ –ґ—Г—А–љ–∞–ї–∞ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є, –ї–Є–±–Њ —З–µ—А–µ–Ј –Њ–њ—А–µ–і–µ–ї—С–љ–љ—Л–є –Є–љ—В–µ—А–≤–∞–ї –≤—А–µ–Љ–µ–љ–Є (–њ–∞—А–∞–Љ–µ—В—А checkpoint_timeout, –Є–Ј–Љ–µ—А—П–µ—В—Б—П –≤ —Б–µ–Ї—Г–љ–і–∞—Е, –њ–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О 300).
–Ш–Ј–Љ–µ–љ–µ–љ–Є–µ —Н—В–Є—Е –њ–∞—А–∞–Љ–µ—В—А–Њ–≤ –њ—А—П–Љ–Њ –љ–µ –њ–Њ–≤–ї–Є—П–µ—В –љ–∞ —Б–Ї–Њ—А–Њ—Б—В—М —З—В–µ–љ–Є—П, –љ–Њ –Љ–Њ–ґ–µ—В –њ—А–Є–љ–µ—Б—В–Є –±–Њ–ї—М—И—Г—О –њ–Њ–ї—М–Ј—Г, –µ—Б–ї–Є –і–∞–љ–љ—Л–µ –≤ –±–∞–Ј–µ –∞–Ї—В–Є–≤–љ–Њ –Є–Ј–Љ–µ–љ—П—О—В—Б—П.
1 –£–Љ–µ–љ—М—И–µ–љ–Є–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ –Ї–Њ–љ—В—А–Њ–ї—М–љ—Л—Е —В–Њ—З–µ–Ї: checkpoint_segments
–Х—Б–ї–Є –≤ –±–∞–Ј—Г –Ј–∞–љ–Њ—Б—П—В—Б—П –±–Њ–ї—М—И–Є–µ –Њ–±—К—С–Љ—Л –і–∞–љ–љ—Л—Е, —В–Њ –Ї–Њ–љ—В—А–Њ–ї—М–љ—Л–µ —В–Њ—З–Ї–Є –Љ–Њ–≥—Г—В –њ—А–Њ–Є—Б—Е–Њ–і–Є—В—М —Б–ї–Є—И–Ї–Њ–Љ —З–∞—Б—В–Њ2. –Я—А–Є —Н—В–Њ–Љ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М —Г–њ–∞–і—С—В –Є–Ј-–Ј–∞ –њ–Њ—Б—В–Њ—П–љ–љ–Њ–≥–Њ —Б–±—А–∞—Б—Л–≤–∞–љ–Є—П –љ–∞ –і–Є—Б–Ї –і–∞–љ–љ—Л—Е –Є–Ј –±—Г—Д–µ—А–∞.–Ф–ї—П —Г–≤–µ–ї–Є—З–µ–љ–Є—П –Є–љ—В–µ—А–≤–∞–ї–∞ –Љ–µ–ґ–і—Г –Ї–Њ–љ—В—А–Њ–ї—М–љ—Л–Љ–Є —В–Њ—З–Ї–∞–Љ–Є –љ—Г–ґ–љ–Њ —Г–≤–µ–ї–Є—З–Є—В—М –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б–µ–≥–Љ–µ–љ—В–Њ–≤ –ґ—Г—А–љ–∞–ї–∞ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є (checkpoint_segments). –Ф–∞–љ–љ—Л–є –њ–∞—А–∞–Љ–µ—В—А –Њ–њ—А–µ–і–µ–ї—П–µ—В –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б–µ–≥–Љ–µ–љ—В–Њ–≤ (–Ї–∞–ґ–і—Л–є –њ–Њ 16 –Ь–С) –ї–Њ–≥–∞ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –Љ–µ–ґ–і—Г –Ї–Њ–љ—В—А–Њ–ї—М–љ—Л–Љ–Є —В–Њ—З–Ї–∞–Љ–Є. –≠—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А –љ–µ –Є–Љ–µ–µ—В –Њ—Б–Њ–±–Њ–≥–Њ –Ј–љ–∞—З–µ–љ–Є—П –і–ї—П –±–∞–Ј—Л –і–∞–љ–љ—Л—Е, –њ—А–µ–і–љ–∞–Ј–љ–∞—З–µ–љ–љ–Њ–є –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–µ–љ–љ–Њ –і–ї—П —З—В–µ–љ–Є—П, –љ–Њ –і–ї—П –±–∞–Ј –і–∞–љ–љ—Л—Е —Б–Њ –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ–Љ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є —Г–≤–µ–ї–Є—З–µ–љ–Є–µ —Н—В–Њ–≥–Њ –њ–∞—А–∞–Љ–µ—В—А–∞ –Љ–Њ–ґ–µ—В –Њ–Ї–∞–Ј–∞—В—М—Б—П –ґ–Є–Ј–љ–µ–љ–љ–Њ –љ–µ–Њ–±—Е–Њ–і–Є–Љ—Л–Љ. –Т –Ј–∞–≤–Є—Б–Є–Љ–Њ—Б—В–Є –Њ—В –Њ–±—К–µ–Љ–∞ –і–∞–љ–љ—Л—Е —Г—Б—В–∞–љ–Њ–≤–Є—В–µ —Н—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А –≤ –і–Є–∞–њ–∞–Ј–Њ–љ–µ –Њ—В 12 –і–Њ 256 —Б–µ–≥–Љ–µ–љ—В–Њ–≤ –Є, –µ—Б–ї–Є –≤ –ї–Њ–≥–µ –њ–Њ—П–≤–ї—П—О—В—Б—П –њ—А–µ–і—Г–њ—А–µ–ґ–і–µ–љ–Є—П (warning) –Њ —В–Њ–Љ, —З—В–Њ –Ї–Њ–љ—В—А–Њ–ї—М–љ—Л–µ —В–Њ—З–Ї–Є –њ—А–Њ–Є—Б—Е–Њ–і—П—В —Б–ї–Є—И–Ї–Њ–Љ —З–∞—Б—В–Њ, –њ–Њ—Б—В–µ–њ–µ–љ–љ–Њ —Г–≤–µ–ї–Є—З–Є–≤–∞–є—В–µ –µ–≥–Њ. –Ь–µ—Б—В–Њ, —В—А–µ–±—Г–µ–Љ–Њ–µ –љ–∞ –і–Є—Б–Ї–µ, –≤—Л—З–Є—Б–ї—П–µ—В—Б—П –њ–Њ —Д–Њ—А–Љ—Г–ї–µ (checkpoint_segments * 2 + 1) * 16 –Ь–С, —В–∞–Ї —З—В–Њ —Г–±–µ–і–Є—В–µ—Б—М, —З—В–Њ —Г –≤–∞—Б –і–Њ—Б—В–∞—В–Њ—З–љ–Њ —Б–≤–Њ–±–Њ–і–љ–Њ–≥–Њ –Љ–µ—Б—В–∞. –Э–∞–њ—А–Є–Љ–µ—А, –µ—Б–ї–Є –≤—Л –≤—Л—Б—В–∞–≤–Є—В–µ –Ј–љ–∞—З–µ–љ–Є–µ 32, –≤–∞–Љ –њ–Њ—В—А–µ–±—Г–µ—В—Б—П –±–Њ–ї—М—И–µ 1 –У–С –і–Є—Б–Ї–Њ–≤–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞.
–°–ї–µ–і—Г–µ—В —В–∞–Ї–ґ–µ –Њ—В–Љ–µ—В–Є—В—М, —З—В–Њ —З–µ–Љ –±–Њ–ї—М—И–µ –Є–љ—В–µ—А–≤–∞–ї –Љ–µ–ґ–і—Г –Ї–Њ–љ—В—А–Њ–ї—М–љ—Л–Љ–Є —В–Њ—З–Ї–∞–Љ–Є, —В–µ–Љ –і–Њ–ї—М—И–µ –±—Г–і—Г—В –≤–Њ—Б—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М—Б—П –і–∞–љ–љ—Л–µ –њ–Њ –ґ—Г—А–љ–∞–ї—Г —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –њ–Њ—Б–ї–µ —Б–±–Њ—П.
2 fsync –Є —Б—В–Њ–Є—В –ї–Є –µ–≥–Њ —В—А–Њ–≥–∞—В—М
–Э–∞–Є–±–Њ–ї–µ–µ —А–∞–і–Є–Ї–∞–ї—М–љ–Њ–µ –Є–Ј –≤–Њ–Ј–Љ–Њ–ґ–љ—Л—Е —А–µ—И–µ–љ–Є–є -- –≤—Л—Б—В–∞–≤–Є—В—М –Ј–љ–∞—З–µ–љ–Є–µ «off» –њ–∞—А–∞–Љ–µ—В—А—Г fsync. –Я—А–Є —Н—В–Њ–Љ –Ј–∞–њ–Є—Б–Є –≤ –ґ—Г—А–љ–∞–ї–µ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –љ–µ –±—Г–і—Г—В –њ—А–Є–љ—Г–і–Є—В–µ–ї—М–љ–Њ —Б–±—А–∞—Б—Л–≤–∞—В—М—Б—П –љ–∞ –і–Є—Б–Ї, —З—В–Њ –і–∞—Б—В –±–Њ–ї—М—И–Њ–є –њ—А–Є—А–Њ—Б—В —Б–Ї–Њ—А–Њ—Б—В–Є –Ј–∞–њ–Є—Б–Є. –£—З—В–Є—В–µ: –≤—Л –ґ–µ—А—В–≤—Г–µ—В–µ –љ–∞–і—С–ґ–љ–Њ—Б—В—М—О, –≤ —Б–ї—Г—З–∞–µ —Б–±–Њ—П —Ж–µ–ї–Њ—Б—В–љ–Њ—Б—В—М –±–∞–Ј—Л –±—Г–і–µ—В –љ–∞—А—Г—И–µ–љ–∞, –Є –µ—С –њ—А–Є–і—С—В—Б—П –≤–Њ—Б—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М –Є–Ј —А–µ–Ј–µ—А–≤–љ–Њ–є –Ї–Њ–њ–Є–Є!–Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —Н—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А —А–µ–Ї–Њ–Љ–µ–љ–і—Г–µ—В—Б—П –ї–Є—И—М –≤ —В–Њ–Љ —Б–ї—Г—З–∞–µ, –µ—Б–ї–Є –≤—Л –≤—Б–µ—Ж–µ–ї–Њ –і–Њ–≤–µ—А—П–µ—В–µ —Б–≤–Њ–µ–Љ—Г «–ґ–µ–ї–µ–Ј—Г» –Є —Б–≤–Њ–µ–Љ—Г –Є—Б—В–Њ—З–љ–Є–Ї—Г –±–µ—Б–њ–µ—А–µ–±–Њ–є–љ–Њ–≥–Њ –њ–Є—В–∞–љ–Є—П. –Э—Г –Є–ї–Є –µ—Б–ї–Є –і–∞–љ–љ—Л–µ –≤ –±–∞–Ј–µ –љ–µ –њ—А–µ–і—Б—В–∞–≤–ї—П—О—В –і–ї—П –≤–∞—Б –Њ—Б–Њ–±–Њ–є —Ж–µ–љ–љ–Њ—Б—В–Є.
3 –Я—А–Њ—З–Є–µ –љ–∞—Б—В—А–Њ–є–Ї–Є
- commit_delay (–≤ –Љ–Є–Ї—А–Њ—Б–µ–Ї—Г–љ–і–∞—Е, 0 –њ–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О) –Є commit_siblings (5 –њ–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О)
–Њ–њ—А–µ–і–µ–ї—П—О—В –Ј–∞–і–µ—А–ґ–Ї—Г –Љ–µ–ґ–і—Г –њ–Њ–њ–∞–і–∞–љ–Є–µ–Љ –Ј–∞–њ–Є—Б–Є –≤ –±—Г—Д–µ—А –ґ—Г—А–љ–∞–ї–∞ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –Є —Б–±—А–Њ—Б–Њ–Љ –µ—С –љ–∞ –і–Є—Б–Ї. –Х—Б–ї–Є –њ—А–Є —Г—Б–њ–µ—И–љ–Њ–Љ –Ј–∞–≤–µ—А—И–µ–љ–Є–Є —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є –∞–Ї—В–Є–≤–љ–Њ –љ–µ –Љ–µ–љ–µ–µ commit_siblings —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є, —В–Њ –Ј–∞–њ–Є—Б—М –±—Г–і–µ—В –Ј–∞–і–µ—А–ґ–∞–љ–∞ –љ–∞ –≤—А–µ–Љ—П commit_delay. –Х—Б–ї–Є –Ј–∞ —Н—В–Њ –≤—А–µ–Љ—П –Ј–∞–≤–µ—А—И–Є—В—Б—П –і—А—Г–≥–∞—П —В—А–∞–љ–Ј–∞–Ї—Ж–Є—П, —В–Њ –Є—Е –Є–Ј–Љ–µ–љ–µ–љ–Є—П –±—Г–і—Г—В —Б–±—А–Њ—И–µ–љ—Л –љ–∞ –і–Є—Б–Ї –≤–Љ–µ—Б—В–µ, –њ—А–Є –њ–Њ–Љ–Њ—Й–Є –Њ–і–љ–Њ–≥–Њ —Б–Є—Б—В–µ–Љ–љ–Њ–≥–Њ –≤—Л–Ј–Њ–≤–∞. –≠—В–Є –њ–∞—А–∞–Љ–µ—В—А—Л –њ–Њ–Ј–≤–Њ–ї—П—В —Г—Б–Ї–Њ—А–Є—В—М —А–∞–±–Њ—В—Г, –µ—Б–ї–Є –њ–∞—А–∞–ї–ї–µ–ї—М–љ–Њ –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П –Љ–љ–Њ–≥–Њ «–Љ–µ–ї–Ї–Є—Е» —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є.
- wal_sync_method
–Ь–µ—В–Њ–і, –Ї–Њ—В–Њ—А—Л–є –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –і–ї—П –њ—А–Є–љ—Г–і–Є—В–µ–ї—М–љ–Њ–є –Ј–∞–њ–Є—Б–Є –і–∞–љ–љ—Л—Е –љ–∞ –і–Є—Б–Ї. –Х—Б–ї–Є fsync=off, —В–Њ —Н—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А –љ–µ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П. –Т–Њ–Ј–Љ–Њ–ґ–љ—Л–µ –Ј–љ–∞—З–µ–љ–Є—П:
- open_datasync -- –Ј–∞–њ–Є—Б—М –і–∞–љ–љ—Л—Е –Љ–µ—В–Њ–і–Њ–Љ open() —Б –њ–∞—А–∞–Љ–µ—В—А–Њ–Љ O_DSYNC
- fdatasync -- –≤—Л–Ј–Њ–≤ –Љ–µ—В–Њ–і–∞ fdatasync() –њ–Њ—Б–ї–µ –Ї–∞–ґ–і–Њ–≥–Њ commit
- fsync_writethrough -- –≤—Л–Ј—Л–≤–∞—В—М fsync() –њ–Њ—Б–ї–µ –Ї–∞–ґ–і–Њ–≥–Њ commit –Є–≥–љ–Њ—А–Є—А—Г—О –њ–∞—А–∞–ї–µ–ї—М–љ—Л–µ –њ—А–Њ—Ж–µ—Б—Б—Л
- fsync -- –≤—Л–Ј–Њ–≤ fsync() –њ–Њ—Б–ї–µ –Ї–∞–ґ–і–Њ–≥–Њ commit
- open_sync -- –Ј–∞–њ–Є—Б—М –і–∞–љ–љ—Л—Е –Љ–µ—В–Њ–і–Њ–Љ open() —Б –њ–∞—А–∞–Љ–µ—В—А–Њ–Љ O_SYNC
–Э–µ –≤—Б–µ —Н—В–Є –Љ–µ—В–Њ–і—Л –і–Њ—Б—В—Г–њ–љ—Л –љ–∞ —А–∞–Ј–љ—Л—Е –Ю–°. –Я–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ—В—Б—П –њ–µ—А–≤—Л–є, –Ї–Њ—В–Њ—А—Л–є –і–Њ—Б—В—Г–њ–µ–љ –і–ї—П —Б–Є—Б—В–µ–Љ—Л.
- full_page_writes
–£—Б—В–∞–љ–Њ–≤–Є—В–µ –і–∞–љ–љ—Л–є –њ–∞—А–∞–Љ–µ—В—А –≤ off, –µ—Б–ї–Є fsync=off. –Ш–љ–∞—З–µ, –Ї–Њ–≥–і–∞ —Н—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А on, PostgreSQL –Ј–∞–њ–Є—Б—Л–≤–∞–µ—В —Б–Њ–і–µ—А–ґ–Є–Љ–Њ–µ –Ї–∞–ґ–і–Њ–є –Ј–∞–њ–Є—Б–Є –≤ –ґ—Г—А–љ–∞–ї —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –њ—А–Є –њ–µ—А–≤–Њ–є –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–Є —В–∞–±–ї–Є—Ж—Л. –≠—В–Њ –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ, –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г –і–∞–љ–љ—Л–µ –Љ–Њ–≥—Г—В –Ј–∞–њ–Є—Б–∞—В—М—Б—П –ї–Є—И—М —З–∞—Б—В–Є—З–љ–Њ, –µ—Б–ї–Є –≤ —Е–Њ–і–µ –њ—А–Њ—Ж–µ—Б—Б–∞ «—Г–њ–∞–ї–∞» –Ю–°. –≠—В–Њ –њ—А–Є–≤–µ–і–µ—В –Ї —В–Њ–Љ—Г, —З—В–Њ –љ–∞ –і–Є—Б–Ї–µ –Њ–Ї–∞–ґ—Г—В—Б—П –љ–Њ–≤—Л–µ –і–∞–љ–љ—Л–µ —Б–Љ–µ—И–∞–љ–љ—Л–µ —Б–Њ —Б—В–∞—А—Л–Љ–Є. –°—В—А–Њ–Ї–Њ–≤–Њ–≥–Њ —Г—А–Њ–≤–љ—П –Ј–∞–њ–Є—Б–Є –≤ –ґ—Г—А–љ–∞–ї —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –Љ–Њ–ґ–µ—В –±—Л—В—М –љ–µ –і–Њ—Б—В–∞—В–Њ—З–љ–Њ, —З—В–Њ –±—Л –њ–Њ–ї–љ–Њ—Б—В—М –≤–Њ—Б—Б—В–∞–љ–Њ–≤–Є—В—М –і–∞–љ–љ—Л–µ –њ–Њ—Б–ї–µ «–њ–∞–і–µ–љ–Є—П». full_page_writes –≥–∞—А–∞–љ—В–Є—А—Г–µ—В –Ї–Њ—А—А–µ–Ї—В–љ–Њ–µ –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ, —Ж–µ–љ–Њ–є —Г–≤–µ–ї–µ—З–µ–љ–Є—П –Ј–∞–њ–Є—Б—Л–≤–∞–µ–Љ—Л—Е –і–∞–љ–љ—Л—Е –≤ –ґ—Г—А–љ–∞–ї —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є (–Х–і–Є–љ—Б—В–≤–µ–љ–љ—Л–є —Б–њ–Њ—Б–Њ–± —Б–љ–Є–ґ–µ–љ–Є—П –Њ–±—К–µ–Љ–∞ –Ј–∞–њ–Є—Б–Є –≤ –ґ—Г—А–љ–∞–ї —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –Ј–∞–Ї–ї—О—З–∞–µ—В—Б—П –≤ —Г–≤–µ–ї–Є—З–µ–љ–Є–Є checkpoint_interval).
- wal_buffers
–Ъ–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ–∞–Љ—П—В–Є –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ–Њ–µ –≤ SHARED MEMORY –і–ї—П –≤–µ–і–µ–љ–Є—П —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Њ–љ–љ—Л—Е –ї–Њ–≥–Њ–≤3. –°—В–Њ–Є—В —Г–≤–µ–ї–Є—З–Є—В—М –±—Г—Д–µ—А –і–Њ 256-512 –Ї–С, —З—В–Њ –њ–Њ–Ј–≤–Њ–ї–Є—В –ї—Г—З—И–µ —А–∞–±–Њ—В–∞—В—М —Б –±–Њ–ї—М—И–Є–Љ–Є —В—А–∞–љ–Ј–∞–Ї—Ж–Є—П–Љ–Є. –Э–∞–њ—А–Є–Љ–µ—А, –њ—А–Є –і–Њ—Б—В—Г–њ–љ–Њ–є –њ–∞–Љ—П—В–Є 1-4 –У–С —А–µ–Ї–Њ–Љ–µ–љ–і—Г–µ—В—Б—П —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М 256-1024 –Ъ–С.
3 –Я–ї–∞–љ–Є—А–Њ–≤—Й–Є–Ї –Ј–∞–њ—А–Њ—Б–Њ–≤
–°–ї–µ–і—Г—О—Й–Є–µ –љ–∞—Б—В—А–Њ–є–Ї–Є –њ–Њ–Љ–Њ–≥–∞—О—В –њ–ї–∞–љ–Є—А–Њ–≤—Й–Є–Ї—Г –Ј–∞–њ—А–Њ—Б–Њ–≤ –њ—А–∞–≤–Є–ї—М–љ–Њ –Њ—Ж–µ–љ–Є–≤–∞—В—М —Б—В–Њ–Є–Љ–Њ—Б—В–Є —А–∞–Ј–ї–Є—З–љ—Л—Е –Њ–њ–µ—А–∞—Ж–Є–є –Є –≤—Л–±–Є—А–∞—В—М –Њ–њ—В–Є–Љ–∞–ї—М–љ—Л–є –њ–ї–∞–љ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Ј–∞–њ—А–Њ—Б–∞. –°—Г—Й–µ—Б—В–≤—Г—О—В 3 –љ–∞—Б—В—А–Њ–є–Ї–Є –њ–ї–∞–љ–Є—А–Њ–≤—Й–Є–Ї–∞, –љ–∞ –Ї–Њ—В–Њ—А—Л–µ —Б—В–Њ–Є—В –Њ–±—А–∞—В–Є—В—М –≤–љ–Є–Љ–∞–љ–Є–µ:- default_statistics_target
–≠—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А –Ј–∞–і–∞—С—В –Њ–±—К—С–Љ —Б—В–∞—В–Є—Б—В–Є–Ї–Є, —Б–Њ–±–Є—А–∞–µ–Љ–Њ–є –Ї–Њ–Љ–∞–љ–і–Њ–є ANALYZE (—Б–Љ. –њ—Г–љ–Ї—В 3.1.2). –£–≤–µ–ї–Є—З–µ–љ–Є–µ –њ–∞—А–∞–Љ–µ—В—А–∞ –Ј–∞—Б—В–∞–≤–Є—В —Н—В—Г –Ї–Њ–Љ–∞–љ–і—Г —А–∞–±–Њ—В–∞—В—М –і–Њ–ї—М—И–µ, –љ–Њ –Љ–Њ–ґ–µ—В –њ–Њ–Ј–≤–Њ–ї–Є—В—М –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А—Г —Б—В—А–Њ–Є—В—М –±–Њ–ї–µ–µ –±—Л—Б—В—А—Л–µ –њ–ї–∞–љ—Л, –Є—Б–њ–Њ–ї—М–Ј—Г—П –њ–Њ–ї—Г—З–µ–љ–љ—Л–µ –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л–µ –і–∞–љ–љ—Л–µ. –Ю–±—К—С–Љ —Б—В–∞—В–Є—Б—В–Є–Ї–Є –і–ї—П –Ї–Њ–љ–Ї—А–µ—В–љ–Њ–≥–Њ –њ–Њ–ї—П –Љ–Њ–ґ–µ—В –±—Л—В—М –Ј–∞–і–∞–љ –Ї–Њ–Љ–∞–љ–і–Њ–є ALTER TABLE ...SET STATISTICS.
- effective_cache_size
–≠—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А —Б–Њ–Њ–±—Й–∞–µ—В PostgreSQL –њ—А–Є–Љ–µ—А–љ—Л–є –Њ–±—К—С–Љ —Д–∞–є–ї–Њ–≤–Њ–≥–Њ –Ї—Н—И–∞ –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–Њ–є —Б–Є—Б—В–µ–Љ—Л, –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В —Н—В—Г –Њ—Ж–µ–љ–Ї—Г –і–ї—П –њ–Њ—Б—В—А–Њ–µ–љ–Є—П –њ–ї–∞–љ–∞ –Ј–∞–њ—А–Њ—Б–∞4.
–Я—Г—Б—В—М –≤ –≤–∞—И–µ–Љ –Ї–Њ–Љ–њ—М—О—В–µ—А–µ 1,5 –У–С –њ–∞–Љ—П—В–Є, –њ–∞—А–∞–Љ–µ—В—А shared_buffers —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ –≤ 32 –Ь–С, –∞ –њ–∞—А–∞–Љ–µ—В—А effective_cache_size –≤ 800 –Ь–С. –Х—Б–ї–Є –Ј–∞–њ—А–Њ—Б—Г –љ—Г–ґ–љ–Њ 700 –Ь–С –і–∞–љ–љ—Л—Е, —В–Њ PostgreSQL –Њ—Ж–µ–љ–Є—В, —З—В–Њ –≤—Б–µ –љ—Г–ґ–љ—Л–µ –і–∞–љ–љ—Л–µ —Г–ґ–µ –µ—Б—В—М –≤ –њ–∞–Љ—П—В–Є –Є –≤—Л–±–µ—А–µ—В –±–Њ–ї–µ–µ –∞–≥—А–µ—Б—Б–Є–≤–љ—Л–є –њ–ї–∞–љ —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ –Є–љ–і–µ–Ї—Б–Њ–≤ –Є merge joins. –Э–Њ –µ—Б–ї–Є effective_cache_size –±—Г–і–µ—В –≤—Б–µ–≥–Њ 200 –Ь–С, —В–Њ –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А –≤–њ–Њ–ї–љ–µ –Љ–Њ–ґ–µ—В –≤—Л–±—А–∞—В—М –±–Њ–ї–µ–µ —Н—Д—Д–µ–Ї—В–Є–≤–љ—Л–є –і–ї—П –і–Є—Б–Ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л –њ–ї–∞–љ, –≤–Ї–ї—О—З–∞—О—Й–Є–є –њ–Њ–ї–љ—Л–є –њ—А–Њ—Б–Љ–Њ—В—А —В–∞–±–ї–Є—Ж—Л.
–Э–∞ –≤—Л–і–µ–ї–µ–љ–љ–Њ–Љ —Б–µ—А–≤–µ—А–µ –Є–Љ–µ–µ—В —Б–Љ—Л—Б–ї –≤—Л—Б—В–∞–≤–ї—П—В—М effective_cache_size –≤ 2/3 –Њ—В –≤—Б–µ–є –Њ–њ–µ—А–∞—В–Є–≤–љ–Њ–є –њ–∞–Љ—П—В–Є; –љ–∞ —Б–µ—А–≤–µ—А–µ —Б –і—А—Г–≥–Є–Љ–Є –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П–Љ–Є —Б–љ–∞—З–∞–ї–∞ –љ—Г–ґ–љ–Њ –≤—Л—З–µ—Б—В—М –Є–Ј –≤—Б–µ–≥–Њ –Њ–±—К–µ–Љ–∞ RAM —А–∞–Ј–Љ–µ—А –і–Є—Б–Ї–Њ–≤–Њ–≥–Њ –Ї—Н—И–∞ –Ю–° –Є –њ–∞–Љ—П—В—М, –Ј–∞–љ—П—В—Г—О –Њ—Б—В–∞–ї—М–љ—Л–Љ–Є –њ—А–Њ—Ж–µ—Б—Б–∞–Љ–Є.
- random_page_cost
–Я–µ—А–µ–Љ–µ–љ–љ–∞—П, —Г–Ї–∞–Ј—Л–≤–∞—О—Й–∞—П –љ–∞ —Г—Б–ї–Њ–≤–љ—Г—О —Б—В–Њ–Є–Љ–Њ—Б—В—М –Є–љ–і–µ–Ї—Б–љ–Њ–≥–Њ –і–Њ—Б—В—Г–њ–∞ –Ї —Б—В—А–∞–љ–Є—Ж–∞–Љ –і–∞–љ–љ—Л—Е. –Э–∞ —Б–µ—А–≤–µ—А–∞—Е —Б –±—Л—Б—В—А—Л–Љ–Є –і–Є—Б–Ї–Њ–≤—Л–Љ–Є –Љ–∞—Б—Б–Є–≤–∞–Љ–Є –Є–Љ–µ–µ—В —Б–Љ—Л—Б–ї —Г–Љ–µ–љ—М—И–∞—В—М –Є–Ј–љ–∞—З–∞–ї—М–љ—Г—О –љ–∞—Б—В—А–Њ–є–Ї—Г –і–Њ 3.0, 2.5 –Є–ї–Є –і–∞–ґ–µ –і–Њ 2.0. –Х—Б–ї–Є –ґ–µ –∞–Ї—В–Є–≤–љ–∞—П —З–∞—Б—В—М –≤–∞—И–µ–є –±–∞–Ј—Л –і–∞–љ–љ—Л—Е –љ–∞–Љ–љ–Њ–≥–Њ –±–Њ–ї—М—И–µ —А–∞–Ј–Љ–µ—А–Њ–≤ –Њ–њ–µ—А–∞—В–Є–≤–љ–Њ–є –њ–∞–Љ—П—В–Є, –њ–Њ–њ—А–Њ–±—Г–є—В–µ –њ–Њ–і–љ—П—В—М –Ј–љ–∞—З–µ–љ–Є–µ –њ–∞—А–∞–Љ–µ—В—А–∞. –Ь–Њ–ґ–љ–Њ –њ–Њ–і–Њ–є—В–Є –Ї –≤—Л–±–Њ—А—Г –Њ–њ—В–Є–Љ–∞–ї—М–љ–Њ–≥–Њ –Ј–љ–∞—З–µ–љ–Є—П –Є —Б–Њ —Б—В–Њ—А–Њ–љ—Л –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є –Ј–∞–њ—А–Њ—Б–Њ–≤. –Х—Б–ї–Є –њ–ї–∞–љ–Є—А–Њ–≤—Й–Є–Ї –Ј–∞–њ—А–Њ—Б–Њ–≤ —З–∞—Й–µ, —З–µ–Љ –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ, –њ—А–µ–і–њ–Њ—З–Є—В–∞–µ—В –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ—Л–µ –њ—А–Њ—Б–Љ–Њ—В—А—Л (sequential scans) –њ—А–Њ—Б–Љ–Њ—В—А–∞–Љ —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ –Є–љ–і–µ–Ї—Б–∞ (index scans), –њ–Њ–љ–Є–ґ–∞–є—В–µ –Ј–љ–∞—З–µ–љ–Є–µ. –Ш –љ–∞–Њ–±–Њ—А–Њ—В, –µ—Б–ї–Є –њ–ї–∞–љ–Є—А–Њ–≤—Й–Є–Ї –≤—Л–±–Є—А–∞–µ—В –њ—А–Њ—Б–Љ–Њ—В—А –њ–Њ –Љ–µ–і–ї–µ–љ–љ–Њ–Љ—Г –Є–љ–і–µ–Ї—Б—Г, –Ї–Њ–≥–і–∞ –љ–µ –і–Њ–ї–ґ–µ–љ —Н—В–Њ–≥–Њ –і–µ–ї–∞—В—М, –љ–∞—Б—В—А–Њ–є–Ї—Г –Є–Љ–µ–µ—В —Б–Љ—Л—Б–ї —Г–≤–µ–ї–Є—З–Є—В—М. –Я–Њ—Б–ї–µ –Є–Ј–Љ–µ–љ–µ–љ–Є—П —В—Й–∞—В–µ–ї—М–љ–Њ —В–µ—Б—В–Є—А—Г–є—В–µ —А–µ–Ј—Г–ї—М—В–∞—В—Л –љ–∞ –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ —И–Є—А–Њ–Ї–Њ–Љ –љ–∞–±–Њ—А–µ –Ј–∞–њ—А–Њ—Б–Њ–≤. –Э–Є–Ї–Њ–≥–і–∞ –љ–µ –Њ–њ—Г—Б–Ї–∞–є—В–µ –Ј–љ–∞—З–µ–љ–Є–µ random_page_cost –љ–Є–ґ–µ 2.0; –µ—Б–ї–Є –≤–∞–Љ –Ї–∞–ґ–µ—В—Б—П, —З—В–Њ random_page_cost –љ—Г–ґ–љ–Њ –µ—Й–µ –њ–Њ–љ–Є–ґ–∞—В—М, —А–∞–Ј—Г–Љ–љ–µ–µ –≤ —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ –Љ–µ–љ—П—В—М –љ–∞—Б—В—А–Њ–є–Ї–Є —Б—В–∞—В–Є—Б—В–Є–Ї–Є –њ–ї–∞–љ–Є—А–Њ–≤—Й–Є–Ї–∞.
4 –°–±–Њ—А —Б—В–∞—В–Є—Б—В–Є–Ї–Є
–£ PostgreSQL —В–∞–Ї–ґ–µ –µ—Б—В—М —Б–њ–µ—Ж–Є–∞–ї—М–љ–∞—П –њ–Њ–і—Б–Є—Б—В–µ–Љ–∞ -- —Б–±–Њ—А—Й–Є–Ї —Б—В–∞—В–Є—Б—В–Є–Ї–Є, -- –Ї–Њ—В–Њ—А–∞—П –≤ —А–µ–∞–ї—М–љ–Њ–Љ –≤—А–µ–Љ–µ–љ–Є —Б–Њ–±–Є—А–∞–µ—В –і–∞–љ–љ—Л–µ –Њ–± –∞–Ї—В–Є–≤–љ–Њ—Б—В–Є —Б–µ—А–≤–µ—А–∞. –Я–Њ—Б–Ї–Њ–ї—М–Ї—Г —Б–±–Њ—А —Б—В–∞—В–Є—Б—В–Є–Ї–Є —Б–Њ–Ј–і–∞–µ—В –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л–µ –љ–∞–Ї–ї–∞–і–љ—Л–µ —А–∞—Б—Е–Њ–і—Л –љ–∞ –±–∞–Ј—Г –і–∞–љ–љ—Л—Е, —В–Њ —Б–Є—Б—В–µ–Љ–∞ –Љ–Њ–ґ–µ—В –±—Л—В—М –љ–∞—Б—В—А–Њ–µ–љ–∞ –Ї–∞–Ї –љ–∞ —Б–±–Њ—А, —В–∞–Ї –Є –љ–µ —Б–±–Њ—А —Б—В–∞—В–Є—Б—В–Є–Ї–Є –≤–Њ–Њ–±—Й–µ. –≠—В–∞ —Б–Є—Б—В–µ–Љ–∞ –Ї–Њ–љ—В—А–Њ–ї–Є—А—Г–µ—В—Б—П —Б–ї–µ–і—Г—О—Й–Є–Љ–Є –њ–∞—А–∞–Љ–µ—В—А–∞–Љ–Є, –њ—А–Є–љ–Є–Љ–∞—О—Й–Є–Љ–Є –Ј–љ–∞—З–µ–љ–Є—П true/false:- track_counts –≤–Ї–ї—О—З–∞—В—М –ї–Є —Б–±–Њ—А —Б—В–∞—В–Є—Б—В–Є–Ї–Є. –Я–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О –≤–Ї–ї—О—З—С–љ, –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г autovacuum –і–µ–Љ–Њ–љ—Г —В—А–µ–±—Г–µ—В—Б—П —Б–±–Њ—А —Б—В–∞—В–Є—Б—В–Є–Ї–Є. –Ю—В–Ї–ї—О—З–∞–є—В–µ, —В–Њ–ї—М–Ї–Њ –µ—Б–ї–Є —Б—В–∞—В–Є—Б—В–Є–Ї–∞ –≤–∞—Б —Б–Њ–≤–µ—А—И–µ–љ–љ–Њ –љ–µ –Є–љ—В–µ—А–µ—Б—Г–µ—В (–Ї–∞–Ї –Є autovacuum).
- track_functions –Њ—В—Б–ї–µ–ґ–Є–≤–∞–љ–Є–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П –Њ–њ—А–µ–і–µ–ї–µ–љ–љ—Л—Е –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–Љ —Д—Г–љ–Ї—Ж–Є–є.
- track_activities –њ–µ—А–µ–і–∞–≤–∞—В—М –ї–Є —Б–±–Њ—А—Й–Є–Ї—Г —Б—В–∞—В–Є—Б—В–Є–Ї–Є –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—О –Њ —В–µ–Ї—Г—Й–µ–є –≤—Л–њ–Њ–ї–љ—П–µ–Љ–Њ–є –Ї–Њ–Љ–∞–љ–і–µ –Є –≤—А–µ–Љ–µ–љ–Є –љ–∞—З–∞–ї–∞ –µ—С –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П. –Я–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О —Н—В–∞ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –≤–Ї–ї—О—З–µ–љ–∞. –°–ї–µ–і—Г–µ—В –Њ—В–Љ–µ—В–Є—В—М, —З—В–Њ —Н—В–∞ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –±—Г–і–µ—В –і–Њ—Б—В—Г–њ–љ–∞ —В–Њ–ї—М–Ї–Њ –њ—А–Є–≤–Є–ї–µ–≥–Є—А–Њ–≤–∞–љ–љ—Л–Љ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П–Љ –Є –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П–Љ, –Њ—В –ї–Є—Ж–∞ –Ї–Њ—В–Њ—А—Л—Е –Ј–∞–њ—Г—Й–µ–љ—Л –Ї–Њ–Љ–∞–љ–і—Л, —В–∞–Ї —З—В–Њ –њ—А–Њ–±–ї–µ–Љ —Б –±–µ–Ј–Њ–њ–∞—Б–љ–Њ—Б—В—М—О –±—Л—В—М –љ–µ –і–Њ–ї–ґ–љ–Њ.
–Ф–∞–љ–љ—Л–µ, –њ–Њ–ї—Г—З–µ–љ–љ—Л–µ —Б–±–Њ—А—Й–Є–Ї–Њ–Љ —Б—В–∞—В–Є—Б—В–Є–Ї–Є, –і–Њ—Б—В—Г–њ–љ—Л —З–µ—А–µ–Ј —Б–њ–µ—Ж–Є–∞–ї—М–љ—Л–µ —Б–Є—Б—В–µ–Љ–љ—Л–µ –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–Є—П. –Я—А–Є —Г—Б—В–∞–љ–Њ–≤–Ї–∞—Е –њ–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О —Б–Њ–±–Є—А–∞–µ—В—Б—П –Њ—З–µ–љ—М –Љ–∞–ї–Њ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Є, —А–µ–Ї–Њ–Љ–µ–љ–і—Г–µ—В—Б—П –≤–Ї–ї—О—З–Є—В—М –≤—Б–µ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є: –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ–∞—П –љ–∞–≥—А—Г–Ј–Ї–∞ –±—Г–і–µ—В –љ–µ–≤–µ–ї–Є–Ї–∞, –≤ —В–Њ –≤—А–µ–Љ—П –Ї–∞–Ї –њ–Њ–ї—Г—З–µ–љ–љ—Л–µ –і–∞–љ–љ—Л–µ –њ–Њ–Ј–≤–Њ–ї—П—В –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞—В—М –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –Є–љ–і–µ–Ї—Б–Њ–≤ (–∞ —В–∞–Ї–ґ–µ –њ–Њ–Љ–Њ–≥—Г—В –Њ–њ—В–Є–Љ–∞–ї—М–љ–Њ–є —А–∞–±–Њ—В–µ autovacuum –і–µ–Љ–Њ–љ—Г).
3 –Ф–Є—Б–Ї–Є –Є —Д–∞–є–ї–Њ–≤—Л–µ —Б–Є—Б—В–µ–Љ—Л
–Ю—З–µ–≤–Є–і–љ–Њ, —З—В–Њ –Њ—В –Ї–∞—З–µ—Б—В–≤–µ–љ–љ–Њ–є –і–Є—Б–Ї–Њ–≤–Њ–є –њ–Њ–і—Б–Є—Б—В–µ–Љ—Л –≤ —Б–µ—А–≤–µ—А–µ –С–Ф –Ј–∞–≤–Є—Б–Є—В –љ–µ–Љ–∞–ї–∞—П —З–∞—Б—В—М –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є. –Т–Њ–њ—А–Њ—Б—Л –≤—Л–±–Њ—А–∞ –Є —В–Њ–љ–Ї–Њ–є –љ–∞—Б—В—А–Њ–є–Ї–Є «–ґ–µ–ї–µ–Ј–∞», –≤–њ—А–Њ—З–µ–Љ, –љ–µ —П–≤–ї—П—О—В—Б—П —В–µ–Љ–Њ–є –і–∞–љ–љ–Њ–є —Б—В–∞—В—М–Є, –Њ–≥—А–∞–љ–Є—З–Є–Љ—Б—П —Г—А–Њ–≤–љ–µ–Љ —Д–∞–є–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л.–Х–і–Є–љ–Њ–≥–Њ –Љ–љ–µ–љ–Є—П –љ–∞—Б—З—С—В –љ–∞–Є–±–Њ–ї–µ–µ –њ–Њ–і—Е–Њ–і—П—Й–µ–є –і–ї—П PostgreSQL —Д–∞–є–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л –љ–µ—В, –њ–Њ—Н—В–Њ–Љ—Г —А–µ–Ї–Њ–Љ–µ–љ–і—Г–µ—В—Б—П –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —В—Г, –Ї–Њ—В–Њ—А–∞—П –ї—Г—З—И–µ –≤—Б–µ–≥–Њ –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В—Б—П –≤–∞—И–µ–є –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–Њ–є —Б–Є—Б—В–µ–Љ–Њ–є. –Я—А–Є —Н—В–Њ–Љ —Г—З—В–Є—В–µ, —З—В–Њ —Б–Њ–≤—А–µ–Љ–µ–љ–љ—Л–µ –ґ—Г—А–љ–∞–ї–Є—А—Г—О—Й–Є–µ —Д–∞–є–ї–Њ–≤—Л–µ —Б–Є—Б—В–µ–Љ—Л –љ–µ –љ–∞–Љ–љ–Њ–≥–Њ –Љ–µ–і–ї–µ–љ–љ–µ–µ –љ–µ–ґ—Г—А–љ–∞–ї–Є—А—Г—О—Й–Є—Е, –∞ –≤—Л–Є–≥—А—Л—И -- –±—Л—Б—В—А–Њ–µ –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ –њ–Њ—Б–ї–µ —Б–±–Њ–µ–≤ -- –Њ—В –Є—Е –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П –≤–µ–ї–Є–Ї.
–Т—Л –ї–µ–≥–Ї–Њ –Љ–Њ–ґ–µ—В–µ –њ–Њ–ї—Г—З–Є—В—М –≤—Л–Є–≥—А—Л—И –≤ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є –±–µ–Ј –њ–Њ–±–Њ—З–љ—Л—Е —Н—Д—Д–µ–Ї—В–Њ–≤, –µ—Б–ї–Є –њ—А–Є–Љ–Њ–љ—В–Є—А—Г–µ—В–µ —Д–∞–є–ї–Њ–≤—Г—О —Б–Є—Б—В–µ–Љ—Г, —Б–Њ–і–µ—А–ґ–∞—Й—Г—О –±–∞–Ј—Г –і–∞–љ–љ—Л—Е, —Б –њ–∞—А–∞–Љ–µ—В—А–Њ–Љ noatime5.
1 –Я–µ—А–µ–љ–Њ—Б –ґ—Г—А–љ–∞–ї–∞ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –љ–∞ –Њ—В–і–µ–ї—М–љ—Л–є –і–Є—Б–Ї
–Я—А–Є –і–Њ—Б—В—Г–њ–µ –Ї –і–Є—Б–Ї—Г –Є–Ј—А—П–і–љ–Њ–µ –≤—А–µ–Љ—П –Ј–∞–љ–Є–Љ–∞–µ—В –љ–µ —В–Њ–ї—М–Ї–Њ —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ —З—В–µ–љ–Є–µ –і–∞–љ–љ—Л—Е, –љ–Њ –Є –њ–µ—А–µ–Љ–µ—Й–µ–љ–Є–µ –Љ–∞–≥–љ–Є—В–љ–Њ–є –≥–Њ–ї–Њ–≤–Ї–Є.–Х—Б–ї–Є –≤ –≤–∞—И–µ–Љ —Б–µ—А–≤–µ—А–µ –µ—Б—В—М –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ —Д–Є–Ј–Є—З–µ—Б–Ї–Є—Е –і–Є—Б–Ї–Њ–≤6, —В–Њ –≤—Л –Љ–Њ–ґ–µ—В–µ —А–∞–Ј–љ–µ—Б—В–Є —Д–∞–є–ї—Л –±–∞–Ј—Л –і–∞–љ–љ—Л—Е –Є –ґ—Г—А–љ–∞–ї —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –њ–Њ —А–∞–Ј–љ—Л–Љ –і–Є—Б–Ї–∞–Љ. –Ф–∞–љ–љ—Л–µ –≤ —Б–µ–≥–Љ–µ–љ—В—Л –ґ—Г—А–љ–∞–ї–∞ –њ–Є—И—Г—В—Б—П –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ–Њ, –±–Њ–ї–µ–µ —В–Њ–≥–Њ, –Ј–∞–њ–Є—Б–Є –≤ –ґ—Г—А–љ–∞–ї–µ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є —Б—А–∞–Ј—Г —Б–±—А–∞—Б—Л–≤–∞—О—В—Б—П –љ–∞ –і–Є—Б–Ї, –њ–Њ—Н—В–Њ–Љ—Г –≤ —Б–ї—Г—З–∞–µ –љ–∞—Е–Њ–ґ–і–µ–љ–Є—П –µ–≥–Њ –љ–∞ –Њ—В–і–µ–ї—М–љ–Њ–Љ –і–Є—Б–Ї–µ –Љ–∞–≥–љ–Є—В–љ–∞—П –≥–Њ–ї–Њ–≤–Ї–∞ –љ–µ –±—Г–і–µ—В –ї–Є—И–љ–Є–є —А–∞–Ј –і–≤–Є–≥–∞—В—М—Б—П, —З—В–Њ –њ–Њ–Ј–≤–Њ–ї–Є—В —Г—Б–Ї–Њ—А–Є—В—М –Ј–∞–њ–Є—Б—М.
–Я–Њ—А—П–і–Њ–Ї –і–µ–є—Б—В–≤–Є–є:
- –Ю—Б—В–∞–љ–Њ–≤–Є—В–µ —Б–µ—А–≤–µ—А (!).
- –Я–µ—А–µ–љ–µ—Б–Є—В–µ –Ї–∞—В–∞–ї–Њ–≥–Є pg_clog –Є pg_xlog, –љ–∞—Е–Њ–і—П—Й–Є–є—Б—П –≤ –Ї–∞—В–∞–ї–Њ–≥–µ —Б –±–∞–Ј–∞–Љ–Є –і–∞–љ–љ—Л—Е, –љ–∞ –і—А—Г–≥–Њ–є –і–Є—Б–Ї.
- –°–Њ–Ј–і–∞–є—В–µ –љ–∞ —Б—В–∞—А–Њ–Љ –Љ–µ—Б—В–µ —Б–Є–Љ–≤–Њ–ї–Є—З–µ—Б–Ї—Г—О —Б—Б—Л–ї–Ї—Г.
- –Ч–∞–њ—Г—Б—В–Є—В–µ —Б–µ—А–≤–µ—А.
–Я—А–Є–Љ–µ—А–љ–Њ —В–∞–Ї–Є–Љ –ґ–µ –Њ–±—А–∞–Ј–Њ–Љ –Љ–Њ–ґ–љ–Њ –њ–µ—А–µ–љ–µ—Б—В–Є –Є —З–∞—Б—В—М —Д–∞–є–ї–Њ–≤, —Б–Њ–і–µ—А–ґ–∞—Й–Є—Е —В–∞–±–ї–Є—Ж—Л –Є –Є–љ–і–µ–Ї—Б—Л, –љ–∞ –і—А—Г–≥–Њ–є –і–Є—Б–Ї, –љ–Њ –Ј–і–µ—Б—М –њ–Њ—В—А–µ–±—Г–µ—В—Б—П –±–Њ–ї—М—И–µ –Ї—А–Њ–њ–Њ—В–ї–Є–≤–Њ–є —А—Г—З–љ–Њ–є —А–∞–±–Њ—В—Л, –∞ –њ—А–Є –≤–љ–µ—Б–µ–љ–Є–Є –Є–Ј–Љ–µ–љ–µ–љ–Є–є –≤ —Б—Е–µ–Љ—Г –±–∞–Ј—Л –њ—А–Њ—Ж–µ–і—Г—А—Г, –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ, –њ—А–Є–і—С—В—Б—П –њ–Њ–≤—В–Њ—А–Є—В—М.
4 –Я—А–Є–Љ–µ—А—Л –љ–∞—Б—В—А–Њ–µ–Ї
1 –°—А–µ–і–љ–µ—Б—В–∞—В–Є—Б—В–Є—З–µ—Б–Ї–∞—П –љ–∞—Б—В—А–Њ–є–Ї–∞ –і–ї—П –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–є –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є
–Т–Њ–Ј–Љ–Њ–ґ–љ–Њ –і–ї—П –Ї–Њ–љ–Ї—А–µ—В–љ–Њ–≥–Њ —Б–ї—Г—З–∞—О –ї—Г—З—И–µ –њ–Њ–і–Њ–є–і—Г—В –і—А—Г–≥–Є–µ –љ–∞—Б—В—А–Њ–є–Ї–Є. –Т–љ–Є–Љ–∞—В–µ–ї—М–љ–Њ –Є–Ј—Г—З–Є—В–µ –і–∞–љ–љ–Њ–µ —А—Г–Ї–Њ–≤–Њ–і—Б—В–≤–Њ –Є –љ–∞—Б—В—А–Њ–є—В–µ PostgreSQL –Њ–њ–µ—А–∞—П—Б—М –љ–∞ —Н—В—Г –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—О.
RAM -- —А–∞–Ј–Љ–µ—А –њ–∞–Љ—П—В–Є;
- shared_buffers = 1/8 RAM –Є–ї–Є –±–Њ–ї—М—И–µ (–љ–Њ –љ–µ –±–Њ–ї–µ–µ 1/4);
- work_mem –≤ 1/20 RAM;
- maintenance_work_mem –≤ 1/4 RAM;
- max_fsm_relations –≤ –њ–ї–∞–љ–Є—А—Г–µ–Љ–Њ–µ –Ї–Њ–ї-–≤–Њ —В–∞–±–ї–Є—Ж –≤ –±–∞–Ј–∞—Е * 1.5;
- max_fsm_pages –≤ max_fsm_relations * 2000;
- fsync = true;
- wal_sync_method = fdatasync;
- commit_delay = –Њ—В 10 –і–Њ 100 ;
- commit_siblings = –Њ—В 5 –і–Њ 10;
- effective_cache_size = 0.9 –Њ—В –Ј–љ–∞—З–µ–љ–Є—П cached, –Ї–Њ—В–Њ—А–Њ–µ –њ–Њ–Ї–∞–Ј—Л–≤–∞–µ—В free;
- random_page_cost = 2 –і–ї—П –±—Л—Б—В—А—Л—Е cpu, 4 –і–ї—П –Љ–µ–і–ї–µ–љ–љ—Л—Е;
- cpu_tuple_cost = 0.001 –і–ї—П –±—Л—Б—В—А—Л—Е cpu, 0.01 –і–ї—П –Љ–µ–і–ї–µ–љ–љ—Л—Е;
- cpu_index_tuple_cost = 0.0005 –і–ї—П –±—Л—Б—В—А—Л—Е cpu, 0.005 –і–ї—П –Љ–µ–і–ї–µ–љ–љ—Л—Е;
- autovacuum = on;
- autovacuum_vacuum_threshold = 1800;
- autovacuum_analyze_threshold = 900;
2 –°—А–µ–і–љ–µ—Б—В–∞—В–Є—Б—В–Є—З–µ—Б–Ї–∞—П –љ–∞—Б—В—А–Њ–є–Ї–∞ –і–ї—П –Њ–Ї–Њ–љ–љ–Њ–≥–Њ –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П (1–°), 2 –У–С –њ–∞–Љ—П—В–Є
- maintenance_work_mem = 128MB
- effective_cache_size = 512MB
- work_mem = 640kB
- wal_buffers = 1536kB
- shared_buffers = 128MB
- max_connections = 500
3 –°—А–µ–і–љ–µ—Б—В–∞—В–Є—Б—В–Є—З–µ—Б–Ї–∞—П –љ–∞—Б—В—А–Њ–є–Ї–∞ –і–ї—П Web –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П, 2 –У–С –њ–∞–Љ—П—В–Є
- maintenance_work_mem = 128MB;
- checkpoint_completion_target = 0.7
- effective_cache_size = 1536MB
- work_mem = 4MB
- wal_buffers = 4MB
- checkpoint_segments = 8
- shared_buffers = 512MB
- max_connections = 500
4 –°—А–µ–і–љ–µ—Б—В–∞—В–Є—Б—В–Є—З–µ—Б–Ї–∞—П –љ–∞—Б—В—А–Њ–є–Ї–∞ –і–ї—П Web –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П, 8 –У–С –њ–∞–Љ—П—В–Є
- maintenance_work_mem = 512MB
- checkpoint_completion_target = 0.7
- effective_cache_size = 6GB
- work_mem = 16MB
- wal_buffers = 4MB
- checkpoint_segments = 8
- shared_buffers = 2GB
- max_connections = 500
5 –Р–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Њ–µ —Б–Њ–Ј–і–∞–љ–Є–µ –Њ–њ—В–Є–Љ–∞–ї—М–љ—Л—Е –љ–∞—Б—В—А–Њ–µ–Ї: pgtune
–Ф–ї—П –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є–Є –љ–∞—Б—В—А–Њ–µ–Ї –і–ї—П PostgreSQL Gregory Smith —Б–Њ–Ј–і–∞–ї —Г—В–Є–ї–Є—В—Г pgtune7
–≤ —А–∞—Б—З–µ—В–µ –љ–∞ –Њ–±–µ—Б–њ–µ—З–µ–љ–Є–µ –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–є –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є –і–ї—П –Ј–∞–і–∞–љ–љ–Њ–є –∞–њ–њ–∞—А–∞—В–љ–Њ–є –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–Є.
–£—В–Є–ї–Є—В–∞ –њ—А–Њ—Б—В–∞ –≤ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–Є –Є –≤ –Љ–љ–Њ–≥–Є—Е Linux —Б–Є—Б—В–µ–Љ–∞—Е –Љ–Њ–ґ–µ—В –Є–і—В–Є –≤ —Б–Њ—Б—В–∞–≤–µ –њ–∞–Ї–µ—В–Њ–≤.
–Х—Б–ї–Є –ґ–µ –љ–µ—В, –Љ–Њ–ґ–љ–Њ –њ—А–Њ—Б—В–Њ —Б–Ї–∞—З–∞—В—М –∞—А—Е–Є–≤ –Є —А–∞—Б–њ–∞–Ї–Њ–≤–∞—В—М.
–Ф–ї—П –љ–∞—З–∞–ї–∞:
![\begin{lstlisting}[label=lst:p_settings1,caption=Pgtune]
pgtune -i $PGDATA/postgresql.conf \
-o $PGDATA/postgresql.conf.pgtune
\end{lstlisting}](postgresql-img3.png)
–Њ–њ—Ж–Є–µ–є
[frame=tblr]-i, -input-config
—Г–Ї–∞–Ј—Л–≤–∞–µ–Љ —В–µ–Ї—Г—Й–Є–є —Д–∞–є–ї postgresql.conf,
–∞
[frame=tblr]-o, -output-config
—Г–Ї–∞–Ј—Л–≤–∞–µ–Љ –Є–Љ—П —Д–∞–є–ї–∞ –і–ї—П –љ–Њ–≤–Њ–≥–Њ postgresql.conf.
–Х—Б—В—М —В–∞–Ї–ґ–µ –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л–µ –Њ–њ—Ж–Є–Є –і–ї—П –љ–∞—Б—В—А–Њ–є–Ї–Є –Ї–Њ–љ—Д–Є–≥–∞.
- [frame=single]-M, -memory
–Ш—Б–њ–Њ–ї—М–Ј—Г–є—В–µ —Н—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А, —З—В–Њ–±—Л –Њ–њ—А–µ–і–µ–ї–Є—В—М –Њ–±—Й–Є–є –Њ–±—К–µ–Љ —Б–Є—Б—В–µ–Љ–љ–Њ–є –њ–∞–Љ—П—В–Є.
–Х—Б–ї–Є –љ–µ —Г–Ї–∞–Ј–∞–љ–Њ, pgtune –±—Г–і–µ—В –њ—Л—В–∞—В—М—Б—П –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —В–µ–Ї—Г—Й–Є–є –Њ–±—К–µ–Љ —Б–Є—Б—В–µ–Љ–љ–Њ–є –њ–∞–Љ—П—В–Є.
- [frame=single]-T, -type
–£–Ї–∞–Ј—Л–≤–∞–µ—В —В–Є–њ –±–∞–Ј—Л –і–∞–љ–љ—Л—Е. –Ю–њ—Ж–Є–Є: DW, OLTP, Web, Mixed, Desktop.
- [frame=single]-c, -connections
–£–Ї–∞–Ј—Л–≤–∞–µ—В –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б–Њ–µ–і–Є–љ–µ–љ–Є–є. –Х—Б–ї–Є –Њ–љ –љ–µ —Г–Ї–∞–Ј–∞–љ, —Н—В–Њ –±—Г–і–µ—В –±—А–∞—В—Б—П –≤–Ј–∞–≤–Є—Б–Є–Љ–Њ—Б—В–Є –Њ—В —В–Є–њ–∞ –±–∞–Ј—Л –і–∞–љ–љ—Л—Е.
–•–Њ—З–µ—В—Б—П —Б—А–∞–Ј—Г –і–Њ–±–∞–≤–Є—В—М, —З—В–Њ pgtune –љ–µ –њ–∞–љ–∞—Ж–µ—П –і–ї—П –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є–Є –љ–∞—Б—В—А–Њ–є–Ї–Є PostgreSQL. –Ь–љ–Њ–≥–Є–µ –љ–∞—Б—В—А–Њ–є–Ї–Є –Ј–∞–≤–Є—Б—П—В –љ–µ —В–Њ–ї—М–Ї–Њ –Њ—В –∞–њ–њ–∞—А–∞—В–љ–Њ–є –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–Є, –љ–Њ –Є –Њ—В —А–∞–Ј–Љ–µ—А–∞ –±–∞–Ј—Л –і–∞–љ–љ—Л—Е, —З–Є—Б–ї–∞ —Б–Њ–µ–і–Є–љ–µ–љ–Є–є –Є —Б–ї–Њ–ґ–љ–Њ—Б—В—М –Ј–∞–њ—А–Њ—Б–Њ–≤, —В–∞–Ї —З—В–Њ –Њ–њ—В–Є–Љ–∞–ї—М–љ–Њ –љ–∞—Б—В—А–Њ–Є—В—М –±–∞–Ј—Г –і–∞–љ–љ—Л—Е –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ —Г—З–Є—В—Л–≤–∞—П –≤—Б–µ —Н—В–Є –њ–∞—А–∞–Љ–µ—В—А—Л.
6 –Ю–њ—В–Є–Љ–Є–Ј–∞—Ж–Є—П –С–Ф –Є –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П
–Ф–ї—П –±—Л—Б—В—А–Њ–є —А–∞–±–Њ—В—Л –Ї–∞–ґ–і–Њ–≥–Њ –Ј–∞–њ—А–Њ—Б–∞ –≤ –≤–∞—И–µ–є –±–∞–Ј–µ –≤ –Њ—Б–љ–Њ–≤–љ–Њ–Љ —В—А–µ–±—Г–µ—В—Б—П —Б–ї–µ–і—Г—О—Й–µ–µ:- –Ю—В—Б—Г—В—Б—В–≤–Є–µ –≤ –±–∞–Ј–µ –Љ—Г—Б–Њ—А–∞, –Љ–µ—И–∞—О—Й–µ–≥–Њ –і–Њ–±—А–∞—В—М—Б—П –і–Њ –∞–Ї—В—Г–∞–ї—М–љ—Л—Е –і–∞–љ–љ—Л—Е. –Ь–Њ–ґ–љ–Њ —Б—Д–Њ—А–Љ—Г–ї–Є—А–Њ–≤–∞—В—М –і–≤–µ –њ–Њ–і–Ј–∞–і–∞—З–Є:
- –У—А–∞–Љ–Њ—В–љ–Њ–µ –њ—А–Њ–µ–Ї—В–Є—А–Њ–≤–∞–љ–Є–µ –±–∞–Ј—Л. –Ю—Б–≤–µ—Й–µ–љ–Є–µ —Н—В–Њ–≥–Њ –≤–Њ–њ—А–Њ—Б–∞ –≤—Л—Е–Њ–і–Є—В –і–∞–ї–µ–Ї–Њ –Ј–∞ —А–∞–Љ–Ї–Є —Н—В–Њ–є —Б—В–∞—В—М–Є.
- –°–±–Њ—А–Ї–∞ –Љ—Г—Б–Њ—А–∞, –≤–Њ–Ј–љ–Є–Ї–∞—О—Й–µ–≥–Њ –њ—А–Є —А–∞–±–Њ—В–µ –°–£–С–Ф.
- –Э–∞–ї–Є—З–Є–µ –±—Л—Б—В—А—Л—Е –њ—Г—В–µ–є –і–Њ—Б—В—Г–њ–∞ –Ї –і–∞–љ–љ—Л–Љ -- –Є–љ–і–µ–Ї—Б–Њ–≤.
- –Т–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А–Њ–Љ —Н—В–Є—Е –±—Л—Б—В—А—Л—Е –њ—Г—В–µ–є.
- –Ю–±—Е–Њ–і –Є–Ј–≤–µ—Б—В–љ—Л—Е –њ—А–Њ–±–ї–µ–Љ.
1 –Я–Њ–і–і–µ—А–ґ–∞–љ–Є–µ –±–∞–Ј—Л –≤ –њ–Њ—А—П–і–Ї–µ
–Т –і–∞–љ–љ–Њ–Љ —А–∞–Ј–і–µ–ї–µ –Њ–њ–Є—Б–∞–љ—Л –і–µ–є—Б—В–≤–Є—П, –Ї–Њ—В–Њ—А—Л–µ –і–Њ–ї–ґ–љ—Л –њ–µ—А–Є–Њ–і–Є—З–µ—Б–Ї–Є –≤—Л–њ–Њ–ї–љ—П—В—М—Б—П –і–ї—П –Ї–∞–ґ–і–Њ–є –±–∞–Ј—Л. –Ю—В —А–∞–Ј—А–∞–±–Њ—В—З–Є–Ї–∞ —В—А–µ–±—Г–µ—В—Б—П —В–Њ–ї—М–Ї–Њ –љ–∞—Б—В—А–Њ–Є—В—М –Є—Е –∞–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Њ–µ –≤—Л–њ–Њ–ї–љ–µ–љ–Є–µ (–њ—А–Є –њ–Њ–Љ–Њ—Й–Є cron) –Є –Њ–њ—Л—В–љ—Л–Љ –њ—Г—В—С–Љ –њ–Њ–і–Њ–±—А–∞—В—М –µ–≥–Њ –Њ–њ—В–Є–Љ–∞–ї—М–љ—Г—О —З–∞—Б—В–Њ—В—Г.
1 –Ъ–Њ–Љ–∞–љ–і–∞ ANALYZE
–°–ї—Г–ґ–Є—В –і–ї—П –Њ–±–љ–Њ–≤–ї–µ–љ–Є—П –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Є –Њ —А–∞—Б–њ—А–µ–і–µ–ї–µ–љ–Є–Є –і–∞–љ–љ—Л—Е –≤ —В–∞–±–ї–Є—Ж–µ. –≠—В–∞ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А–Њ–Љ –і–ї—П –≤—Л–±–Њ—А–∞ –љ–∞–Є–±–Њ–ї–µ–µ –±—Л—Б—В—А–Њ–≥–Њ –њ–ї–∞–љ–∞ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Ј–∞–њ—А–Њ—Б–∞.–Ю–±—Л—З–љ–Њ –Ї–Њ–Љ–∞–љ–і–∞ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –≤ —Б–≤—П–Ј–Ї–µ VACUUM ANALYZE. –Х—Б–ї–Є –≤ –±–∞–Ј–µ –µ—Б—В—М —В–∞–±–ї–Є—Ж—Л, –і–∞–љ–љ—Л–µ –≤ –Ї–Њ—В–Њ—А—Л—Е –љ–µ –Є–Ј–Љ–µ–љ—П—О—В—Б—П –Є –љ–µ —Г–і–∞–ї—П—О—В—Б—П, –∞ –ї–Є—И—М –і–Њ–±–∞–≤–ї—П—О—В—Б—П, —В–Њ –і–ї—П —В–∞–Ї–Є—Е —В–∞–±–ї–Є—Ж –Љ–Њ–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Њ—В–і–µ–ї—М–љ—Г—О –Ї–Њ–Љ–∞–љ–і—Г ANALYZE. –Ґ–∞–Ї–ґ–µ —Б—В–Њ–Є—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —Н—В—Г –Ї–Њ–Љ–∞–љ–і—Г –і–ї—П –Њ—В–і–µ–ї—М–љ–Њ–є —В–∞–±–ї–Є—Ж—Л –њ–Њ—Б–ї–µ –і–Њ–±–∞–≤–ї–µ–љ–Є—П –≤ –љ–µ—С –±–Њ–ї—М—И–Њ–≥–Њ –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ –Ј–∞–њ–Є—Б–µ–є.
2 –Ъ–Њ–Љ–∞–љ–і–∞ REINDEX
–Ъ–Њ–Љ–∞–љ–і–∞ REINDEX –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –і–ї—П –њ–µ—А–µ—Б—В—А–Њ–є–Ї–Є —Б—Г—Й–µ—Б—В–≤—Г—О—Й–Є—Е –Є–љ–і–µ–Ї—Б–Њ–≤. –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –µ—С –Є–Љ–µ–µ—В —Б–Љ—Л—Б–ї –≤ —Б–ї—Г—З–∞–µ:- –њ–Њ—А—З–Є –Є–љ–і–µ–Ї—Б–∞;
- –њ–Њ—Б—В–Њ—П–љ–љ–Њ–≥–Њ —Г–≤–µ–ї–Є—З–µ–љ–Є—П –µ–≥–Њ —А–∞–Ј–Љ–µ—А–∞.
–Т—В–Њ—А–Њ–є —Б–ї—Г—З–∞–є —В—А–µ–±—Г–µ—В –њ–Њ—П—Б–љ–µ–љ–Є–є. –Ш–љ–і–µ–Ї—Б, –Ї–∞–Ї –Є —В–∞–±–ї–Є—Ж–∞, —Б–Њ–і–µ—А–ґ–Є—В –±–ї–Њ–Ї–Є —Б–Њ —Б—В–∞—А—Л–Љ–Є –≤–µ—А—Б–Є—П–Љ–Є –Ј–∞–њ–Є—Б–µ–є. PostgreSQL –љ–µ –≤—Б–µ–≥–і–∞ –Љ–Њ–ґ–µ—В –Ј–∞–љ–Њ–≤–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —Н—В–Є –±–ї–Њ–Ї–Є, –Є –њ–Њ—Н—В–Њ–Љ—Г —Д–∞–є–ї —Б –Є–љ–і–µ–Ї—Б–Њ–Љ –њ–Њ—Б—В–µ–њ–µ–љ–љ–Њ —Г–≤–µ–ї–Є—З–Є–≤–∞–µ—В—Б—П –≤ —А–∞–Ј–Љ–µ—А–∞—Е. –Х—Б–ї–Є –і–∞–љ–љ—Л–µ –≤ —В–∞–±–ї–Є—Ж–µ —З–∞—Б—В–Њ –Љ–µ–љ—П—О—В—Б—П, —В–Њ —А–∞—Б—В–Є –Њ–љ –Љ–Њ–ґ–µ—В –≤–µ—Б—М–Љ–∞ –±—Л—Б—В—А–Њ.
–Х—Б–ї–Є –≤—Л –Ј–∞–Љ–µ—В–Є–ї–Є –њ–Њ–і–Њ–±–љ–Њ–µ –њ–Њ–≤–µ–і–µ–љ–Є–µ –Ї–∞–Ї–Њ–≥–Њ-—В–Њ –Є–љ–і–µ–Ї—Б–∞, —В–Њ —Б—В–Њ–Є—В –љ–∞—Б—В—А–Њ–Є—В—М –і–ї—П –љ–µ–≥–Њ –њ–µ—А–Є–Њ–і–Є—З–µ—Б–Ї–Њ–µ –≤—Л–њ–Њ–ї–љ–µ–љ–Є–µ –Ї–Њ–Љ–∞–љ–і—Л REINDEX. –£—З—В–Є—В–µ: –Ї–Њ–Љ–∞–љ–і–∞ REINDEX, –Ї–∞–Ї –Є VACUUM FULL, –њ–Њ–ї–љ–Њ—Б—В—М—О –±–ї–Њ–Ї–Є—А—Г–µ—В —В–∞–±–ї–Є—Ж—Г, –њ–Њ—Н—В–Њ–Љ—Г –≤—Л–њ–Њ–ї–љ—П—В—М –µ—С –љ–∞–і–Њ —В–Њ–≥–і–∞, –Ї–Њ–≥–і–∞ –Ј–∞–≥—А—Г–Ј–Ї–∞ —Б–µ—А–≤–µ—А–∞ –Љ–Є–љ–Є–Љ–∞–ї—М–љ–∞.
2 –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –Є–љ–і–µ–Ї—Б–Њ–≤
–Ю–њ—Л—В –њ–Њ–Ї–∞–Ј—Л–≤–∞–µ—В, —З—В–Њ –љ–∞–Є–±–Њ–ї–µ–µ –Ј–љ–∞—З–Є—В–µ–ї—М–љ—Л–µ –њ—А–Њ–±–ї–µ–Љ—Л —Б –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М—О –≤—Л–Ј—Л–≤–∞—О—В—Б—П –Њ—В—Б—Г—В—Б—В–≤–Є–µ–Љ –љ—Г–ґ–љ—Л—Е –Є–љ–і–µ–Ї—Б–Њ–≤. –Я–Њ—Н—В–Њ–Љ—Г —Б—В–Њ–ї–Ї–љ—Г–≤—И–Є—Б—М —Б –Љ–µ–і–ї–µ–љ–љ—Л–Љ –Ј–∞–њ—А–Њ—Б–Њ–Љ, –≤ –њ–µ—А–≤—Г—О –Њ—З–µ—А–µ–і—М –њ—А–Њ–≤–µ—А—М—В–µ, —Б—Г—Й–µ—Б—В–≤—Г—О—В –ї–Є –Є–љ–і–µ–Ї—Б—Л, –Ї–Њ—В–Њ—А—Л–µ –Њ–љ –Љ–Њ–ґ–µ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М. –Х—Б–ї–Є –љ–µ—В -- –њ–Њ—Б—В—А–Њ–є—В–µ –Є—Е. –Ш–Ј–ї–Є—И–µ–Ї –Є–љ–і–µ–Ї—Б–Њ–≤, –≤–њ—А–Њ—З–µ–Љ, —В–Њ–ґ–µ —З—А–µ–≤–∞—В –њ—А–Њ–±–ї–µ–Љ–∞–Љ–Є:- –Ъ–Њ–Љ–∞–љ–і—Л, –Є–Ј–Љ–µ–љ—П—О—Й–Є–µ –і–∞–љ–љ—Л–µ –≤ —В–∞–±–ї–Є—Ж–µ, –і–Њ–ї–ґ–љ—Л –Є–Ј–Љ–µ–љ–Є—В—М —В–∞–Ї–ґ–µ –Є –Є–љ–і–µ–Ї—Б—Л. –Ю—З–µ–≤–Є–і–љ–Њ, —З–µ–Љ –±–Њ–ї—М—И–µ –Є–љ–і–µ–Ї—Б–Њ–≤ –њ–Њ—Б—В—А–Њ–µ–љ–Њ –і–ї—П —В–∞–±–ї–Є—Ж—Л, —В–µ–Љ –Љ–µ–і–ї–µ–љ–љ–µ–µ —Н—В–Њ –±—Г–і–µ—В –њ—А–Њ–Є—Б—Е–Њ–і–Є—В—М.
- –Ю–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А –њ–µ—А–µ–±–Є—А–∞–µ—В –≤–Њ–Ј–Љ–Њ–ґ–љ—Л–µ –њ—Г—В–Є –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Ј–∞–њ—А–Њ—Б–Њ–≤. –Х—Б–ї–Є –њ–Њ—Б—В—А–Њ–µ–љ–Њ –Љ–љ–Њ–≥–Њ –љ–µ–љ—Г–ґ–љ—Л—Е –Є–љ–і–µ–Ї—Б–Њ–≤, —В–Њ —Н—В–Њ—В –њ–µ—А–µ–±–Њ—А –±—Г–і–µ—В –Є–і—В–Є –і–Њ–ї—М—И–µ.
1 –Ъ–Њ–Љ–∞–љ–і–∞ EXPLAIN [ANALYZE]
–Ъ–Њ–Љ–∞–љ–і–∞ EXPLAIN [–Ј–∞–њ—А–Њ—Б] –њ–Њ–Ї–∞–Ј—Л–≤–∞–µ—В, –Ї–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ PostgreSQL —Б–Њ–±–Є—А–∞–µ—В—Б—П –≤—Л–њ–Њ–ї–љ—П—В—М –≤–∞—И –Ј–∞–њ—А–Њ—Б. –Ъ–Њ–Љ–∞–љ–і–∞ EXPLAIN ANALYZE [–Ј–∞–њ—А–Њ—Б] –≤—Л–њ–Њ–ї–љ—П–µ—В –Ј–∞–њ—А–Њ—Б8 –Є –њ–Њ–Ї–∞–Ј—Л–≤–∞–µ—В –Ї–∞–Ї –Є–Ј–љ–∞—З–∞–ї—М–љ—Л–є –њ–ї–∞–љ, —В–∞–Ї –Є —А–µ–∞–ї—М–љ—Л–є –њ—А–Њ—Ж–µ—Б—Б –µ–≥–Њ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П.–І—В–µ–љ–Є–µ –≤—Л–≤–Њ–і–∞ —Н—В–Є—Е –Ї–Њ–Љ–∞–љ–і -- –Є—Б–Ї—Г—Б—Б—В–≤–Њ, –Ї–Њ—В–Њ—А–Њ–µ –њ—А–Є—Е–Њ–і–Є—В —Б –Њ–њ—Л—В–Њ–Љ. –Ф–ї—П –љ–∞—З–∞–ї–∞ –Њ–±—А–∞—Й–∞–є—В–µ –≤–љ–Є–Љ–∞–љ–Є–µ –љ–∞ —Б–ї–µ–і—Г—О—Й–µ–µ:
- –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –њ–Њ–ї–љ–Њ–≥–Њ –њ—А–Њ—Б–Љ–Њ—В—А–∞ —В–∞–±–ї–Є—Ж—Л (seq scan).
- –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –љ–∞–Є–±–Њ–ї–µ–µ –њ—А–Є–Љ–Є—В–Є–≤–љ–Њ–≥–Њ —Б–њ–Њ—Б–Њ–±–∞ –Њ–±—К–µ–і–Є–љ–µ–љ–Є—П —В–∞–±–ї–Є—Ж (nested loop).
- –Ф–ї—П EXPLAIN ANALYZE: –љ–µ—В –ї–Є –±–Њ–ї—М—И–Є—Е –Њ—В–ї–Є—З–Є–є –≤ –њ—А–µ–і–њ–Њ–ї–∞–≥–∞–µ–Љ–Њ–Љ –Ї–Њ–ї–Є—З–µ—Б—В–≤–µ –Ј–∞–њ–Є—Б–µ–є –Є —А–µ–∞–ї—М–љ–Њ –≤—Л–±—А–∞–љ–љ–Њ–Љ? –Х—Б–ї–Є –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В —Г—Б—В–∞—А–µ–≤—И—Г—О —Б—В–∞—В–Є—Б—В–Є–Ї—Г, —В–Њ –Њ–љ –Љ–Њ–ґ–µ—В –≤—Л–±–Є—А–∞—В—М –љ–µ —Б–∞–Љ—Л–є –±—Л—Б—В—А—Л–є –њ–ї–∞–љ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Ј–∞–њ—А–Њ—Б–∞.
–°–ї–µ–і—Г–µ—В –Њ—В–Љ–µ—В–Є—В—М, —З—В–Њ –њ–Њ–ї–љ—Л–є –њ—А–Њ—Б–Љ–Њ—В—А —В–∞–±–ї–Є—Ж—Л –і–∞–ї–µ–Ї–Њ –љ–µ –≤—Б–µ–≥–і–∞ –Љ–µ–і–ї–µ–љ–љ–µ–µ –њ—А–Њ—Б–Љ–Њ—В—А–∞ –њ–Њ –Є–љ–і–µ–Ї—Б—Г. –Х—Б–ї–Є, –љ–∞–њ—А–Є–Љ–µ—А, –≤ —В–∞–±–ї–Є—Ж–µ-—Б–њ—А–∞–≤–Њ—З–љ–Є–Ї–µ –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ —Б–Њ—В–µ–љ –Ј–∞–њ–Є—Б–µ–є, —Г–Љ–µ—Й–∞—О—Й–Є—Е—Б—П –≤ –Њ–і–љ–Њ–Љ-–і–≤—Г—Е –±–ї–Њ–Ї–∞—Е –љ–∞ –і–Є—Б–Ї–µ, —В–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –Є–љ–і–µ–Ї—Б–∞ –њ—А–Є–≤–µ–і—С—В –ї–Є—И—М –Ї —В–Њ–Љ—Г, —З—В–Њ –њ—А–Є–і—С—В—Б—П —З–Є—В–∞—В—М –µ—Й—С –Є –њ–∞—А—Г –ї–Є—И–љ–Є—Е –±–ї–Њ–Ї–Њ–≤ –Є–љ–і–µ–Ї—Б–∞. –Х—Б–ї–Є –≤ –Ј–∞–њ—А–Њ—Б–µ –њ—А–Є–і—С—В—Б—П –≤—Л–±—А–∞—В—М 80% –Ј–∞–њ–Є—Б–µ–є –Є–Ј –±–Њ–ї—М—И–Њ–є —В–∞–±–ї–Є—Ж—Л, —В–Њ –њ–Њ–ї–љ—Л–є –њ—А–Њ—Б–Љ–Њ—В—А –Њ–њ—П—В—М –ґ–µ –њ–Њ–ї—Г—З–Є—В—Б—П –±—Л—Б—В—А–µ–µ.
–Я—А–Є —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є–Є –Ј–∞–њ—А–Њ—Б–Њ–≤ —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ EXPLAIN ANALYZE –Љ–Њ–ґ–љ–Њ –≤–Њ—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М—Б—П –љ–∞—Б—В—А–Њ–є–Ї–∞–Љ–Є, –Ј–∞–њ—А–µ—Й–∞—О—Й–Є–Љ–Є –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А—Г –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Њ–њ—А–µ–і–µ–ї—С–љ–љ—Л–µ –њ–ї–∞–љ—Л –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П. –Э–∞–њ—А–Є–Љ–µ—А,
SET enable_seqscan=false;
–Ј–∞–њ—А–µ—В–Є—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –њ–Њ–ї–љ–Њ–≥–Њ –њ—А–Њ—Б–Љ–Њ—В—А–∞ —В–∞–±–ї–Є—Ж—Л, –Є –≤—Л —Б–Љ–Њ–ґ–µ—В–µ –≤—Л—П—Б–љ–Є—В—М, –њ—А–∞–≤ –ї–Є –±—Л–ї –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А, –Њ—В–Ї–∞–Ј—Л–≤–∞—П—Б—М –Њ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П –Є–љ–і–µ–Ї—Б–∞. –Э–Є –≤ –Ї–Њ–µ–Љ —Б–ї—Г—З–∞–µ –љ–µ —Б–ї–µ–і—Г–µ—В –њ—А–Њ–њ–Є—Б—Л–≤–∞—В—М –њ–Њ–і–Њ–±–љ—Л–µ –Ї–Њ–Љ–∞–љ–і—Л –≤ postgresql.conf! –≠—В–Њ –Љ–Њ–ґ–µ—В —Г—Б–Ї–Њ—А–Є—В—М –≤—Л–њ–Њ–ї–љ–µ–љ–Є–µ –љ–µ—Б–Ї–Њ–ї—М–Ї–Є—Е –Ј–∞–њ—А–Њ—Б–Њ–≤, –љ–Њ —Б–Є–ї—М–љ–Њ –Ј–∞–Љ–µ–і–ї–Є—В –≤—Б–µ –Њ—Б—В–∞–ї—М–љ—Л–µ!
2 –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —Б–Њ–±—А–∞–љ–љ–Њ–є —Б—В–∞—В–Є—Б—В–Є–Ї–Є
–†–µ–Ј—Г–ї—М—В–∞—В—Л —А–∞–±–Њ—В—Л —Б–±–Њ—А—Й–Є–Ї–∞ —Б—В–∞—В–Є—Б—В–Є–Ї–Є –і–Њ—Б—В—Г–њ–љ—Л —З–µ—А–µ–Ј —Б–њ–µ—Ж–Є–∞–ї—М–љ—Л–µ —Б–Є—Б—В–µ–Љ–љ—Л–µ –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–Є—П. –Э–∞–Є–±–Њ–ї–µ–µ –Є–љ—В–µ—А–µ—Б–љ—Л –і–ї—П –љ–∞—И–Є—Е —Ж–µ–ї–µ–є —Б–ї–µ–і—Г—О—Й–Є–µ:- pg_stat_user_tables —Б–Њ–і–µ—А–ґ–Є—В -- –і–ї—П –Ї–∞–ґ–і–Њ–є –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М—Б–Ї–Њ–є —В–∞–±–ї–Є—Ж—Л –≤ —В–µ–Ї—Г—Й–µ–є –±–∞–Ј–µ –і–∞–љ–љ—Л—Е -- –Њ–±—Й–µ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ–Њ–ї–љ—Л—Е –њ—А–Њ—Б–Љ–Њ—В—А–Њ–≤ –Є –њ—А–Њ—Б–Љ–Њ—В—А–Њ–≤ —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ –Є–љ–і–µ–Ї—Б–Њ–≤, –Њ–±—Й–Є–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ –Ј–∞–њ–Є—Б–µ–є, –Ї–Њ—В–Њ—А—Л–µ –±—Л–ї–Є –≤–Њ–Ј–≤—А–∞—Й–µ–љ—Л –≤ —А–µ–Ј—Г–ї—М—В–∞—В–µ –Њ–±–Њ–Є—Е —В–Є–њ–Њ–≤ –њ—А–Њ—Б–Љ–Њ—В—А–∞, –∞ —В–∞–Ї–ґ–µ –Њ–±—Й–Є–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ –≤—Б—В–∞–≤–ї–µ–љ–љ—Л—Е, –Є–Ј–Љ–µ–љ—С–љ–љ—Л—Е –Є —Г–і–∞–ї—С–љ–љ—Л—Е –Ј–∞–њ–Є—Б–µ–є.
- pg_stat_user_indexes —Б–Њ–і–µ—А–ґ–Є—В -- –і–ї—П –Ї–∞–ґ–і–Њ–≥–Њ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М—Б–Ї–Њ–≥–Њ –Є–љ–і–µ–Ї—Б–∞ –≤ —В–µ–Ї—Г—Й–µ–є –±–∞–Ј–µ –і–∞–љ–љ—Л—Е -- –Њ–±—Й–µ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ—А–Њ—Б–Љ–Њ—В—А–Њ–≤, –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–≤—И–Є—Е —Н—В–Њ—В –Є–љ–і–µ–Ї—Б, –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ—А–Њ—З–Є—В–∞–љ–љ—Л—Е –Ј–∞–њ–Є—Б–µ–є, –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Г—Б–њ–µ—И–љ–Њ –њ—А–Њ—З–Є—В–∞–љ–љ—Л—Е –Ј–∞–њ–Є—Б–µ–є –≤ —В–∞–±–ї–Є—Ж–µ (–Љ–Њ–ґ–µ—В –±—Л—В—М –Љ–µ–љ—М—И–µ –њ—А–µ–і—Л–і—Г—Й–µ–≥–Њ –Ј–љ–∞—З–µ–љ–Є—П, –µ—Б–ї–Є –≤ –Є–љ–і–µ–Ї—Б–µ –µ—Б—В—М –Ј–∞–њ–Є—Б–Є, —Г–Ї–∞–Ј—Л–≤–∞—О—Й–Є–µ –љ–∞ —Г—Б—В–∞—А–µ–≤—И–Є–µ –Ј–∞–њ–Є—Б–Є –≤ —В–∞–±–ї–Є—Ж–µ).
- pg_statio_user_tables —Б–Њ–і–µ—А–ґ–Є—В -- –і–ї—П –Ї–∞–ґ–і–Њ–є –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М—Б–Ї–Њ–є —В–∞–±–ї–Є—Ж—Л –≤ —В–µ–Ї—Г—Й–µ–є –±–∞–Ј–µ –і–∞–љ–љ—Л—Е -- –Њ–±—Й–µ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –±–ї–Њ–Ї–Њ–≤, –њ—А–Њ—З–Є—В–∞–љ–љ—Л—Е –Є–Ј —В–∞–±–ї–Є—Ж—Л, –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –±–ї–Њ–Ї–Њ–≤, –Њ–Ї–∞–Ј–∞–≤—И–Є—Е—Б—П –њ—А–Є —Н—В–Њ–Љ –≤ –±—Г—Д–µ—А–µ (—Б–Љ. –њ—Г–љ–Ї—В 2.1.1), –∞ —В–∞–Ї–ґ–µ –∞–љ–∞–ї–Њ–≥–Є—З–љ—Г—О —Б—В–∞—В–Є—Б—В–Є–Ї—Г –і–ї—П –≤—Б–µ—Е –Є–љ–і–µ–Ї—Б–Њ–≤ –њ–Њ —В–∞–±–ї–Є—Ж–µ –Є, –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ, –њ–Њ —Б–≤—П–Ј–∞–љ–љ–Њ–є —Б –љ–µ–є —В–∞–±–ї–Є—Ж–µ–є TOAST.
–Ш–Ј —Н—В–Є—Е –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–Є–є –Љ–Њ–ґ–љ–Њ —Г–Ј–љ–∞—В—М, –≤ —З–∞—Б—В–љ–Њ—Б—В–Є
- –Ф–ї—П –Ї–∞–Ї–Є—Е —В–∞–±–ї–Є—Ж —Б—В–Њ–Є—В —Б–Њ–Ј–і–∞—В—М –љ–Њ–≤—Л–µ –Є–љ–і–µ–Ї—Б—Л (–Є–љ–і–Є–Ї–∞—В–Њ—А–Њ–Љ —Б–ї—Г–ґ–Є—В –±–Њ–ї—М—И–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ–Њ–ї–љ—Л—Е –њ—А–Њ—Б–Љ–Њ—В—А–Њ–≤ –Є –±–Њ–ї—М—И–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ—А–Њ—З–Є—В–∞–љ–љ—Л—Е –±–ї–Њ–Ї–Њ–≤).
- –Ъ–∞–Ї–Є–µ –Є–љ–і–µ–Ї—Б—Л –≤–Њ–Њ–±—Й–µ –љ–µ –Є—Б–њ–Њ–ї—М–Ј—Г—О—В—Б—П –≤ –Ј–∞–њ—А–Њ—Б–∞—Е. –Ш—Е –Є–Љ–µ–µ—В —Б–Љ—Л—Б–ї —Г–і–∞–ї–Є—В—М, –µ—Б–ї–Є, –Ї–Њ–љ–µ—З–љ–Њ, —А–µ—З—М –љ–µ –Є–і—С—В –Њ–± –Є–љ–і–µ–Ї—Б–∞—Е, –Њ–±–µ—Б–њ–µ—З–Є–≤–∞—О—Й–Є—Е –≤—Л–њ–Њ–ї–љ–µ–љ–Є–µ –Њ–≥—А–∞–љ–Є—З–µ–љ–Є–є PRIMARY KEY –Є UNIQUE.
- –Ф–Њ—Б—В–∞—В–Њ—З–µ–љ –ї–Є –Њ–±—К—С–Љ –±—Г—Д–µ—А–∞ —Б–µ—А–≤–µ—А–∞.
–Ґ–∞–Ї–ґ–µ –≤–Њ–Ј–Љ–Њ–ґ–µ–љ «–і–µ–і—Г–Ї—В–Є–≤–љ—Л–є» –њ–Њ–і—Е–Њ–і, –њ—А–Є –Ї–Њ—В–Њ—А–Њ–Љ —Б–љ–∞—З–∞–ї–∞ —Б–Њ–Ј–і–∞—С—В—Б—П –±–Њ–ї—М—И–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –Є–љ–і–µ–Ї—Б–Њ–≤, –∞ –Ј–∞—В–µ–Љ –љ–µ–Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ—Л–µ –Є–љ–і–µ–Ї—Б—Л —Г–і–∞–ї—П—О—В—Б—П.
3 –Т–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є –Є–љ–і–µ–Ї—Б–Њ–≤ –≤ PostgreSQL
–§—Г–љ–Ї—Ж–Є–Њ–љ–∞–ї—М–љ—Л–µ –Є–љ–і–µ–Ї—Б—Л –Т—Л –Љ–Њ–ґ–µ—В–µ –њ–Њ—Б—В—А–Њ–Є—В—М –Є–љ–і–µ–Ї—Б –љ–µ —В–Њ–ї—М–Ї–Њ –њ–Њ –њ–Њ–ї—О/–љ–µ—Б–Ї–Њ–ї—М–Ї–Є–Љ –њ–Њ–ї—П–Љ —В–∞–±–ї–Є—Ж—Л, –љ–Њ –Є –њ–Њ –≤—Л—А–∞–ґ–µ–љ–Є—О, –Ј–∞–≤–Є—Б—П—Й–µ–Љ—Г –Њ—В –њ–Њ–ї–µ–є. –Я—Г—Б—В—М, –љ–∞–њ—А–Є–Љ–µ—А, –≤ –≤–∞—И–µ–є —В–∞–±–ї–Є—Ж–µ foo –µ—Б—В—М –њ–Њ–ї–µ foo_name, –Є –≤—Л–±–Њ—А–Ї–Є —З–∞—Б—В–Њ –і–µ–ї–∞—О—В—Б—П –њ–Њ —Г—Б–ї–Њ–≤–Є—О «–њ–µ—А–≤–∞—П –±—Г–Ї–≤–∞ foo_name = '–±—Г–Ї–≤–∞', –≤ –ї—О–±–Њ–Љ —А–µ–≥–Є—Б—В—А–µ». –Т—Л –Љ–Њ–ґ–µ—В–µ —Б–Њ–Ј–і–∞—В—М –Є–љ–і–µ–Ї—БCREATE INDEX foo_name_first_idx ON foo ((lower(substr(foo_name, 1, 1))));–Є –Ј–∞–њ—А–Њ—Б –≤–Є–і–∞
SELECT * FROM foo WHERE lower(substr(foo_name, 1, 1)) = '—Л';–±—Г–і–µ—В –µ–≥–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М.
–І–∞—Б—В–Є—З–љ—Л–µ –Є–љ–і–µ–Ї—Б—Л (partial indexes) –Я–Њ–і —З–∞—Б—В–Є—З–љ—Л–Љ –Є–љ–і–µ–Ї—Б–Њ–Љ –њ–Њ–љ–Є–Љ–∞–µ—В—Б—П –Є–љ–і–µ–Ї—Б —Б –њ—А–µ–і–Є–Ї–∞—В–Њ–Љ WHERE. –Я—Г—Б—В—М, –љ–∞–њ—А–Є–Љ–µ—А, —Г –≤–∞—Б –µ—Б—В—М –≤ –±–∞–Ј–µ —В–∞–±–ї–Є—Ж–∞ scheta —Б –њ–∞—А–∞–Љ–µ—В—А–Њ–Љ uplocheno —В–Є–њ–∞ boolean. –Ч–∞–њ–Є—Б–µ–є, –≥–і–µ uplocheno = false –Љ–µ–љ—М—И–µ, —З–µ–Љ –Ј–∞–њ–Є—Б–µ–є —Б uplocheno = true, –∞ –Ј–∞–њ—А–Њ—Б—Л –њ–Њ –љ–Є–Љ –≤—Л–њ–Њ–ї–љ—П—О—В—Б—П –Ј–љ–∞—З–Є—В–µ–ї—М–љ–Њ —З–∞—Й–µ. –Т—Л –Љ–Њ–ґ–µ—В–µ —Б–Њ–Ј–і–∞—В—М –Є–љ–і–µ–Ї—Б
CREATE INDEX scheta_neuplocheno ON scheta (id) WHERE NOT uplocheno;–Ї–Њ—В–Њ—А—Л–є –±—Г–і–µ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М—Б—П –Ј–∞–њ—А–Њ—Б–Њ–Љ –≤–Є–і–∞
SELECT * FROM scheta WHERE NOT uplocheno AND ...;–Ф–Њ—Б—В–Њ–Є–љ—Б—В–≤–Њ –њ–Њ–і—Е–Њ–і–∞ –≤ —В–Њ–Љ, —З—В–Њ –Ј–∞–њ–Є—Б–Є, –љ–µ —Г–і–Њ–≤–ї–µ—В–≤–Њ—А—П—О—Й–Є–µ —Г—Б–ї–Њ–≤–Є—О WHERE, –њ—А–Њ—Б—В–Њ –љ–µ –њ–Њ–њ–∞–і—Г—В –≤ –Є–љ–і–µ–Ї—Б.
3 –Я–µ—А–µ–љ–Њ—Б –ї–Њ–≥–Є–Ї–Є –љ–∞ —Б—В–Њ—А–Њ–љ—Г —Б–µ—А–≤–µ—А–∞
–≠—В–Њ—В –њ—Г–љ–Ї—В –Њ—З–µ–≤–Є–і–µ–љ –і–ї—П –Њ–њ—Л—В–љ—Л—Е –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є PostrgeSQL –Є –њ—А–µ–і–љ–∞–Ј–љ–∞—З–µ–љ –і–ї—П —В–µ—Е, –Ї—В–Њ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В –Є–ї–Є –њ–µ—А–µ–љ–Њ—Б–Є—В –љ–∞ PostgreSQL –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П, –љ–∞–њ–Є—Б–∞–љ–љ—Л–µ –Є–Ј–љ–∞—З–∞–ї—М–љ–Њ –і–ї—П –±–Њ–ї–µ–µ –њ—А–Є–Љ–Є—В–Є–≤–љ—Л—Е –°–£–С–Ф.–†–µ–∞–ї–Є–Ј–∞—Ж–Є—П —З–∞—Б—В–Є –ї–Њ–≥–Є–Ї–Є –љ–∞ —Б—В–Њ—А–Њ–љ–µ —Б–µ—А–≤–µ—А–∞ —З–µ—А–µ–Ј —Е—А–∞–љ–Є–Љ—Л–µ –њ—А–Њ—Ж–µ–і—Г—А—Л, —В—А–Є–≥–≥–µ—А—Л, –њ—А–∞–≤–Є–ї–∞9 —З–∞—Б—В–Њ –њ–Њ–Ј–≤–Њ–ї—П–µ—В —Г—Б–Ї–Њ—А–Є—В—М —А–∞–±–Њ—В—Г –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П. –Ф–µ–є—Б—В–≤–Є—В–µ–ї—М–љ–Њ, –µ—Б–ї–Є –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –Ј–∞–њ—А–Њ—Б–Њ–≤ –Њ–±—К–µ–і–Є–љ–µ–љ—Л –≤ –њ—А–Њ—Ж–µ–і—Г—А—Г, —В–Њ –љ–µ —В—А–µ–±—Г–µ—В—Б—П
- –њ–µ—А–µ—Б—Л–ї–Ї–∞ –њ—А–Њ–Љ–µ–ґ—Г—В–Њ—З–љ—Л—Е –Ј–∞–њ—А–Њ—Б–Њ–≤ –љ–∞ —Б–µ—А–≤–µ—А;
- –њ–Њ–ї—Г—З–µ–љ–Є–µ –њ—А–Њ–Љ–µ–ґ—Г—В–Њ—З–љ—Л—Е —А–µ–Ј—Г–ї—М—В–∞—В–Њ–≤ –љ–∞ –Ї–ї–Є–µ–љ—В –Є –Є—Е –Њ–±—А–∞–±–Њ—В–Ї–∞.
–Ъ—А–Њ–Љ–µ —В–Њ–≥–Њ, —Е—А–∞–љ–Є–Љ—Л–µ –њ—А–Њ—Ж–µ–і—Г—А—Л —Г–њ—А–Њ—Й–∞—О—В –њ—А–Њ—Ж–µ—Б—Б —А–∞–Ј—А–∞–±–Њ—В–Ї–Є –Є –њ–Њ–і–і–µ—А–ґ–Ї–Є: –Є–Ј–Љ–µ–љ–µ–љ–Є—П –љ–∞–і–Њ –≤–љ–Њ—Б–Є—В—М —В–Њ–ї—М–Ї–Њ –љ–∞ —Б—В–Њ—А–Њ–љ–µ —Б–µ—А–≤–µ—А–∞, –∞ –љ–µ –Љ–µ–љ—П—В—М –Ј–∞–њ—А–Њ—Б—Л –≤–Њ –≤—Б–µ—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П—Е.
4 –Ю–њ—В–Є–Љ–Є–Ј–∞—Ж–Є—П –Ї–Њ–љ–Ї—А–µ—В–љ—Л—Е –Ј–∞–њ—А–Њ—Б–Њ–≤
–Т —Н—В–Њ–Љ —А–∞–Ј–і–µ–ї–µ –Њ–њ–Є—Б—Л–≤–∞—О—В—Б—П –Ј–∞–њ—А–Њ—Б—Л, –і–ї—П –Ї–Њ—В–Њ—А—Л—Е –њ–Њ —А–∞–Ј–љ—Л–Љ –њ—А–Є—З–Є–љ–∞–Љ –љ–µ–ї—М–Ј—П –Ј–∞—Б—В–∞–≤–Є—В—М –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Є–љ–і–µ–Ї—Б—Л, –Є –Ї–Њ—В–Њ—А—Л–µ –±—Г–і—Г—В –≤—Б–µ–≥–і–∞ –≤—Л–Ј—Л–≤–∞—В—М –њ–Њ–ї–љ—Л–є –њ—А–Њ—Б–Љ–Њ—В—А —В–∞–±–ї–Є—Ж—Л. –Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, –µ—Б–ї–Є –≤–∞–Љ —В—А–µ–±—Г–µ—В—Б—П –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —Н—В–Є –Ј–∞–њ—А–Њ—Б—Л –≤ —В—А–µ–±–Њ–≤–∞—В–µ–ї—М–љ–Њ–Љ –Ї –±—Л—Б—В—А–Њ–і–µ–є—Б—В–≤–Є—О –њ—А–Є–ї–Њ–ґ–µ–љ–Є–Є, —В–Њ –њ—А–Є–і—С—В—Б—П –Є—Е –Є–Ј–Љ–µ–љ–Є—В—М.
1 SELECT count(*) FROM <–Њ–≥—А–Њ–Љ–љ–∞—П —В–∞–±–ї–Є—Ж–∞>
–§—Г–љ–Ї—Ж–Є—П count() —А–∞–±–Њ—В–∞–µ—В –Њ—З–µ–љ—М –њ—А–Њ—Б—В–Њ: —Б–љ–∞—З–∞–ї–∞ –≤—Л–±–Є—А–∞—О—В—Б—П –≤—Б–µ –Ј–∞–њ–Є—Б–Є, —Г–і–Њ–≤–ї–µ—В–≤–Њ—А—П—О—Й–Є–µ —Г—Б–ї–Њ–≤–Є—О, –∞ –њ–Њ—В–Њ–Љ –Ї –њ–Њ–ї—Г—З–µ–љ–љ–Њ–Љ—Г –љ–∞–±–Њ—А—Г –Ј–∞–њ–Є—Б–µ–є –њ—А–Є–Љ–µ–љ—П–µ—В—Б—П –∞–≥—А–µ–≥–∞—В–љ–∞—П —Д—Г–љ–Ї—Ж–Є—П -- —Б—З–Є—В–∞–µ—В—Б—П –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –≤—Л–±—А–∞–љ—Л—Е —Б—В—А–Њ–Ї. –Ш–љ—Д–Њ—А–Љ–∞—Ж–Є—П –Њ –≤–Є–і–Є–Љ–Њ—Б—В–Є –Ј–∞–њ–Є—Б–Є –і–ї—П —В–µ–Ї—Г—Й–µ–є —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є (–∞ –Ї–Њ–љ–Ї—Г—А–µ–љ—В–љ—Л–Љ —В—А–∞–љ–Ј–∞–Ї—Ж–Є—П–Љ –Љ–Њ–ґ–µ—В –±—Л—В—М –≤–Є–і–Є–Љ–Њ —А–∞–Ј–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –Ј–∞–њ–Є—Б–µ–є –≤ —В–∞–±–ї–Є—Ж–µ!) –љ–µ —Е—А–∞–љ–Є—В—Б—П –≤ –Є–љ–і–µ–Ї—Б–µ, –њ–Њ—Н—В–Њ–Љ—Г, –і–∞–ґ–µ –µ—Б–ї–Є –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –і–ї—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Ј–∞–њ—А–Њ—Б–∞ –Є–љ–і–µ–Ї—Б –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Ї–ї—О—З–∞ —В–∞–±–ї–Є—Ж—Л, –≤—Б—С —А–∞–≤–љ–Њ –њ–Њ—В—А–µ–±—Г–µ—В—Б—П —З—В–µ–љ–Є–µ –Ј–∞–њ–Є—Б–µ–є —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ –Є–Ј —Д–∞–є–ї–∞ —В–∞–±–ї–Є—Ж—Л.
–Я—А–Њ–±–ї–µ–Љ–∞ –Ч–∞–њ—А–Њ—Б –≤–Є–і–∞
![\begin{lstlisting}[language=SQL,label=lst:sql_performance1,caption=SQL]
SELECT count(*) FROM foo;
\end{lstlisting}](postgresql-img4.png)
–Њ—Б—Г—Й–µ—Б—В–≤–ї—П–µ—В –њ–Њ–ї–љ—Л–є –њ—А–Њ—Б–Љ–Њ—В—А —В–∞–±–ї–Є—Ж—Л foo, —З—В–Њ –≤–µ—Б—М–Љ–∞ –і–Њ–ї–≥–Њ –і–ї—П —В–∞–±–ї–Є—Ж —Б –±–Њ–ї—М—И–Є–Љ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ–Љ –Ј–∞–њ–Є—Б–µ–є.
–†–µ—И–µ–љ–Є–µ –Я—А–Њ—Б—В–Њ–≥–Њ —А–µ—И–µ–љ–Є—П –њ—А–Њ–±–ї–µ–Љ—Л, –Ї —Б–Њ–ґ–∞–ї–µ–љ–Є—О, –љ–µ—В. –Т–Њ–Ј–Љ–Њ–ґ–љ—Л —Б–ї–µ–і—Г- —О—Й–Є–µ –њ–Њ–і—Е–Њ–і—Л:
- –Х—Б–ї–Є —В–Њ—З–љ–Њ–µ —З–Є—Б–ї–Њ –Ј–∞–њ–Є—Б–µ–є –љ–µ –≤–∞–ґ–љ–Њ, –∞ –≤–∞–ґ–µ–љ –њ–Њ—А—П–і–Њ–Ї10, —В–Њ –Љ–Њ–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—О –Њ –Ї–Њ–ї–Є—З–µ—Б—В–≤–µ
–Ј–∞–њ–Є—Б–µ–є –≤ —В–∞–±–ї–Є—Ж–µ, —Б–Њ–±—А–∞–љ–љ—Г—О –њ—А–Є –≤—Л–њ–Њ–ї–љ–µ–љ–Є–Є –Ї–Њ–Љ–∞–љ–і—Л ANALYZE:
![\begin{lstlisting}[language=SQL,label=lst:sql_performance2,caption=SQL]
SELECT reltuples FROM pg_class WHERE relname = 'foo';
\end{lstlisting}](postgresql-img5.png)
- –Х—Б–ї–Є –њ–Њ–і–Њ–±–љ—Л–µ –≤—Л–±–Њ—А–Ї–Є –≤—Л–њ–Њ–ї–љ—П—О—В—Б—П —З–∞—Б—В–Њ, –∞ –Є–Ј–Љ–µ–љ–µ–љ–Є—П –≤ —В–∞–±–ї–Є—Ж–µ –і–Њ—Б—В–∞—В–Њ—З–љ–Њ —А–µ–і–Ї–Є, —В–Њ –Љ–Њ–ґ–љ–Њ –Ј–∞–≤–µ—Б—В–Є –≤—Б–њ–Њ–Љ–Њ–≥–∞—В–µ–ї—М–љ—Г—О —В–∞–±–ї–Є—Ж—Г, —Е—А–∞–љ—П—Й—Г—О —З–Є—Б–ї–Њ –Ј–∞–њ–Є—Б–µ–є –≤ –Њ—Б–љ–Њ–≤–љ–Њ–є. –Э–∞ –Њ—Б–љ–Њ–≤–љ—Г—О –ґ–µ —В–∞–±–ї–Є—Ж—Г –њ–Њ–≤–µ—Б–Є—В—М —В—А–Є–≥–≥–µ—А, –Ї–Њ—В–Њ—А—Л–є –±—Г–і–µ—В —Г–Љ–µ–љ—М—И–∞—В—М —Н—В–Њ —З–Є—Б–ї–Њ –≤ —Б–ї—Г—З–∞–µ —Г–і–∞–ї–µ–љ–Є—П –Ј–∞–њ–Є—Б–Є –Є —Г–≤–µ–ї–Є—З–Є–≤–∞—В—М –≤ —Б–ї—Г—З–∞–µ –≤—Б—В–∞–≤–Ї–Є. –Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, –і–ї—П –њ–Њ–ї—Г—З–µ–љ–Є—П –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ –Ј–∞–њ–Є—Б–µ–є –њ–Њ—В—А–µ–±—Г–µ—В—Б—П –ї–Є—И—М –≤—Л–±—А–∞—В—М –Њ–і–љ—Г –Ј–∞–њ–Є—Б—М –Є–Ј –≤—Б–њ–Њ–Љ–Њ–≥–∞—В–µ–ї—М–љ–Њ–є —В–∞–±–ї–Є—Ж—Л.
- –Т–∞—А–Є–∞–љ—В –њ—А–µ–і—Л–і—Г—Й–µ–≥–Њ –њ–Њ–і—Е–Њ–і–∞, –љ–Њ –і–∞–љ–љ—Л–µ –≤–Њ –≤—Б–њ–Њ–Љ–Њ–≥–∞—В–µ–ї—М–љ–Њ–є —В–∞–±–ї–Є—Ж–µ –Њ–±–љ–Њ–≤–ї—П—О—В—Б—П —З–µ—А–µ–Ј –Њ–њ—А–µ–і–µ–ї—С–љ–љ—Л–µ –њ—А–Њ–Љ–µ–ґ—Г—В–Ї–Є –≤—А–µ–Љ–µ–љ–Є (cron).
2 –Ь–µ–і–ї–µ–љ—Л–є DISTINCT
–Ґ–µ–Ї—Г—Й–∞—П —А–µ–∞–ї–Є–Ј–∞—Ж–Є—П DISTINCT –і–ї—П –±–Њ–ї—М—И–Є—Е —В–∞–±–ї–Є—Ж –Њ—З–µ–љ—М –Љ–µ–і–ї–µ–љ–љ–∞. –Э–Њ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М GROUP BY –≤–Ј–∞–Љ–µ–љ DISTINCT. GROUP BY –Љ–Њ–ґ–µ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –∞–≥—А–µ–≥–Є—А—Г—О—Й–Є–є —Е—Н—И, —З—В–Њ –Ј–љ–∞—З–Є—В–µ–ї—М–љ–Њ –±—Л—Б—В—А–µ–µ, —З–µ–Љ DISTINCT.
![\begin{lstlisting}[language=SQL,label=lst:sql_performance3,caption=DISTINCT]
pos...
... from g) a;
count
-------
19125
(1 row)
\par
Time: 36,281 ms
\end{lstlisting}](postgresql-img6.png)
![\begin{lstlisting}[language=SQL,label=lst:sql_performance4,caption=GROUP BY]
pos...
... i) a;
count
-------
19125
(1 row)
\par
Time: 25,270 ms
\par
\end{lstlisting}](postgresql-img7.png)
5 –Ю–њ—В–Є–Љ–Є–Ј–∞—Ж–Є—П –Ј–∞–њ—А–Њ—Б–Њ–≤ —Б –њ–Њ–Љ–Њ—Й—М—О pgFouine
pgFouine11 -- —Н—В–Њ –∞–љ–∞–ї–Є–Ј–∞—В–Њ—А log-—Д–∞–є–ї–Њ–≤ –і–ї—П PostgreSQL, –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ—Л–є –і–ї—П –≥–µ–љ–µ—А–∞—Ж–Є–Є –і–µ—В–∞–ї—М–љ—Л—Е –Њ—В—З–µ—В–Њ–≤ –Є–Ј log-—Д–∞–є–ї–Њ–≤ PostgreSQL. pgFouine –њ–Њ–Љ–Њ–ґ–µ—В –Њ–њ—А–µ–і–µ–ї–Є—В—М, –Ї–∞–Ї–Є–µ –Ј–∞–њ—А–Њ—Б—Л —Б–ї–µ–і—Г–µ—В –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞—В—М –≤ –њ–µ—А–≤—Г—О –Њ—З–µ—А–µ–і—М. pgFouine –љ–∞–њ–Є—Б–∞–љ –љ–∞ —П–Ј—Л–Ї–µ –њ—А–Њ–≥—А–∞–Љ–Љ–Є—А–Њ–≤–∞–љ–Є—П PHP —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ –Њ–±—К–µ–Ї—В–љ–Њ-–Њ—А–Є–µ–љ—В–Є—А–Њ–≤–∞–љ–љ—Л—Е —В–µ—Е–љ–Њ–ї–Њ–≥–Є–є –Є –ї–µ–≥–Ї–Њ —А–∞—Б—И–Є—А—П–µ—В—Б—П –і–ї—П –њ–Њ–і–і–µ—А–ґ–Ї–Є —Б–њ–µ—Ж–Є–∞–ї–Є–Ј–Є—А–Њ–≤–∞–љ–љ—Л—Е –Њ—В—З–µ—В–Њ–≤, —П–≤–ї—П–µ—В—Б—П —Б–≤–Њ–±–Њ–і–љ—Л–Љ –њ—А–Њ–≥—А–∞–Љ–Љ–љ—Л–Љ –Њ–±–µ—Б–њ–µ—З–µ–љ–Є–µ–Љ –Є —А–∞—Б–њ—А–Њ—Б—В—А–∞–љ—П–µ—В—Б—П –љ–∞ —Г—Б–ї–Њ–≤–Є—П—Е GNU General Public License. –£—В–Є–ї–Є—В–∞ —Б–њ—А–Њ–µ–Ї—В–Є—А–Њ–≤–∞–љ–∞ —В–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, —З—В–Њ–±—Л –Њ–±—А–∞–±–Њ—В–Ї–∞ –Њ—З–µ–љ—М –±–Њ–ї—М—И–Є—Е log-—Д–∞–є–ї–Њ–≤ –љ–µ —В—А–µ–±–Њ–≤–∞–ї–∞ –Љ–љ–Њ–≥–Њ —А–µ—Б—Г—А—Б–Њ–≤.–Ф–ї—П —А–∞–±–Њ—В—Л —Б pgFouine —Б–љ–∞—З–∞–ї–∞ –љ—Г–ґ–љ–Њ —Б–Ї–Њ–љ—Д–Є–≥—Г—А–Є—А–Њ–≤–∞—В—М PostgreSQL –і–ї—П —Б–Њ–Ј–і–∞–љ–Є—П –љ—Г–ґ–љ–Њ–≥–Њ —Д–Њ—А–Љ–∞—В–∞ log-—Д–∞–є–ї–Њ–≤:
- –І—В–Њ–±—Л –≤–Ї–ї—О—З–Є—В—М –њ—А–Њ—В–Њ–Ї–Њ–ї–Є—А–Њ–≤–∞–љ–Є–µ –≤ syslog
![\begin{lstlisting}[label=lst:sql_performance5,caption=pgFouine]
log_destination = 'syslog'
redirect_stderr = off
silent_mode = on
\end{lstlisting}](postgresql-img8.png)
- –Ф–ї—П –Ј–∞–њ–Є—Б–Є –Ј–∞–њ—А–Њ—Б–Њ–≤, –і–ї—П—Й–Є—Е—Б—П –і–Њ–ї—М—И–µ n –Љ–Є–ї–ї–Є—Б–µ–Ї—Г–љ–і:
![\begin{lstlisting}[label=lst:sql_performance6,caption=pgFouine]
log_min_duration_statement = n
log_duration = off
log_statement = 'none'
\end{lstlisting}](postgresql-img9.png)
–Ф–ї—П –Ј–∞–њ–Є—Б–Є –Ї–∞–ґ–і–Њ–≥–Њ –Њ–±—А–∞–±–Њ—В–∞–љ–љ–Њ–≥–Њ –Ј–∞–њ—А–Њ—Б–∞ —Г—Б—В–∞–љ–Њ–≤–Є—В–µ log_min_duration_statement –љ–∞ 0. –І—В–Њ–±—Л –Њ—В–Ї–ї—О—З–Є—В—М –Ј–∞–њ–Є—Б—М –Ј–∞–њ—А–Њ—Б–Њ–≤, —Г—Б—В–∞–љ–Њ–≤–Є—В–µ —Н—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А –љ–∞ -1.
pgFouine -- –њ—А–Њ—Б—В–Њ–є –≤ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–Є –Є–љ—Б—В—А—Г–Љ–µ–љ—В –Ї–Њ–Љ–∞–љ–і–љ–Њ–є —Б—В—А–Њ–Ї–Є. –°–ї–µ–і—Г—О—Й–∞—П –Ї–Њ–Љ–∞–љ–і–∞ —Б–Њ–Ј–і–∞—С—В
HTML-–Њ—В—З—С—В —Б–Њ —Б—В–∞–љ–і–∞—А—В–љ—Л–Љ–Є –њ–∞—А–∞–Љ–µ—В—А–∞–Љ–Є:
![\begin{lstlisting}[label=lst:sql_performance7,caption=pgFouine]
pgfouine.php -file your/log/file.log > your-report.html
\end{lstlisting}](postgresql-img10.png)
–° –њ–Њ–Љ–Њ—Й—М—О —Н—В–Њ–є —Б—В—А–Њ–Ї–Є –Љ–Њ–ґ–љ–Њ –Њ—В–Њ–±—А–∞–Ј–Є—В—М —В–µ–Ї—Б—В–Њ–≤—Л–є –Њ—В—З—С—В —Б 10 –Ј–∞–њ—А–Њ—Б–∞–Љ–Є –љ–∞ –Ї–∞–ґ–і—Л–є —Н–Ї—А–∞–љ –љ–∞ —Б—В–∞–љ–і–∞—А—В–љ–Њ–Љ –≤—Л–≤–Њ–і–µ:
![\begin{lstlisting}[label=lst:sql_performance8,caption=pgFouine]
pgfouine.php -file your/log/file.log -top 10 -format text
\end{lstlisting}](postgresql-img11.png)
–С–Њ–ї–µ–µ –њ–Њ–і—А–Њ–±–љ–Њ –Њ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—П—Е, –∞ —В–∞–Ї–ґ–µ –Љ–љ–Њ–≥–Њ –њ–Њ–ї–µ–Ј–љ—Л—Е –њ—А–Є–Љ–µ—А–Њ–≤, –Љ–Њ–ґ–љ–Њ –љ–∞–є—В–Є –љ–∞ –Њ—Д–Є—Ж–Є–∞–ї—М–љ–Њ–Љ —Б–∞–є—В–∞ –њ—А–Њ–µ–Ї—В–∞ -- http://pgfouine.projects.postgresql.org.
7 –Ч–∞–Ї–ї—О—З–µ–љ–Є–µ
–Ъ —Б—З–∞—Б—В—М—О, PostgreSQL –љ–µ —В—А–µ–±—Г–µ—В –Њ—Б–Њ–±–Њ —Б–ї–Њ–ґ–љ–Њ–є –љ–∞—Б—В—А–Њ–є–Ї–Є. –Т –±–Њ–ї—М—И–Є–љ—Б—В–≤–µ —Б–ї—Г—З–∞–µ–≤ –≤–њ–Њ–ї–љ–µ –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –±—Г–і–µ—В —Г–≤–µ–ї–Є—З–Є—В—М –Њ–±—К—С–Љ –≤—Л–і–µ–ї–µ–љ–љ–Њ–є –њ–∞–Љ—П—В–Є, –љ–∞—Б—В—А–Њ–Є—В—М –њ–µ—А–Є–Њ–і–Є—З–µ—Б–Ї–Њ–µ –њ–Њ–і–і–µ—А–ґ–∞–љ–Є–µ –±–∞–Ј—Л –≤ –њ–Њ—А—П–і–Ї–µ –Є –њ—А–Њ–≤–µ—А–Є—В—М –љ–∞–ї–Є—З–Є–µ –љ–µ–Њ–±—Е–Њ–і–Є–Љ—Л—Е –Є–љ–і–µ–Ї—Б–Њ–≤. –С–Њ–ї–µ–µ —Б–ї–Њ–ґ–љ—Л–µ –≤–Њ–њ—А–Њ—Б—Л –Љ–Њ–ґ–љ–Њ –Њ–±—Б—Г–і–Є—В—М –≤ —Б–њ–µ—Ж–Є–∞–ї–Є–Ј–Є—А–Њ–≤–∞–љ–љ–Њ–Љ —Б–њ–Є—Б–Ї–µ —А–∞—Б—Б—Л–ї–Ї–Є.3 –Я–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ

1 –Т–≤–µ–і–µ–љ–Є–µ
–Я–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ (partitioning, —Б–µ–Ї—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ) -- —Н—В–Њ —А–∞–Ј–±–Є–µ–љ–Є–µ –±–Њ–ї—М—И–Є—Е —Б—В—А—Г–Ї—В—Г—А –±–∞–Ј –і–∞–љ–љ—Л—Е (—В–∞–±–ї–Є—Ж—Л, –Є–љ–і–µ–Ї—Б—Л) —А–∞–Ј–±–Є—В—М –љ–∞ –Љ–µ–љ—М—И–Є–µ –Ї—Г—Б–Њ—З–Ї–Є. –Ч–≤—Г—З–Є—В —Б–ї–Њ–ґ–љ–Њ, –љ–Њ –љ–∞ –њ—А–∞–Ї—В–Є–Ї–µ –≤—Б–µ –њ—А–Њ—Б—В–Њ.–°–Ї–Њ—А–µ–µ –≤—Б–µ–≥–Њ —Г –Т–∞—Б –µ—Б—В—М –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –Њ–≥—А–Њ–Љ–љ—Л—Е —В–∞–±–ї–Є—Ж (–Њ–±—Л—З–љ–Њ –≤—Б—О –љ–∞–≥—А—Г–Ј–Ї—Г –Њ–±–µ—Б–њ–µ—З–Є–≤–∞—О—В –≤—Б–µ–≥–Њ –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ —В–∞–±–ї–Є—Ж –°–£–С–Ф –Є–Ј –≤—Б–µ—Е –Є–Љ–µ—О—Й–Є—Е—Б—П). –Я—А–Є—З–µ–Љ —З—В–µ–љ–Є–µ –≤ –±–Њ–ї—М—И–Є–љ—Б—В–≤–µ —Б–ї—Г—З–∞–µ–≤ –њ—А–Є—Е–Њ–і–Є—В—Б—П —В–Њ–ї—М–Ї–Њ –љ–∞ —Б–∞–Љ—Г—О –њ–Њ—Б–ї–µ–і–љ—О—О –Є—Е —З–∞—Б—В—М (—В.–µ. –∞–Ї—В–Є–≤–љ–Њ —З–Є—В–∞—О—В—Б—П —В–µ –і–∞–љ–љ—Л–µ, –Ї–Њ—В–Њ—А—Л–µ –љ–µ–і–∞–≤–љ–Њ –њ–Њ—П–≤–Є–ї–Є—Б—М). –Я—А–Є–Љ–µ—А–Њ–Љ —В–Њ–Љ—Г –Љ–Њ–ґ–µ—В —Б–ї—Г–ґ–Є—В—М –±–ї–Њ–≥ -- –љ–∞ –њ–µ—А–≤—Г—О —Б—В—А–∞–љ–Є—Ж—Г (—Н—В–Њ –њ–Њ—Б–ї–µ–і–љ–Є–µ 5...10 –њ–Њ—Б—В–Њ–≤) –њ—А–Є—Е–Њ–і–Є—В—Б—П 40...50% –≤—Б–µ–є –љ–∞–≥—А—Г–Ј–Ї–Є, –Є–ї–Є –љ–Њ–≤–Њ—Б—В–љ–Њ–є –њ–Њ—А—В–∞–ї (—Б—Г—В—М –Њ–і–љ–∞ –Є —В–∞ –ґ–µ), –Є–ї–Є —Б–Є—Б—В–µ–Љ—Л –ї–Є—З–љ—Л—Е —Б–Њ–Њ–±—Й–µ–љ–Є–євА¶ –≤–њ—А–Њ—З–µ–Љ –њ–Њ–љ—П—В–љ–Њ. –Я–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ —В–∞–±–ї–Є—Ж—Л –њ–Њ–Ј–≤–Њ–ї—П–µ—В –±–∞–Ј–µ –і–∞–љ–љ—Л—Е –і–µ–ї–∞—В—М –Є–љ—В–µ–ї–ї–µ–Ї—В—Г–∞–ї—М–љ—Г—О –≤—Л–±–Њ—А–Ї—Г -- —Б–љ–∞—З–∞–ї–∞ –°–£–С–Ф —Г—В–Њ—З–љ–Є—В, –Ї–∞–Ї–Њ–є –њ–∞—А—В–Є—Ж–Є–Є —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –Т–∞—И –Ј–∞–њ—А–Њ—Б (–µ—Б–ї–Є —Н—В–Њ —А–µ–∞–ї—М–љ–Њ) –Є —В–Њ–ї—М–Ї–Њ –њ–Њ—В–Њ–Љ —Б–і–µ–ї–∞–µ—В —Н—В–Њ—В –Ј–∞–њ—А–Њ—Б, –њ—А–Є–Љ–µ–љ–Є—В–µ–ї—М–љ–Њ –Ї –љ—Г–ґ–љ–Њ–є –њ–∞—А—В–Є—Ж–Є–Є (–Є–ї–Є –љ–µ—Б–Ї–Њ–ї—М–Ї–Є–Љ –њ–∞—А—В–Є—Ж–Є—П–Љ). –Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, –≤ —А–∞—Б—Б–Љ–Њ—В—А–µ–љ–љ–Њ–Љ —Б–ї—Г—З–∞–µ, –Т—Л —А–∞—Б–њ—А–µ–і–µ–ї–Є—В–µ –љ–∞–≥—А—Г–Ј–Ї—Г –љ–∞ —В–∞–±–ї–Є—Ж—Г –њ–Њ –µ–µ –њ–∞—А—В–Є—Ж–Є—П–Љ. –°–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ–Њ –≤—Л–±–Њ—А–Ї–∞ —В–Є–њ–∞ «SELECT * FROM articles ORDER BY id DESC LIMIT 10» –±—Г–і–µ—В –≤—Л–њ–Њ–ї–љ—П—В—М—Б—П —В–Њ–ї—М–Ї–Њ –љ–∞–і –њ–Њ—Б–ї–µ–і–љ–µ–є –њ–∞—А—В–Є—Ж–Є–µ–є, –Ї–Њ—В–Њ—А–∞—П –Ј–љ–∞—З–Є—В–µ–ї—М–љ–Њ –Љ–µ–љ—М—И–µ –≤—Б–µ–є —В–∞–±–ї–Є—Ж—Л.
–Ш—В–∞–Ї, –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ –і–∞–µ—В —А—П–і –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤:
- –Э–∞ –Њ–њ—А–µ–і–µ–ї–µ–љ–љ—Л–µ –≤–Є–і—Л –Ј–∞–њ—А–Њ—Б–Њ–≤ (–Ї–Њ—В–Њ—А—Л–µ, –≤ —Б–≤–Њ—О –Њ—З–µ—А–µ–і—М, —Б–Њ–Ј–і–∞—О—В –Њ—Б–љ–Њ–≤–љ—Г—О –љ–∞–≥—А—Г–Ј–Ї—Г –љ–∞ –°–£–С–Ф) –Љ—Л –Љ–Њ–ґ–µ–Љ —Г–ї—Г—З—И–Є—В—М –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М.
- –Ь–∞—Б—Б–Њ–≤–Њ–µ —Г–і–∞–ї–µ–љ–Є–µ –Љ–Њ–ґ–µ—В –±—Л—В—М –њ—А–Њ–Є–Ј–≤–µ–і–µ–љ–Њ –њ—Г—В–µ–Љ —Г–і–∞–ї–µ–љ–Є—П –Њ–і–љ–Њ–є –Є–ї–Є –љ–µ—Б–Ї–Њ–ї—М–Ї–Є—Е –њ–∞—А—В–Є—Ж–Є–є (DROP TABLE –≥–Њ—А–∞–Ј–і–Њ –±—Л—Б—В—А–µ–µ, —З–µ–Љ –Љ–∞—Б—Б–Њ–≤—Л–є DELETE).
- –†–µ–і–Ї–Њ –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ—Л–µ –і–∞–љ–љ—Л–µ –Љ–Њ–≥—Г—В –±—Л—В—М –њ–µ—А–µ–љ–µ—Б–µ–љ—Л –≤ –і—А—Г–≥–Њ–µ —Е—А–∞–љ–Є–ї–Є—Й–µ.
2 –Ґ–µ–Њ—А–Є—П
–Э–∞ —В–µ–Ї—Г—Й–Є–є –Љ–Њ–Љ–µ–љ—В PostgreSQL –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В –і–≤–∞ –Ї—А–Є—В–µ—А–Є—П –і–ї—П —Б–Њ–Ј–і–∞–љ–Є—П –њ–∞—А—В–Є—Ж–Є–є:- –Я–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ –њ–Њ –і–Є–∞–њ–∞–Ј–Њ–љ—Г –Ј–љ–∞—З–µ–љ–Є–є (range) -- —В–∞–±–ї–Є—Ж–∞ —А–∞–Ј–±–Є–≤–∞–µ—В—Б—П –љ–∞ «–і–Є–∞–њ–∞–Ј–Њ–љ—Л» –Ј–љ–∞—З–µ–љ–Є–є –њ–Њ –њ–Њ–ї—О –Є–ї–Є –љ–∞–±–Њ—А—Г –њ–Њ–ї–µ–є –≤ —В–∞–±–ї–Є—Ж–µ, –±–µ–Ј –њ–µ—А–µ–Ї—А—Л—В–Є—П –і–Є–∞–њ–∞–Ј–Њ–љ–Њ–≤ –Ј–љ–∞—З–µ–љ–Є–є, –Њ—В–љ–µ—Б–µ–љ–љ—Л—Е –Ї —А–∞–Ј–ї–Є—З–љ—Л–Љ –њ–∞—А—В–Є—Ж–Є—П–Љ. –Э–∞–њ—А–Є–Љ–µ—А, –і–Є–∞–њ–∞–Ј–Њ–љ—Л –і–∞—В.
- –Я–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ –њ–Њ —Б–њ–Є—Б–Ї—Г –Ј–љ–∞—З–µ–љ–Є–є (list) -- —В–∞–±–ї–Є—Ж–∞ —А–∞–Ј–±–Є–≤–∞–µ—В—Б—П –њ–Њ —Б–њ–Є—Б–Ї–∞–Љ –Ї–ї—О—З–µ–≤—Л–µ –Ј–љ–∞—З–µ–љ–Є—П –і–ї—П –Ї–∞–ґ–і–Њ–є –њ–∞—А—В–Є—Ж–Є–Є.
–І—В–Њ–±—Л –љ–∞—Б—В—А–Њ–Є—В—М –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ —В–∞–±–ї–Є—Ж–Є, –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –≤—Л–њ–Њ–ї–љ–Є—В–µ —Б–ї–µ–і—Г—О—Й–Є–µ –і–µ–є—Б—В–≤–Є—П:
- –°–Њ–Ј–і–∞–µ—В—Б—П «–Љ–∞—Б—В–µ—А» —В–∞–±–ї–Є—Ж–∞, –Є–Ј –Ї–Њ—В–Њ—А–Њ–є –≤—Б–µ –њ–∞—А—В–Є—Ж–Є–Є –±—Г–і—Г—В –љ–∞—Б–ї–µ–і–Њ–≤–∞—В—М—Б—П. –≠—В–∞ —В–∞–±–ї–Є—Ж–∞ –љ–µ –±—Г–і–µ—В —Б–Њ–і–µ—А–ґ–∞—В—М –і–∞–љ–љ—Л–µ. –Ґ–∞–Ї –ґ–µ –љ–µ –љ—Г–ґ–љ–Њ —Б—В–∞–≤–Є—В—М –љ–Є–Ї–∞–Ї–Є—Е –Њ–≥—А–∞–љ–Є—З–µ–љ–Є–є –љ–∞ —В–∞–±–ї–Є—Ж—Г, –µ—Б–ї–Є –Ї–Њ–љ–µ—З–љ–Њ –Њ–љ–Є –љ–µ –±—Г–і—Г—В –і—Г–±–ї–Є—А–Њ–≤–∞—В—Б—П –љ–∞ –њ–∞—А—В–Є—Ж–Є–Є.
- –°–Њ–Ј–і–∞–є—В–µ –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ «–і–Њ—З–µ—А–љ–Є—Е» —В–∞–±–ї–Є—Ж, –Ї–Њ—В–Њ—А—Л–µ –љ–∞—Б–ї–µ–і—Г—О—В –Њ—В «–Љ–∞—Б—В–µ—А» —В–∞–±–ї–Є—Ж—Л.
- –Ф–Њ–±–∞–≤–Є—В—М –≤ «–і–Њ—З–µ—А–љ–Є–µ» —В–∞–±–ї–Є—Ж—Л –Ј–љ–∞—З–µ–љ–Є—П, –њ–Њ –Ї–Њ—В–Њ—А—Л–Љ –Њ–љ–Є –±—Г–і—Г—В –њ–∞—А—В–Є—Ж–Є—П–Љ–Є.
–°—В–Њ–Є—В—М –Ј–∞–Љ–µ—В–Є—В—М, —З—В–Њ –Ј–љ–∞—З–µ–љ–Є—П –њ–∞—А—В–Є—Ж–Є–є –љ–µ –і–Њ–ї–ґ–љ—Л –њ–µ—А–µ—Б–µ–Ї–∞—В—Б—П. –Э–∞–њ—А–Є–Љ–µ—А:

–љ–µ–≤–µ—А–љ–Њ –Ј–∞–і–∞–љ—Л –њ–∞—А—В–Є—Ж–Є–Є, –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г –љ–µ –њ–Њ–љ—П—В–љ–Њ –Ї–∞–Ї–Њ–є –њ–∞—А—В–Є—Ж–Є–Є –њ—А–µ–љ–∞–і–ї–µ–ґ–Є—В –Ј–љ–∞—З–µ–љ–Є–µ 200. - –Ф–ї—П –Ї–∞–ґ–і–Њ–є –њ–∞—А—В–Є—Ж–Є–Є —Б–Њ–Ј–і–∞—В—М –Є–љ–і–µ–Ї—Б –њ–Њ –Ї–ї—О—З–µ–≤–Њ–Љ—Г –њ–Њ–ї—О (–Є–ї–Є –љ–µ—Б–Ї–Њ–ї—М–Ї–Є–Љ), –∞ —В–∞–Ї–ґ–µ —Г–Ї–∞–Ј–∞—В—М –ї—О–±—Л–µ –і—А—Г–≥–Є–µ —В—А–µ–±—Г–µ–Љ—Л–µ –Є–љ–і–µ–Ї—Б—Л.
- –Я—А–Є –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ—Б—В–Є, —Б–Њ–Ј–і–∞—В—М —В—А–Є–≥–≥–µ—А –Є–ї–Є –њ—А–∞–≤–Є–ї–Њ –і–ї—П –њ–µ—А–µ–љ–∞–њ—А–∞–≤–ї–µ–љ–Є—П –і–∞–љ–љ—Л—Е —Б «–Љ–∞—Б—В–µ—А» —В–∞–±–ї–Є—Ж–Є –≤ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й—Г—О –њ–∞—А—В–Є—Ж–Є—О.
- –£–±–µ–і–Є—В—М—Б—П, —З—В–Њ –њ–∞—А–∞–Љ–µ—В—А «constraint_exclusion» –љ–µ –Њ—В–Ї–ї—О—З–µ–љ –≤ postgresql.conf. –Х—Б–ї–Є –µ–≥–Њ –љ–µ –≤–Ї–ї—О—З–Є—В—М, —В–Њ –Ј–∞–њ—А–Њ—Б—Л –љ–µ –±—Г–і—Г—В –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞–љ—Л –њ—А–Є —А–∞–±–Њ—В–µ —Б –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ.
3 –Я—А–∞–Ї—В–Є–Ї–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П
–Ґ–µ–њ–µ—А—М –љ–∞—З–љ–µ–Љ —Б –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–Њ–≥–Њ –њ—А–Є–Љ–µ—А–∞. –Я—А–µ–і—Б—В–∞–≤–Є–Љ, —З—В–Њ –≤ –љ–∞—И–µ–є —Б–Є—Б—В–µ–Љ–µ –µ—Б—В—М —В–∞–±–ї–Є—Ж–∞, –≤ –Ї–Њ—В–Њ—А—Г—О –Љ—Л —Б–Њ–±–Є—А–∞–µ–Љ –і–∞–љ–љ—Л–µ –Њ –њ–Њ—Б–µ—Й–∞–µ–Љ–Њ—Б—В–Є –љ–∞—И–µ–≥–Њ —А–µ—Б—Г—А—Б–∞. –Э–∞ –ї—О–±–Њ–є –Ј–∞–њ—А–Њ—Б –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П –љ–∞—И–∞ —Б–Є—Б—В–µ–Љ–∞ –ї–Њ–≥–Є—А—Г–µ—В –і–µ–є—Б—В–≤–Є—П –≤ —Н—В—Г —В–∞–±–ї–Є—Ж—Г. –Ш, –љ–∞–њ—А–Є–Љ–µ—А, –≤ –љ–∞—З–∞–ї–µ –Ї–∞–ґ–і–Њ–≥–Њ –Љ–µ—Б—П—Ж–∞ (–љ–µ–і–µ–ї—О) –љ–∞–Љ –љ—Г–ґ–љ–Њ —Б–Њ–Ј–і–∞–≤–∞—В—М –Њ—В—З–µ—В –Ј–∞ –њ—А–µ–і—Л–і—Г—Й–Є–є –Љ–µ—Б—П—Ж (–љ–µ–і–µ–ї—О). –Я—А–Є —Н—В–Њ–Љ, –ї–Њ–≥–Є –љ—Г–ґ–љ–Њ —Е—А–∞–љ–Є—В—М –≤ —В–µ—З–µ–љ–Є–Є 3 –ї–µ—В. –Ф–∞–љ–љ—Л–µ –≤ —В–∞–Ї–Њ–є —В–∞–±–ї–Є—Ж–µ –љ–∞–Ї–∞–њ–ї–Є–≤–∞—О—В—Б—П –±—Л—Б—В—А–Њ, –µ—Б–ї–Є —Б–Є—Б—В–µ–Љ–∞ –∞–Ї—В–Є–≤–љ–Њ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П. –Ш –≤–Њ—В, –Ї–Њ–≥–і–∞ —В–∞–±–ї–Є—Ж–∞ —Г–ґ–µ —Б –Љ–Є–ї–Є–Њ–љ–∞–Љ–Є, –∞ —В–Њ, –Є –Љ–Є–ї–Є–∞—А–і–∞–Љ–Є –Ј–∞–њ–Є—Б–µ–є, —Б–Њ–Ј–і–∞–≤–∞—В—М –Њ—В—З–µ—В—Л —Б—В–∞–љ–Њ–≤–Є—В—Б—П –≤—Б–µ —Б–ї–Њ–ґ–љ–µ–µ (–і–∞ –Є —З–Є—Б—В–Ї–∞ —Б—В–∞—А—Л—Е –Ј–∞–њ–Є—Б–µ–є —Б—В–∞–љ–Њ–≤–Є—В—Б—П –љ–µ –ї–µ–≥–Ї–Є–Љ –і–µ–ї–Њ–Љ). –†–∞–±–Њ—В–∞ —Б —В–∞–Ї–Њ–є —В–∞–±–ї–Є—Ж–µ–є —Б–Њ–Ј–і–∞–µ—В –Њ–≥—А–Њ–Љ–љ—Г—О –љ–∞–≥—А—Г–Ј–Ї—Г –љ–∞ –°–£–С–Ф. –Ґ—Г—В –љ–∞–Љ –љ–∞ –њ–Њ–Љ–Њ—Й—М –Є –њ—А–Є—Е–Њ–і–Є—В –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ.
1 –Э–∞—Б—В—А–Њ–є–Ї–∞
–Ф–ї—П –њ—А–Є–Љ–µ—А–∞, –Љ—Л –Є–Љ–µ–µ–Љ —Б–ї–µ–і—Г—О—Й–Є—О —В–∞–±–ї–Є—Ж—Г: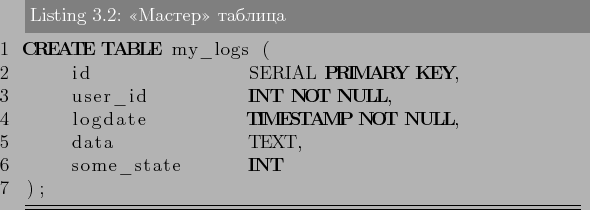
–Я–Њ—Б–Ї–Њ–ї—М–Ї—Г –љ–∞–Љ –љ—Г–ґ–љ—Л –Њ—В—З–µ—В—Л –Ї–∞–ґ–і—Л–є –Љ–µ—Б—П—Ж, –Љ—Л –±—Г–і–µ–Љ –і–µ–ї–Є—В—М –њ–∞—А—В–Є—Ж–Є–Є –њ–Њ –Љ–µ—Б—П—Ж–∞–Љ. –≠—В–Њ –њ–Њ–Љ–Њ–ґ–µ—В –љ–∞–Љ –±—Л—Б—В—А–µ–µ —Б–Њ–Ј–і–∞–≤–∞—В—М –Њ—В—З–µ—В—Л –Є —З–Є—Б—В–Є—В—М —Б—В–∞—А—Л–µ –і–∞–љ–љ—Л–µ.
«–Ь–∞—Б—В–µ—А» —В–∞–±–ї–Є—Ж–∞ –±—Г–і–µ—В «my_logs», —Б—В—А—Г–Ї—В—Г—А—Г –Ї–Њ—В–Њ—А–Њ–є –Љ—Л —Г–Ї–∞–Ј–∞–ї–Є –≤—Л—И–µ. –Ф–∞–ї–µ–µ —Б–Њ–Ј–і–∞–і–Є–Љ «–і–Њ—З–µ—А–љ–Є–µ» —В–∞–±–ї–Є—Ж–Є (–њ–∞—А—В–Є—Ж–Є–Є):
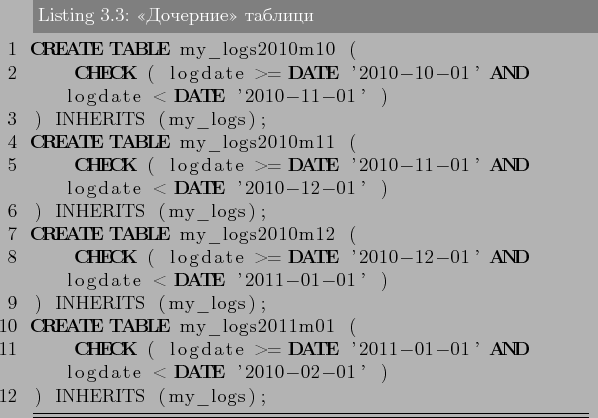
–Ф–∞–љ–љ—Л–Љ–Є –Ї–Њ–Љ–∞–љ–і–∞–Љ–Є –Љ—Л —Б–Њ–Ј–і–∞–µ–Љ —В–∞–±–ї–Є—Ж—Л «my_logs2010m10», «my_logs2010m11» –Є —В.–і., –Ї–Њ—В–Њ—А—Л–µ –Ї–Њ–њ–Є—А—Г—О—В —Б—В—А—Г–Ї—В—Г—А—Г —Б «–Љ–∞—Б—В–µ—А»
—В–∞–±–ї–Є—Ж–Є (–Ї—А–Њ–Љ–µ –Є–љ–і–µ–Ї—Б–Њ–≤). –Ґ–∞–Ї–ґ–µ —Б –њ–Њ–Љ–Њ—Й—М—О «CHECK» –Љ—Л –Ј–∞–і–∞–µ–Љ –і–Є–∞–њ–∞–Ј–Њ–љ –Ј–љ–∞—З–µ–љ–Є–є, –Ї–Њ—В–Њ—А—Л–є –±—Г–і–µ—В –њ–Њ–њ–∞–і–∞—В—М –≤ —Н—В—Г –њ–∞—А—В–Є—Ж–Є—О
(—Е–Њ—З—Г –Њ–њ—П—В—М –љ–∞–њ–Њ–Љ–љ–Є—В—М, —З—В–Њ –і–Є–∞–њ–∞–Ј–Њ–љ—Л –Ј–љ–∞—З–µ–љ–Є–є –њ–∞—А—В–Є—Ж–Є–є –љ–µ –і–Њ–ї–ґ–љ—Л –њ–µ—А–µ—Б–µ–Ї–∞—В—Б—П!). –Я–Њ—Б–Ї–Њ–ї—М–Ї—Г –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ –±—Г–і–µ—В —А–∞–±–Њ—В–∞—В—М
–њ–Њ –њ–Њ–ї—О «logdate», –Љ—Л —Б–Њ–Ј–і–∞–і–Є–Љ –Є–љ–і–µ–Ї—Б –љ–∞ —Н—В–Њ –њ–Њ–ї–µ –љ–∞ –≤—Б–µ—Е –њ–∞—А—В–Є—Ж–Є—П—Е:
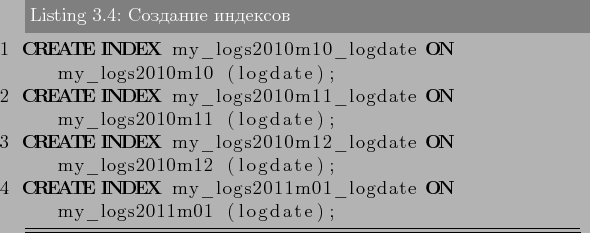
–Ф–∞–ї–µ–µ –і–ї—П —Г–і–Њ–±—Б—В–≤–∞ —Б–Њ–Ј–і–∞–і–Є–Љ —Д—Г–љ–Ї—Ж–Є—О, –Ї–Њ—В–Њ—А–∞—П –±—Г–і–µ—В –њ–µ—А–µ–љ–∞–њ—А–∞–≤–ї—П—В—М –љ–Њ–≤—Л–µ –і–∞–љ–љ—Л–µ —Б «–Љ–∞—Б—В–µ—А» —В–∞–±–ї–Є—Ж–Є –≤ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й—Г—О –њ–∞—А—В–Є—Ж–Є—О.

–Т —Д—Г–љ–Ї—Ж–Є–Є –љ–Є—З–µ–≥–Њ –Њ—Б–Њ–±–µ–љ–љ–Њ–≥–Њ –љ–µ—В: –Є–і–µ—В –њ—А–Њ–≤–µ—А–Ї–∞ –њ–Њ–ї—П «logdate», –њ–Њ –Ї–Њ—В–Њ—А–Њ–є –љ–∞–њ—А–∞–≤–ї—П—О—В—Б—П –і–∞–љ–љ—Л–µ –≤ –љ—Г–ґ–љ—Г—О –њ–∞—А—В–Є—Ж–Є—О.
–Я—А–Є –љ–µ –љ–∞—Е–Њ–ґ–і–µ–љ–Є–Є —В—А–µ–±—Г–µ–Љ–Њ–є –њ–∞—А—В–Є—Ж–Є–Є -- –≤—Л–Ј—Л–≤–∞–µ–Љ –Њ—И–Є–±–Ї—Г. –Ґ–µ–њ–µ—А—М –Њ—Б—В–∞–ї–Њ—Б—М —Б–Њ–Ј–і–∞—В—М —В—А–Є–≥–≥–µ—А –љ–∞ «–Љ–∞—Б—В–µ—А» —В–∞–±–ї–Є—Ж—Г
–і–ї—П –∞–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Њ–≥–Њ –≤—Л–Ј–Њ–≤–∞ –і–∞–љ–љ–Њ–є —Д—Г–љ–Ї—Ж–Є–Є:
![\begin{lstlisting}[language=SQL,label=lst:partitioning6,caption=–Ґ—А–Є–≥–≥–µ—А]
...
..._logs
FOR EACH ROW EXECUTE PROCEDURE my_logs_insert_trigger();
\end{lstlisting}](postgresql-img18.png)
–Я–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ –љ–∞—Б—В—А–Њ–µ–љ–Њ –Є —В–µ–њ–µ—А—М –Љ—Л –≥–Њ—В–Њ–≤—Л –њ—А–Є—Б—В—Г–њ–Є—В—М –Ї —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є—О.
2 –Ґ–µ—Б—В–Є—А–Њ–≤–∞–љ–Є–µ
–Ф–ї—П –љ–∞—З–∞–ї–∞ –і–Њ–±–∞–≤–Є–Љ –і–∞–љ–љ—Л–µ –≤ –љ–∞—И—Г —В–∞–±–ї–Є—Ж—Г «my_logs»:![\begin{lstlisting}[language=SQL,label=lst:partitioning7,caption=–Ф–∞–љ–љ—Л–µ]
IN...
...ta, some_state) VALUES(1, '2010-12-15', '15.12.2010 data3', 1);
\end{lstlisting}](postgresql-img19.png)
–Ґ–µ–њ–µ—А—М –њ—А–Њ–≤–µ—А–Є–Љ –≥–і–µ –Њ–љ–Є —Е—А–∞–љ—П—В—Б—П:

–Ъ–∞–Ї –≤–Є–і–Є–Љ –≤ «–Љ–∞—Б—В–µ—А» —В–∞–±–ї–Є—Ж—Г –і–∞–љ–љ—Л–µ –љ–µ –њ–Њ–њ–∞–ї–Є -- –Њ–љ–∞ —З–Є—Б—В–∞. –Ґ–µ–њ–µ—А—М –њ—А–Њ–≤–µ—А–Є–Љ –∞ –µ—Б—В—М –ї–Є –≤–Њ–Њ–±—Й–µ –і–∞–љ–љ—Л–µ:
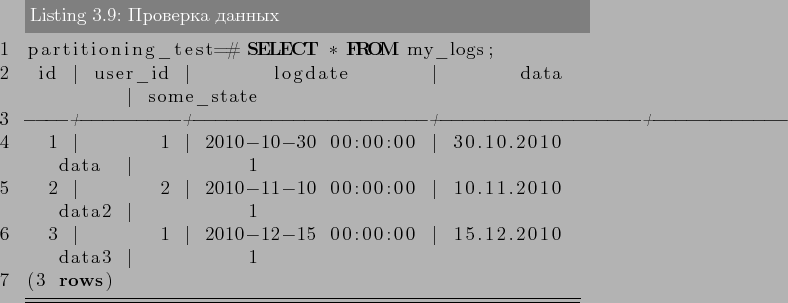
–Ф–∞–љ–љ—Л–µ –њ—А–Є —Н—В–Њ–Љ –≤—Л–≤–Њ–і—П—В—Б—П –±–µ–Ј –њ—А–Њ–±–ї–µ–Љ. –Я—А–Њ–≤–µ—А–Є–Љ –њ–∞—А—В–Є—Ж–Є–Є, –њ—А–∞–≤–Є–ї—М–љ–Њ –ї–Є —Е—А–∞–љ—П—В—Б—П –і–∞–љ–љ—Л–µ:
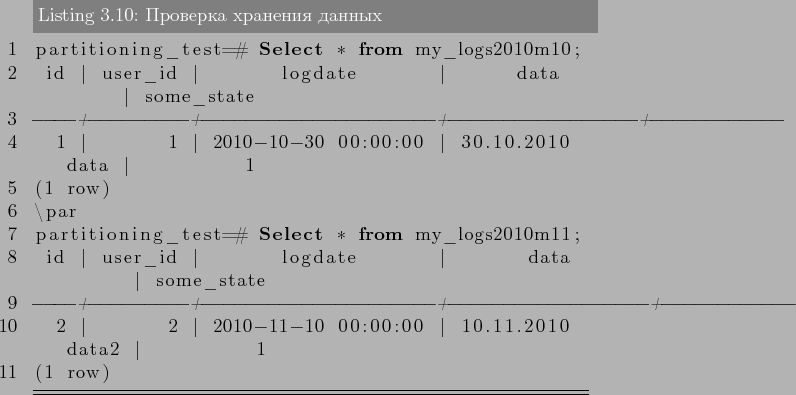
–Ю—В–ї–Є—З–љ–Њ! –Ф–∞–љ–љ—Л–µ —Е—А–∞–љ—П—В—Б—П –љ–∞ —В—А–µ–±—Г–µ–Љ—Л—Е –љ–∞–Љ –њ–∞—А—В–Є—Ж–Є—П—Е. –Я—А–Є —Н—В–Њ–Љ –Ј–∞–њ—А–Њ—Б—Л –Ї —В–∞–±–ї–Є—Ж–µ «my_logs» –Љ–µ–љ—П—В—М –љ–µ –љ—Г–ґ–љ–Њ:
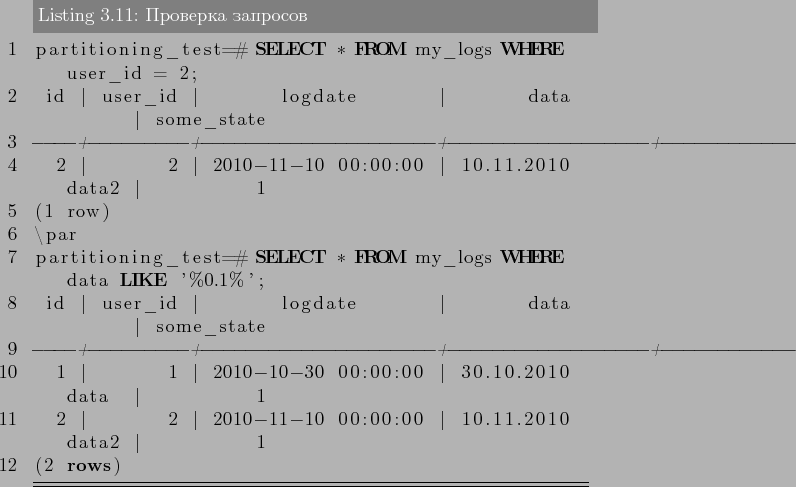
3 –£–њ—А–∞–≤–ї–µ–љ–Є–µ –њ–∞—А—В–Є—Ж–Є—П–Љ–Є
–Ю–±—Л—З–љ–Њ –њ—А–Є —А–∞–±–Њ—В–µ —Б –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ–Љ —Б—В–∞—А—Л–µ –њ–∞—А—В–Є—Ж–Є–Є –њ–µ—А–µ—Б—В–∞—О—В –њ–Њ–ї—Г—З–∞—В—М –і–∞–љ–љ—Л–µ –Є –Њ—Б—В–∞—О—В—Б—П –љ–µ–Є–Ј–Љ–µ–љ–љ—Л–Љ–Є. –≠—В–Њ –і–∞–µ—В –Њ–≥–Њ—А–Њ–Љ–љ–Њ–µ –њ—А–Є–µ–Љ—Г—Й–µ—Б—В–≤–Њ –љ–∞–і —А–∞–±–Њ—В–∞–є —Б –і–∞–љ–љ—Л–Љ–Є —З–µ—А–µ–Ј –њ–∞—А—В–Є—Ж–Є–Є. –Э–∞–њ—А–Є–Љ–µ—А, –љ–∞–Љ –љ—Г–ґ–љ–Њ —Г–і–∞–ї–Є—В—М —Б—В–∞—А—Л–µ –ї–Њ–≥–Є –Ј–∞ 2008 –≥–Њ–і, 10 –Љ–µ—Б—П—Ж. –Э–∞–Љ –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –≤—Л–њ–Њ–ї–Є—В—М:![\begin{lstlisting}[language=SQL,label=lst:partitioning12,caption=–І–Є—Б—В–Ї–∞ –ї–Њ–≥–Њ–≤]
DROP TABLE my_logs2008m10;
\end{lstlisting}](postgresql-img24.png)
–њ–Њ—Б–Ї–Њ–ї—М–Ї—Г «DROP TABLE» —А–∞–±–Њ—В–∞–µ—В –≥–Њ—А–∞–Ј–і–Њ –±—Л—Б—В—А–µ–µ, —З–µ–Љ —Г–і–∞–ї–µ–љ–Є–µ –Љ–Є–ї–Є–Њ–љ–Њ–≤ –Ј–∞–њ–Є—Б–µ–є –Є–љ–і–Є–≤–Є–і—Г–∞–ї—М–љ–Њ —З–µ—А–µ–Ј «DELETE». –Ф—А—Г–≥–Њ–є –≤–∞—А–Є–∞–љ—В, –Ї–Њ—В–Њ—А—Л–є –±–Њ–ї–µ–µ –њ—А–µ–і–њ–Њ—З—В–Є—В–µ–ї–µ–љ, –њ—А–Њ—Б—В–Њ —Г–і–∞–ї–Є—В—М –њ–∞—А—В–Є—Ж–Є—О –Є–Ј –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є—П, —В–µ–Љ —Б–∞–Љ—Л–Љ –Њ—Б—В–∞–≤–Є–≤ –і–∞–љ–љ—Л–µ –≤ –°–£–С–Ф, –љ–Њ —Г–ґ–µ –љ–µ –і–Њ—Б—В—Г–њ–љ—Л–µ —З–µ—А–µ–Ј «–Љ–∞—Б—В–µ—А» —В–∞–±–ї–Є—Ж—Г:
![\begin{lstlisting}[language=SQL,label=lst:partitioning13,caption=–£–і–∞–ї—П–µ–Љ ...
...—А–Њ–≤–∞–љ–Є—П]
ALTER TABLE my_logs2008m10 NO INHERIT my_logs;
\end{lstlisting}](postgresql-img25.png)
–≠—В–Њ —Г–і–Њ–±–љ–Њ, –µ—Б–ї–Є –Љ—Л —Е–Њ—В–Є–Љ —Н—В–Є –і–∞–љ–љ—Л–µ –њ–Њ—В–Њ–Љ –њ–µ—А–µ–љ–µ—Б—В–Є –≤ –і—А—Г–≥–Њ–µ —Е—А–∞–љ–Є–ї–Є—Й–µ –Є–ї–Є –њ—А–Њ—Б—В–Њ —Б–Њ—Е—А–∞–љ–Є—В—М.
4 –Т–∞–ґ–љ–Њ—Б—В—М «constraint_exclusion» –і–ї—П –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є—П
–Я–∞—А–∞–Љ–µ—В—А «constraint_exclusion» –Њ—В–≤–µ—З–∞–µ—В –Ј–∞ –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є—О –Ј–∞–њ—А–Њ—Б–Њ–≤, —З—В–Њ –њ–Њ–≤—Л—И–∞–µ—В –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М –і–ї—П –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ—Л—Е —В–∞–±–ї–Є—Ж. –Э–∞–њ—А–Є–Љ–µ—А, –≤—Л–њ–Њ–љ–Є–Љ –њ—А–Њ—Б—В–Њ–є –Ј–∞–њ—А–Њ—Б:
–Ъ–∞–Ї –≤–Є–і–љ–Њ —З–µ—А–µ–Ј –Ї–Њ–Љ–∞–љ–і—Г «EXPLAIN», –і–∞–љ–љ—Л–є –Ј–∞–њ—А–Њ—Б —Б–Ї–∞–љ–Є—А—Г–µ—В –≤—Б–µ –њ–∞—А—В–Є—Ж–Є–Є –љ–∞ –љ–∞–ї–Є—З–Є–µ –і–∞–љ–љ—Л—Е –≤ –љ–Є—Е, —З—В–Њ –љ–µ –ї–Њ–≥–Є—З–љ–Њ,
–њ–Њ—Б–Ї–Њ–ї—М–Ї—Г –і–∞–љ–љ–Њ–µ —Г—Б–ї–Њ–≤–Є–µ «logdate > 2010-12-01» –≥–Њ–≤–Њ—А–Є—В –Њ —В–Њ–Љ, —З—В–Њ –і–∞–љ–љ—Л–µ –і–Њ–ї–ґ–љ—Л –±—А–∞—В—Б—П —В–Њ–ї—М–Ї–Њ —Б –њ–∞—А—В–Є—Ж—Л–є,
–≥–і–µ –њ–Њ–і—Е–Њ–і–Є—В —В–∞–Ї–Њ–µ —Г—Б–ї–Њ–≤–Є–µ. –Р —В–µ–њ–µ—А—М –≤–Ї–ї—О—З–Є–Љ «constraint_exclusion»:
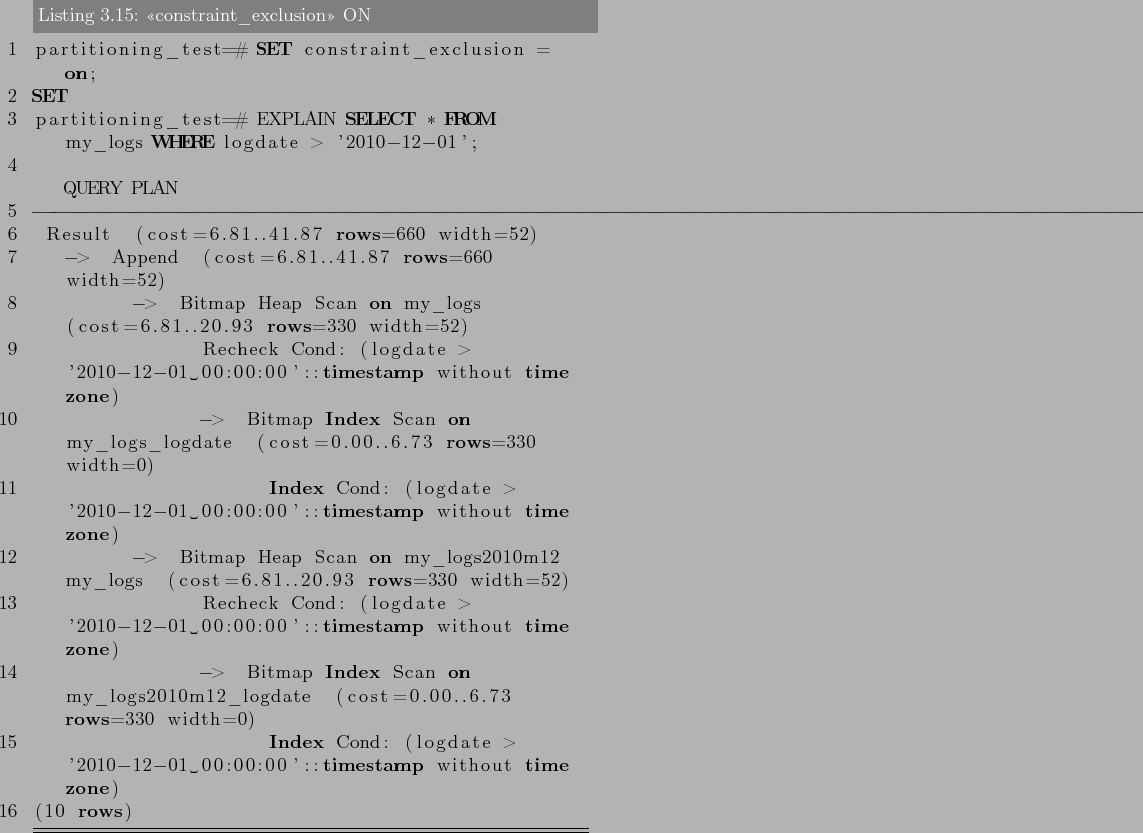
–Ъ–∞–Ї –Љ—Л –≤–Є–і–Є–Љ, —В–µ–њ–µ—А—М –Ј–∞–њ—А–Њ—Б —А–∞–±–Њ—В–∞–µ—В –њ—А–∞–≤–Є–ї—М–љ–Њ, –Є —Б–Ї–∞–љ–Є—А—Г–µ—В —В–Њ–ї—М–Ї–Њ –њ–∞—А—В–Є—Ж–Є–Є, —З—В–Њ –њ–Њ–і—Е–Њ–і—П—В –њ–Њ–і —Г—Б–ї–Њ–≤–Є–µ –Ј–∞–њ—А–Њ—Б–∞. –Э–Њ –≤–Ї–ї—О—З–∞—В—М «constraint_exclusion» –љ–µ –ґ–µ–ї–∞—В–µ–ї—М–љ–Њ –і–ї—П –±–∞–Ј, –≥–і–µ –љ–µ—В –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є—П, –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г –Ї–Њ–Љ–∞–љ–і–∞ «CHECK» –±—Г–і–µ—В –њ—А–Њ–≤–µ—А—П—В—Б—П –љ–∞ –≤—Б–µ—Е –Ј–∞–њ—А–Њ—Б–∞—Е, –і–∞–ґ–µ –њ—А–Њ—Б—В—Л—Е, –∞ –Ј–љ–∞—З–Є—В –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М —Б–Є–ї—М–љ–Њ —Г–њ–∞–і–µ—В. –Э–∞—З–Є–љ–∞—П —Б 8.4 –≤–µ—А—Б–Є–Є PostgreSQL «constraint_exclusion» –Љ–Њ–ґ–µ—В –±—Л—В—М «on», «off» –Є «partition». –Я–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О (–Є —А–µ–Ї–Њ–Љ–µ–љ–і—Г–µ—В—Б—П) —Б—В–∞–≤–Є—В—М «constraint_exclusion» –љ–µ «on», –Є –љ–µ «off», –∞ «partition», –Ї–Њ—В–Њ—А—Л–є –±—Г–і–µ—В –њ—А–Њ–≤–µ—А—П—В—М «CHECK» —В–Њ–ї—М–Ї–Њ –љ–∞ –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ—Л—Е —В–∞–±–ї–Є—Ж–∞—Е.
4 –Ч–∞–Ї–ї—О—З–µ–љ–Є–µ
–Я–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ -- –Њ–і–љ–∞ –Є–Ј —Б–∞–Љ—Л—Е –њ—А–Њ—Б—В—Л—Е –Є –Љ–µ–љ–µ–µ –±–µ–Ј–±–Њ–ї–µ–Ј–љ–µ–љ–љ—Л—Е –Љ–µ—В–Њ–і–Њ–≤ —Г–Љ–µ–љ—М—И–µ–љ–Є—П –љ–∞–≥—А—Г–Ј–Ї–Є –љ–∞ –°–£–С–Ф. –Ш–Љ–µ–љ–љ–Њ –љ–∞ —Н—В–Њ—В –≤–∞—А–Є–∞–љ—В —Б—В–Њ–Є—В –њ–Њ—Б–Љ–Њ—В—А–µ—В—М —Б–њ–µ—А–≤–∞, –Є –µ—Б–ї–Є –Њ–љ –љ–µ –њ–Њ–і—Е–Њ–і–Є—В –њ–Њ –Ї–∞–Ї–Є–Љ –ї–Є–±–Њ –њ—А–Є—З–Є–љ–∞–Љ -- –њ–µ—А–µ—Е–Њ–і–Є—В—М –Ї –±–Њ–ї–µ–µ —Б–ї–Њ–ґ–љ—Л–Љ. –Э–Њ –µ—Б–ї–Є –≤ —Б–Є—Б—В–µ–Љ–µ –µ—Б—В—М —В–∞–±–ї–Є—Ж–∞, —Г –Ї–Њ—В–Њ—А–Њ–є –∞–Ї—В—Г–∞–ї—М–љ—Л —В–Њ–ї—М–Ї–Њ –љ–Њ–≤—Л–µ –і–∞–љ–љ—Л–µ, –љ–Њ –Њ–≥—А–Њ–Љ–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б—В–∞—А—Л—Е (–љ–µ –∞–Ї—В—Г–∞–ї—М–љ—Л—Е) –і–∞–љ–љ—Л—Е –і–∞–µ—В 50% –Є–ї–Є –±–Њ–ї–µ–µ –љ–∞–≥—А—Г–Ј–Ї–Є –љ–∞ –°–£–С–Ф -- –Т–∞–Љ —Б—В–Њ–Є—В –≤–љ–µ–і—А–Є—В—М –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є—О.4 –†–µ–њ–ї–Є–Ї–∞—Ж–Є—П

1 –Т–≤–µ–і–µ–љ–Є–µ
–†–µ–њ–ї–Є–Ї–∞—Ж–Є—П (–∞–љ–≥–ї. replication) -- –Љ–µ—Е–∞–љ–Є–Ј–Љ —Б–Є–љ—Е—А–Њ–љ–Є–Ј–∞—Ж–Є–Є —Б–Њ–і–µ—А–ґ–Є–Љ–Њ–≥–Њ –љ–µ—Б–Ї–Њ–ї—М–Ї–Є—Е –Ї–Њ–њ–Є–є –Њ–±—К–µ–Ї—В–∞ (–љ–∞–њ—А–Є–Љ–µ—А, —Б–Њ–і–µ—А–ґ–Є–Љ–Њ–≥–Њ –±–∞–Ј—Л –і–∞–љ–љ—Л—Е). –†–µ–њ–ї–Є–Ї–∞—Ж–Є—П -- —Н—В–Њ –њ—А–Њ—Ж–µ—Б—Б, –њ–Њ–і –Ї–Њ—В–Њ—А—Л–Љ –њ–Њ–љ–Є–Љ–∞–µ—В—Б—П –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є–µ –і–∞–љ–љ—Л—Е –Є–Ј –Њ–і–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞ –љ–∞ –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ –і—А—Г–≥–Є—Е –Є –љ–∞–Њ–±–Њ—А–Њ—В. –Я—А–Є —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є –Є–Ј–Љ–µ–љ–µ–љ–Є—П, —Б–і–µ–ї–∞–љ–љ—Л–µ –≤ –Њ–і–љ–Њ–є –Ї–Њ–њ–Є–Є –Њ–±—К–µ–Ї—В–∞, –Љ–Њ–≥—Г—В –±—Л—В—М —А–∞—Б–њ—А–Њ—Б—В—А–∞–љ–µ–љ—Л –≤ –і—А—Г–≥–Є–µ –Ї–Њ–њ–Є–Є. –†–µ–њ–ї–Є–Ї–∞—Ж–Є—П –Љ–Њ–ґ–µ—В –±—Л—В—М —Б–Є–љ—Е—А–Њ–љ–љ–Њ–є –Є–ї–Є –∞—Б–Є–љ—Е—А–Њ–љ–љ–Њ–є.–Т —Б–ї—Г—З–∞–µ —Б–Є–љ—Е—А–Њ–љ–љ–Њ–є —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є, –µ—Б–ї–Є –і–∞–љ–љ–∞—П —А–µ–њ–ї–Є–Ї–∞ –Њ–±–љ–Њ–≤–ї—П–µ—В—Б—П, –≤—Б–µ –і—А—Г–≥–Є–µ —А–µ–њ–ї–Є–Ї–Є —В–Њ–≥–Њ –ґ–µ —Д—А–∞–≥–Љ–µ–љ—В–∞ –і–∞–љ–љ—Л—Е —В–∞–Ї–ґ–µ –і–Њ–ї–ґ–љ—Л –±—Л—В—М –Њ–±–љ–Њ–≤–ї–µ–љ—Л –≤ –Њ–і–љ–Њ–є –Є —В–Њ–є –ґ–µ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є. –Ы–Њ–≥–Є—З–µ—Б–Ї–Є —Н—В–Њ –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ —Б—Г—Й–µ—Б—В–≤—Г–µ—В –ї–Є—И—М –Њ–і–љ–∞ –≤–µ—А—Б–Є—П –і–∞–љ–љ—Л—Е. –Т –±–Њ–ї—М—И–Є–љ—Б—В–≤–µ –њ—А–Њ–і—Г–Ї—В–Њ–≤ —Б–Є–љ—Е—А–Њ–љ–љ–∞—П —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П —А–µ–∞–ї–Є–Ј—Г–µ—В—Б—П —Б –њ–Њ–Љ–Њ—Й—М—О —В—А–Є–≥–≥–µ—А–љ—Л—Е –њ—А–Њ—Ж–µ–і—Г—А (–≤–Њ–Ј–Љ–Њ–ґ–љ–Њ, —Б–Ї—А—Л—В—Л—Е –Є —Г–њ—А–∞–≤–ї—П–µ–Љ—Л—Е —Б–Є—Б—В–µ–Љ–Њ–є). –Э–Њ —Б–Є–љ—Е—А–Њ–љ–љ–∞—П —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П –Є–Љ–µ–µ—В —В–Њ—В –љ–µ–і–Њ—Б—В–∞—В–Њ–Ї, —З—В–Њ –Њ–љ–∞ —Б–Њ–Ј–і–∞—С—В –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Г—О –љ–∞–≥—А—Г–Ј–Ї—Г –њ—А–Є –≤—Л–њ–Њ–ї–љ–µ–љ–Є–Є –≤—Б–µ—Е —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є, –≤ –Ї–Њ—В–Њ—А—Л—Е –Њ–±–љ–Њ–≤–ї—П—О—В—Б—П –Ї–∞–Ї–Є–µ-–ї–Є–±–Њ —А–µ–њ–ї–Є–Ї–Є (–Ї—А–Њ–Љ–µ —В–Њ–≥–Њ, –Љ–Њ–≥—Г—В –≤–Њ–Ј–љ–Є–Ї–∞—В—М –њ—А–Њ–±–ї–µ–Љ—Л, —Б–≤—П–Ј–∞–љ–љ—Л–µ —Б –і–Њ—Б—В—Г–њ–љ–Њ—Б—В—М—О –і–∞–љ–љ—Л—Е).
–Т —Б–ї—Г—З–∞–µ –∞—Б–Є–љ—Е—А–Њ–љ–љ–Њ–є —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є –Њ–±–љ–Њ–≤–ї–µ–љ–Є–µ –Њ–і–љ–Њ–є —А–µ–њ–ї–Є–Ї–Є —А–∞—Б–њ—А–Њ—Б—В—А–∞–љ—П–µ—В—Б—П –љ–∞ –і—А—Г–≥–Є–µ —Б–њ—Г—Б—В—П –љ–µ–Ї–Њ—В–Њ—А–Њ–µ –≤—А–µ–Љ—П, –∞ –љ–µ –≤ —В–Њ–є –ґ–µ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є. –Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, –њ—А–Є –∞—Б–Є–љ—Е—А–Њ–љ–љ–Њ–є —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є –≤–≤–Њ–і–Є—В—Б—П –Ј–∞–і–µ—А–ґ–Ї–∞, –Є–ї–Є –≤—А–µ–Љ—П –Њ–ґ–Є–і–∞–љ–Є—П, –≤ —В–µ—З–µ–љ–Є–µ –Ї–Њ—В–Њ—А–Њ–≥–Њ –Њ—В–і–µ–ї—М–љ—Л–µ —А–µ–њ–ї–Є–Ї–Є –Љ–Њ–≥—Г—В –±—Л—В—М —Д–∞–Ї—В–Є—З–µ—Б–Ї–Є –љ–µ–Є–і–µ–љ—В–Є—З–љ—Л–Љ–Є (—В–Њ –µ—Б—В—М –Њ–њ—А–µ–і–µ–ї–µ–љ–Є–µ —А–µ–њ–ї–Є–Ї–∞ –Њ–Ї–∞–Ј—Л–≤–∞–µ—В—Б—П –љ–µ —Б–Њ–≤—Б–µ–Љ –њ–Њ–і—Е–Њ–і—П—Й–Є–Љ, –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г –Љ—Л –љ–µ –Є–Љ–µ–µ–Љ –і–µ–ї–Њ —Б —В–Њ—З–љ—Л–Љ–Є –Є —Б–≤–Њ–µ–≤—А–µ–Љ–µ–љ–љ–Њ —Б–Њ–Ј–і–∞–љ–љ—Л–Љ–Є –Ї–Њ–њ–Є—П–Љ–Є). –Т –±–Њ–ї—М—И–Є–љ—Б—В–≤–µ –њ—А–Њ–і—Г–Ї—В–Њ–≤ –∞—Б–Є–љ—Е—А–Њ–љ–љ–∞—П —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П —А–µ–∞–ї–Є–Ј—Г–µ—В—Б—П –њ–Њ—Б—А–µ–і—Б—В–≤–Њ–Љ —З—В–µ–љ–Є—П –ґ—Г—А–љ–∞–ї–∞ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –Є–ї–Є –њ–Њ—Б—В–Њ—П–љ–љ–Њ–є –Њ—З–µ—А–µ–і–Є —В–µ—Е –Њ–±–љ–Њ–≤–ї–µ–љ–Є–є, –Ї–Њ—В–Њ—А—Л–µ –њ–Њ–і–ї–µ–ґ–∞—В —А–∞—Б–њ—А–Њ—Б—В—А–∞–љ–µ–љ–Є—О. –Я—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–Њ –∞—Б–Є–љ—Е—А–Њ–љ–љ–Њ–є —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є —Б–Њ—Б—В–Њ–Є—В –≤ —В–Њ–Љ, —З—В–Њ –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л–µ –Є–Ј–і–µ—А–ґ–Ї–Є —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є –љ–µ —Б–≤—П–Ј–∞–љ—Л —Б —В—А–∞–љ–Ј–∞–Ї—Ж–Є—П–Љ–Є –Њ–±–љ–Њ–≤–ї–µ–љ–Є–є, –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–≥—Г—В –Є–Љ–µ—В—М –≤–∞–ґ–љ–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ –і–ї—П —Д—Г–љ–Ї—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–љ–Є—П –≤—Б–µ–≥–Њ –њ—А–µ–і–њ—А–Є—П—В–Є—П –Є –њ—А–µ–і—К—П–≤–ї—П—В—М –≤—Л—Б–Њ–Ї–Є–µ —В—А–µ–±–Њ–≤–∞–љ–Є—П –Ї –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є. –Ъ –љ–µ–і–Њ—Б—В–∞—В–Ї–∞–Љ —Н—В–Њ–є —Б—Е–µ–Љ—Л –Њ—В–љ–Њ—Б–Є—В—Б—П —В–Њ, —З—В–Њ –і–∞–љ–љ—Л–µ –Љ–Њ–≥—Г—В –Њ–Ї–∞–Ј–∞—В—М—Б—П –љ–µ—Б–Њ–≤–Љ–µ—Б—В–Є–Љ—Л–Љ–Є (—В–Њ –µ—Б—В—М –љ–µ—Б–Њ–≤–Љ–µ—Б—В–Є–Љ—Л–Љ–Є —Б —В–Њ—З–Ї–Є –Ј—А–µ–љ–Є—П –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П). –Ш–љ—Л–Љ–Є —Б–ї–Њ–≤–∞–Љ–Є, –Є–Ј–±—Л—В–Њ—З–љ–Њ—Б—В—М –Љ–Њ–ґ–µ—В –њ—А–Њ—П–≤–ї—П—В—М—Б—П –љ–∞ –ї–Њ–≥–Є—З–µ—Б–Ї–Њ–Љ —Г—А–Њ–≤–љ–µ, –∞ —Н—В–Њ, —Б—В—А–Њ–≥–Њ –≥–Њ–≤–Њ—А—П, –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ —В–µ—А–Љ–Є–љ –Ї–Њ–љ—В—А–Њ–ї–Є—А—Г–µ–Љ–∞—П –Є–Ј–±—Л—В–Њ—З–љ–Њ—Б—В—М –≤ —В–∞–Ї–Њ–Љ —Б–ї—Г—З–∞–µ –љ–µ –њ—А–Є–Љ–µ–љ–Є–Љ.
–†–∞—Б—Б–Љ–Њ—В—А–Є–Љ –Ї—А–∞—В–Ї–Њ –њ—А–Њ–±–ї–µ–Љ—Г —Б–Њ–≥–ї–∞—Б–Њ–≤–∞–љ–љ–Њ—Б—В–Є (–Є–ї–Є, —Б–Ї–Њ—А–µ–µ, –љ–µ—Б–Њ–≥–ї–∞—Б–Њ–≤–∞–љ–љ–Њ—Б—В–Є). –Ф–µ–ї–Њ –≤ —В–Њ–Љ, —З—В–Њ —А–µ–њ–ї–Є–Ї–Є –Љ–Њ–≥—Г—В —Б—В–∞–љ–Њ–≤–Є—В—М—Б—П –љ–µ—Б–Њ–≤–Љ–µ—Б—В–Є–Љ—Л–Љ–Є –≤ —А–µ–Ј—Г–ї—М—В–∞—В–µ —Б–Є—В—Г–∞—Ж–Є–є, –Ї–Њ—В–Њ—А—Л–µ —В—А—Г–і–љ–Њ (–Є–ї–Є –і–∞–ґ–µ –љ–µ–≤–Њ–Ј–Љ–Њ–ґ–љ–Њ) –Є–Ј–±–µ–ґ–∞—В—М –Є –њ–Њ—Б–ї–µ–і—Б—В–≤–Є—П –Ї–Њ—В–Њ—А—Л—Е —В—А—Г–і–љ–Њ –Є—Б–њ—А–∞–≤–Є—В—М. –Т —З–∞—Б—В–љ–Њ—Б—В–Є, –Ї–Њ–љ—Д–ї–Є–Ї—В—Л –Љ–Њ–≥—Г—В –≤–Њ–Ј–љ–Є–Ї–∞—В—М –њ–Њ –њ–Њ–≤–Њ–і—Г —В–Њ–≥–Њ, –≤ –Ї–∞–Ї–Њ–Љ –њ–Њ—А—П–і–Ї–µ –і–Њ–ї–ґ–љ—Л –њ—А–Є–Љ–µ–љ—П—В—М—Б—П –Њ–±–љ–Њ–≤–ї–µ–љ–Є—П. –Э–∞–њ—А–Є–Љ–µ—А, –њ—А–µ–і–њ–Њ–ї–Њ–ґ–Є–Љ, —З—В–Њ –≤ —А–µ–Ј—Г–ї—М—В–∞—В–µ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є –Р –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –≤—Б—В–∞–≤–Ї–∞ —Б—В—А–Њ–Ї–Є –≤ —А–µ–њ–ї–Є–Ї—Г X, –њ–Њ—Б–ї–µ —З–µ–≥–Њ —В—А–∞–љ–Ј–∞–Ї—Ж–Є—П B —Г–і–∞–ї—П–µ—В —Н—В—Г —Б—В—А–Њ–Ї—Г, –∞ —В–∞–Ї–ґ–µ –і–Њ–њ—Г—Б—В–Є–Љ, —З—В–Њ Y -- —А–µ–њ–ї–Є–Ї–∞ X. –Х—Б–ї–Є –Њ–±–љ–Њ–≤–ї–µ–љ–Є—П —А–∞—Б–њ—А–Њ—Б—В—А–∞–љ—П—О—В—Б—П –љ–∞ Y, –љ–Њ –≤–≤–Њ–і—П—В—Б—П –≤ —А–µ–њ–ї–Є–Ї—Г Y –≤ –Њ–±—А–∞—В–љ–Њ–Љ –њ–Њ—А—П–і–Ї–µ (–љ–∞–њ—А–Є–Љ–µ—А, –Є–Ј-–Ј–∞ —А–∞–Ј–љ—Л—Е –Ј–∞–і–µ—А–ґ–µ–Ї –њ—А–Є –њ–µ—А–µ–і–∞—З–µ), —В–Њ —В—А–∞–љ–Ј–∞–Ї—Ж–Є—П B –љ–µ –љ–∞—Е–Њ–і–Є—В –≤ Y —Б—В—А–Њ–Ї—Г, –њ–Њ–і–ї–µ–ґ–∞—Й—Г—О —Г–і–∞–ї–µ–љ–Є—О, –Є –љ–µ –≤—Л–њ–Њ–ї–љ—П–µ—В —Б–≤–Њ—С –і–µ–є—Б—В–≤–Є–µ, –њ–Њ—Б–ї–µ —З–µ–≥–Њ —В—А–∞–љ–Ј–∞–Ї—Ж–Є—П –Р –≤—Б—В–∞–≤–ї—П–µ—В —Н—В—Г —Б—В—А–Њ–Ї—Г. –°—Г–Љ–Љ–∞—А–љ—Л–є —Н—Д—Д–µ–Ї—В —Б–Њ—Б—В–Њ–Є—В –≤ —В–Њ–Љ, —З—В–Њ —А–µ–њ–ї–Є–Ї–∞ Y —Б–Њ–і–µ—А–ґ–Є—В —Г–Ї–∞–Ј–∞–љ–љ—Г—О —Б—В—А–Њ–Ї—Г, –∞ —А–µ–њ–ї–Є–Ї–∞ X -- –љ–µ—В.
–Т —Ж–µ–ї–Њ–Љ –Ј–∞–і–∞—З–Є —Г—Б—В—А–∞–љ–µ–љ–Є—П –Ї–Њ–љ—Д–ї–Є–Ї—В–љ—Л—Е —Б–Є—В—Г–∞—Ж–Є–є –Є –Њ–±–µ—Б–њ–µ—З–µ–љ–Є—П —Б–Њ–≥–ї–∞—Б–Њ–≤–∞–љ–љ–Њ—Б—В–Є —А–µ–њ–ї–Є–Ї —П–≤–ї—П—О—В—Б—П –≤–µ—Б—М–Љ–∞ —Б–ї–Њ–ґ–љ—Л–Љ–Є. –°–ї–µ–і—Г–µ—В –Њ—В–Љ–µ—В–Є—В—М, —З—В–Њ, –њ–Њ –Ї—А–∞–є–љ–µ–є –Љ–µ—А–µ, –≤ —Б–Њ–Њ–±—Й–µ—Б—В–≤–µ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є –Ї–Њ–Љ–Љ–µ—А—З–µ—Б–Ї–Є—Е –±–∞–Ј –і–∞–љ–љ—Л—Е —В–µ—А–Љ–Є–љ —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П —Б—В–∞–ї –Њ–Ј–љ–∞—З–∞—В—М –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–µ–љ–љ–Њ (–Є–ї–Є –і–∞–ґ–µ –Є—Б–Ї–ї—О—З–Є—В–µ–ї—М–љ–Њ) –∞—Б–Є–љ—Е—А–Њ–љ–љ—Г—О —А–µ–њ–ї–Є–Ї–∞—Ж–Є—О.
–Ю—Б–љ–Њ–≤–љ–Њ–µ —А–∞–Ј–ї–Є—З–Є–µ –Љ–µ–ґ–і—Г —А–µ–њ–ї–Є–Ї–∞—Ж–Є–µ–є –Є —Г–њ—А–∞–≤–ї–µ–љ–Є–µ–Љ –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є–µ–Љ –Ј–∞–Ї–ї—О—З–∞–µ—В—Б—П –≤ —Б–ї–µ–і—Г—О—Й–µ–Љ: –Х—Б–ї–Є –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П, —В–Њ –Њ–±–љ–Њ–≤–ї–µ–љ–Є–µ –Њ–і–љ–Њ–є —А–µ–њ–ї–Є–Ї–Є –≤ –Ї–Њ–љ–µ—З–љ–Њ–Љ —Б—З—С—В–µ —А–∞—Б–њ—А–Њ—Б—В—А–∞–љ—П–µ—В—Б—П –љ–∞ –≤—Б–µ –Њ—Б—В–∞–ї—М–љ—Л–µ –∞–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Є. –Т —А–µ–ґ–Є–Љ–µ —Г–њ—А–∞–≤–ї–µ–љ–Є—П –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є–µ–Љ, –љ–∞–њ—А–Њ—В–Є–≤, –љ–µ —Б—Г—Й–µ—Б—В–≤—Г–µ—В —В–∞–Ї–Њ–≥–Њ –∞–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Њ–≥–Њ —А–∞—Б–њ—А–Њ—Б—В—А–∞–љ–µ–љ–Є—П –Њ–±–љ–Њ–≤–ї–µ–љ–Є–є. –Ъ–Њ–њ–Є–Є –і–∞–љ–љ—Л—Е —Б–Њ–Ј–і–∞—О—В—Б—П –Є —Г–њ—А–∞–≤–ї—П—О—В—Б—П —Б –њ–Њ–Љ–Њ—Й—М—О –њ–∞–Ї–µ—В–љ–Њ–≥–Њ –Є–ї–Є —Д–Њ–љ–Њ–≤–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞, –Ї–Њ—В–Њ—А—Л–є –Њ—В–і–µ–ї—С–љ –≤–Њ –≤—А–µ–Љ–µ–љ–Є –Њ—В —В—А–∞–љ–Ј–∞–Ї—Ж–Є–є –Њ–±–љ–Њ–≤–ї–µ–љ–Є—П. –£–њ—А–∞–≤–ї–µ–љ–Є–µ –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є–µ–Љ –≤ –Њ–±—Й–µ–Љ –±–Њ–ї–µ–µ —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ –њ–Њ —Б—А–∞–≤–љ–µ–љ–Є—О —Б —А–µ–њ–ї–Є–Ї–∞—Ж–Є–µ–є, –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г –Ј–∞ –Њ–і–Є–љ —А–∞–Ј –Љ–Њ–≥—Г—В –Ї–Њ–њ–Є—А–Њ–≤–∞—В—М—Б—П –±–Њ–ї—М—И–Є–µ –Њ–±—К—С–Љ—Л –і–∞–љ–љ—Л—Е. –Ъ –љ–µ–і–Њ—Б—В–∞—В–Ї–∞–Љ –Љ–Њ–ґ–љ–Њ –Њ—В–љ–µ—Б—В–Є —В–Њ, —З—В–Њ –±–Њ–ї—М—И—Г—О —З–∞—Б—В—М –≤—А–µ–Љ–µ–љ–Є –Ї–Њ–њ–Є–Є –і–∞–љ–љ—Л—Е –љ–µ –Є–і–µ–љ—В–Є—З–љ—Л –±–∞–Ј–Њ–≤—Л–Љ –і–∞–љ–љ—Л–Љ, –њ–Њ—Н—В–Њ–Љ—Г –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–Є –і–Њ–ї–ґ–љ—Л —Г—З–Є—В—Л–≤–∞—В—М, –Ї–Њ–≥–і–∞ –Є–Љ–µ–љ–љ–Њ –±—Л–ї–Є —Б–Є–љ—Е—А–Њ–љ–Є–Ј–Є—А–Њ–≤–∞–љ—Л —Н—В–Є –і–∞–љ–љ—Л–µ. –Ю–±—Л—З–љ–Њ —Г–њ—А–∞–≤–ї–µ–љ–Є–µ –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є–µ–Љ —Г–њ—А–Њ—Й–∞–µ—В—Б—П –±–ї–∞–≥–Њ–і–∞—А—П —В–Њ–Љ—Г —В—А–µ–±–Њ–≤–∞–љ–Є—О, —З—В–Њ–±—Л –Њ–±–љ–Њ–≤–ї–µ–љ–Є—П –њ—А–Є–Љ–µ–љ—П–ї–Є—Б—М –≤ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є–Є —Б–Њ —Б—Е–µ–Љ–Њ–є –њ–µ—А–≤–Є—З–љ–Њ–є –Ї–Њ–њ–Є–Є —В–Њ–≥–Њ –Є–ї–Є –Є–љ–Њ–≥–Њ –≤–Є–і–∞.
–Ф–ї—П —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є PostgreSQL —Б—Г—Й–µ—Б—В–≤—Г–µ—В –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ —А–µ—И–µ–љ–Є–є, –Ї–∞–Ї –Ј–∞–Ї—А—Л—В—Л—Е, —В–∞–Ї –Є —Б–≤–Њ–±–Њ–і–љ—Л—Е. –Ч–∞–Ї—А—Л—В—Л–µ —Б–Є—Б—В–µ–Љ—Л —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є –љ–µ –±—Г–і—Г—В —А–∞—Б—Б–Љ–∞—В—А–Є–≤–∞—В—М—Б—П –≤ —Н—В–Њ–є –Ї–љ–Є–≥–µ (–љ—Г, —Б–∞–Љ–Є –њ–Њ–љ–Є–Љ–∞–µ—В–µ). –Т–Њ—В —Б–њ–Є—Б–Њ–Ї —Б–≤–Њ–±–Њ–і–љ—Л—Е —А–µ—И–µ–љ–Є–є:
- Slony-I12 -- –∞—Б–Є–љ—Е—А–Њ–љ–љ–∞—П Master-Slave —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П,
–њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В –Ї–∞—Б–Ї–∞–і—Л(cascading) –Є –Њ—В–Ї–∞–Ј–Њ—Г—Б—В–Њ–є—З–Є–≤–Њ—Б—В—М(failover).
Slony-I –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В —В—А–Є–≥–≥–µ—А—Л PostgreSQL –і–ї—П –њ—А–Є–≤—П–Ј–Ї–Є –Ї —Б–Њ–±—Л—В–Є—П–Љ INSERT/ DELETE/UPDATE –Є —Е—А–∞–љ–Є–Љ—Л–µ
–њ—А–Њ—Ж–µ–і—Г—А—Л –і–ї—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –і–µ–є—Б—В–≤–Є–є.
- PGCluster13 -- —Б–Є–љ—Е—А–Њ–љ–љ–∞—П Multi-Master —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П.
–Я—А–Њ–µ–Ї—В –љ–∞ –Љ–Њ–є –≤–Ј–≥–ї—П–і –Љ–µ—А—В–≤, –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г —Г–ґ–µ –≥–Њ–і –љ–µ –Њ–±–љ–Њ–≤–ї—П–ї—Б—П.
- pgpool-I/II14 -- —Н—В–Њ –Ј–∞–Љ–µ—З–∞—В–µ–ї—М–љ—Л–є –Є–љ—Б—В—А—Г–Љ–µ–љ—В –і–ї—П
PostgreSQL (–ї—Г—З—И–µ —Б—А–∞–Ј—Г —А–∞–±–Њ—В–∞—В—М —Б II –≤–µ—А—Б–Є–µ–є). –Я–Њ–Ј–≤–Њ–ї—П–µ—В –і–µ–ї–∞—В—М:
- —А–µ–њ–ї–Є–Ї–∞—Ж–Є—О (–≤ —В–Њ–Љ —З–Є—Б–ї–µ, —Б –∞–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Є–Љ –њ–µ—А–µ–Ї–ї—О—З–µ–љ–Є–µ–Љ –љ–∞ —А–µ–Ј–µ—А–≤–љ—Л–є stand-by —Б–µ—А–≤–µ—А);
- online-–±—Н–Ї–∞–њ;
- pooling –Ї–Њ–љ–љ–µ–Ї—В–Њ–≤;
- –Њ—З–µ—А–µ–і—М —Б–Њ–µ–і–Є–љ–µ–љ–Є–є;
- –±–∞–ї–∞–љ—Б–Є—А–Њ–≤–Ї—Г SELECT-–Ј–∞–њ—А–Њ—Б–Њ–≤ –љ–∞ –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ postgresql-—Б–µ—А–≤–µ—А–Њ–≤;
- —А–∞–Ј–±–Є–µ–љ–Є–µ –Ј–∞–њ—А–Њ—Б–Њ–≤ –і–ї—П –њ–∞—А–∞–ї–ї–µ–ї—М–љ–Њ–≥–Њ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –љ–∞–і –±–Њ–ї—М—И–Є–Љ–Є –Њ–±—К–µ–Љ–∞–Љ–Є –і–∞–љ–љ—Л—Е.
- Bucardo15 -- –∞—Б–Є–љ—Е—А–Њ–љ–љ–∞—П —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П, –Ї–Њ—В–Њ—А–∞—П –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В Multi-Master –Є Master-Slave —А–µ–ґ–Є–Љ—Л,
–∞ —В–∞–Ї–ґ–µ –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –≤–Є–і–Њ–≤ —Б–Є–љ—Е—А–Њ–љ–Є–Ј–∞—Ж–Є–Є –Є –Њ–±—А–∞–±–Њ—В–Ї–Є –Ї–Њ–љ—Д–ї–Є–Ї—В–Њ–≤.
- Londiste16 -- –∞—Б–Є–љ—Е—А–Њ–љ–љ–∞—П Master-Slave
—А–µ–њ–ї–Є–Ї–∞—Ж–Є—П. –Т—Е–Њ–і–Є—В –≤ —Б–Њ—Б—В–∞–≤ Skytools17. –Я—А–Њ—Й–µ –≤ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–Є, —З–µ–Љ Slony-I.
- Mammoth Replicator18 -- –∞—Б–Є–љ—Е—А–Њ–љ–љ–∞—П
Multi-Master —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П.
- Postgres-R19 -- –∞—Б–Є–љ—Е—А–Њ–љ–љ–∞—П Multi-Master —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П.
- RubyRep20 -- –љ–∞–њ–Є—Б–∞–љ–љ–∞—П –љ–∞ Ruby, –∞—Б–Є–љ—Е—А–Њ–љ–љ–∞—П Multi-Master —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П, –Ї–Њ—В–Њ—А–∞—П –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В PostgreSQL –Є MySQL.
–≠—В–Њ, –Ї–Њ–љ–µ—З–љ–Њ, –љ–µ –≤–µ—Б—М —Б–њ–Є—Б–Њ–Ї —Б–≤–Њ–±–Њ–і–љ—Л—Е —Б–Є—Б—В–µ–Љ –і–ї—П —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є, –љ–Њ —П –і—Г–Љ–∞—О –і–∞–ґ–µ –Є–Ј —Н—В–Њ–≥–Њ –µ—Б—В—М —З—В–Њ –≤—Л–±—А–∞—В—М –і–ї—П PostgreSQL.
2 Bucardo
1 –Т–≤–µ–і–µ–љ–Є–µ
Bucardo -- –∞—Б–Є–љ—Е—А–Њ–љ–љ–∞—П master-master –Є–ї–Є master-slave —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П PostgreSQL, –Ї–Њ—В–Њ—А–∞—П –љ–∞–њ–Є—Б–∞–љ–∞ –љ–∞ Perl. –°–Є—Б—В–µ–Љ–∞ –Њ—З–µ–љ—М –≥–Є–±–Ї–∞—П, –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –≤–Є–і–Њ–≤ —Б–Є–љ—Е—А–Њ–љ–Є–Ј–∞—Ж–Є–Є –Є –Њ–±—А–∞–±–Њ—В–Ї–Є –Ї–Њ–љ—Д–ї–Є–Ї—В–Њ–≤.
2 –£—Б—В–∞–љ–Њ–≤–Ї–∞
–£—Б—В–∞–љ–Њ–≤–Ї—Г –±—Г–і–µ–Љ –њ—А–Њ–≤–Њ–і–Є—В—М –љ–∞ Ubuntu Server. –°–љ–∞—З–∞–ї–∞ –љ–∞–Љ –љ—Г–ґ–љ–Њ —Г—Б—В–∞–љ–Њ–≤–Є—В—М DBIx::Safe Perl –Љ–Њ–і—Г–ї—М.![\begin{lstlisting}[label=lst:bucardo1,caption=–£—Б—В–∞–љ–Њ–≤–Ї–∞]
sudo aptitude install libdbix-safe-perl
\end{lstlisting}](postgresql-img29.png)
–Ф–ї—П –і—А—Г–≥–Є—Е —Б–Є—Б—В–µ–Љ –Љ–Њ–ґ–љ–Њ –њ–Њ—Б—В–∞–≤–Є—В—М –Є–Ј –Є—Б—Е–Њ–і–љ–Є–Ї–Њ–≤21:
![\begin{lstlisting}[label=lst:bucardo2,caption=–£—Б—В–∞–љ–Њ–≤–Ї–∞]
tar xvfz DBIx-...
...e-1.2.5
perl Makefile.PL
make && make test && sudo make install
\end{lstlisting}](postgresql-img30.png)
–Ґ–µ–њ–µ—А—М —Б—В–∞–≤–Є–Љ —Б–∞–Љ Bucardo. –°–Ї–∞—З–Є–≤–∞–µ–Љ22 –µ–≥–Њ –Є –Є–љ—Б—В–∞–ї–Є—А—Г–µ–Љ:
![\begin{lstlisting}[label=lst:bucardo3,caption=–£—Б—В–∞–љ–Њ–≤–Ї–∞]
tar xvfz Bucar...
...tar.gz
cd Bucardo-4.4.0
perl Makefile.PL
make
sudo make install
\end{lstlisting}](postgresql-img31.png)
–Ф–ї—П —А–∞–±–Њ—В—Л Bucardo –њ–Њ—В—А–µ–±—Г–µ—В—Б—П —Г—Б—В–∞–љ–Њ–≤–Є—В—М –њ–Њ–і–і–µ—А–ґ–Ї—Г pl/perlu —П–Ј—Л–Ї–∞ PostgreSQL.
![\begin{lstlisting}[label=lst:bucardo4,caption=–£—Б—В–∞–љ–Њ–≤–Ї–∞]
sudo aptitude install postgresql-plperl-8.4
\end{lstlisting}](postgresql-img32.png)
–Ь–Њ–ґ–µ–Љ –њ—А–Є—Б—В—Г–њ–∞—В—М –Ї –љ–∞—Б—В—А–Њ–є–Ї–µ.
3 –Э–∞—Б—В—А–Њ–є–Ї–∞
1 –Ш–љ–Є—Ж–Є–∞–ї–Є–Ј–∞—Ж–Є—П Bucardo
–Ч–∞–њ—Г—Б–Ї–∞–µ–Љ —Г—Б—В–∞–љ–Њ–≤–Ї—Г –Ї–Њ–Љ–∞–љ–і–Њ–є:![\begin{lstlisting}[label=lst:bucardo5,caption=–Ш–љ–Є—Ж–Є–∞–ї–Є–Ј–∞—Ж–Є—П Bucardo]
bucardo_ctl install
\end{lstlisting}](postgresql-img33.png)
Bucardo –њ–Њ–Ї–∞–ґ–µ—В –љ–∞—Б—В—А–Њ–є–Ї–Є –њ–Њ–і–Ї–ї—О—З–µ–љ–Є—П –Ї PostgreSQL, –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–ґ–љ–Њ –±—Г–і–µ—В –Є–Ј–Љ–µ–љ–Є—В—М:
–Ъ–Њ–≥–і–∞ –≤—Л –Є–Ј–Љ–µ–љ–Є—В–µ —В—А–µ–±—Г–µ–Љ—Л–µ –љ–∞—Б—В—А–Њ–є–Ї–Є –Є –њ–Њ–і—В–≤–µ—А–і–Є—В–µ —Г—Б—В–∞–љ–Њ–≤–Ї—Г, Bucardo —Б–Њ–Ј–і–∞—Б—В –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П bucardo –Є –±–∞–Ј—Г –і–∞–љ–љ—Л—Е bucardo. –Ф–∞–љ–љ—Л–є –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М –і–Њ–ї–ґ–µ–љ –Є–Љ–µ—В—М –њ—А–∞–≤–Њ –ї–Њ–≥–Є–љ–Є—В—Б—П —З–µ—А–µ–Ј Unix socket, –њ–Њ—Н—В–Њ–Љ—Г –ї—Г—З—И–µ –Ј–∞—А–∞–љ–µ–µ –і–∞—В—М –µ–Љ—Г —В–∞–Ї–Є–µ –њ—А–∞–≤–∞ –≤ pg_hda.conf.
2 –Э–∞—Б—В—А–Њ–є–Ї–∞ –±–∞–Ј –і–∞–љ–љ—Л—Е
–Ґ–µ–њ–µ—А—М –љ–∞–Љ –љ—Г–ґ–љ–Њ –љ–∞—Б—В—А–Њ–Є—В—М –±–∞–Ј—Л –і–∞–љ–љ—Л—Е, —Б –Ї–Њ—В–Њ—А—Л–Љ–Є –±—Г–і–µ—В —А–∞–±–Њ—В–∞—В—М Bucardo. –Я—Г—Б—В—М —Г –љ–∞—Б –±—Г–і–µ—В master_db –Є slave_db. –°–љ–∞—З–∞–ї–∞ –љ–∞—Б—В—А–Њ–Є–Љ –Љ–∞—Б—В–µ—А:
–Я–µ—А–≤–Њ–є –Ї–Њ–Љ–∞–љ–і–Њ–є –Љ—Л —Г–Ї–∞–Ј–∞–ї–Є –±–∞–Ј—Г –і–∞–љ–љ—Л—Е –Є –і–∞–ї–Є –µ–є –Є–Љ—П master (–і–ї—П —В–Њ–≥–Њ, —З—В–Њ –≤ —А–µ–∞–ї—М–љ–Њ–є –ґ–Є–Ј–љ–Є master_db –Є slave_db –Є–Љ–µ—О—В –Њ–і–Є–љ–∞–Ї–Њ–≤–Њ–µ –љ–∞–Ј–≤–∞–љ–Є–µ –Є –Є—Е –љ—Г–ґ–љ–Њ Bucardo –Њ—В–ї–Є—З–∞—В—М). –Т—В–Њ—А–Њ–є –Є —В—А–µ—В–µ–є –Ї–Њ–Љ–∞–љ–і–Њ–є –Љ—Л —Г–Ї–∞–Ј–∞–ї–Є —А–µ–њ–ї–Є—Ж—Л—А–Њ–≤–∞—В—М –≤—Б–µ —В–∞–±–ї–Є—Ж—Л –Є –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ–Њ—Б—В–Є, –Њ–±—М–µ–і–µ–љ–Є–≤ –Є—Е –≤ –≥—А—Г–њ—Г all_tables.
–Ф–∞–ї—М—И–µ –і–Њ–±–∞–≤–ї—П–µ–Љ slave_db:

–Ь—Л –љ–∞–Ј–≤–∞–ї–Є replica –±–∞–Ј—Г –і–∞–љ–љ—Л—Е –≤ Bucardo.
3 –Э–∞—Б—В—А–Њ–є–Ї–∞ —Б–Є–љ—Е—А–Њ–љ–Є–Ј–∞—Ж–Є–Є
–Ґ–µ–њ–µ—А—М –љ–∞–Љ –љ—Г–ґ–љ–Њ –љ–∞—Б—В—А–Њ–Є—В—М —Б–Є–љ—Е—А–Њ–љ–Є–Ј–∞—Ж–Є—О –Љ–µ–ґ–і—Г —Н—В–Є–Љ–Є –±–∞–Ј–∞–Љ–Є –і–∞–љ–љ—Л—Е. –Ф–µ–ї–∞–µ—В—Б—П —Н—В–Њ –Ї–Њ–Љ–∞–љ–і–Њ–є (master-slave):
–Ф–∞–љ–љ–Њ–є –Ї–Њ–Љ–∞–љ–і–Њ–є –Љ—Л —Г—Б—В–∞–љ–Њ–≤–Є–Љ Bucardo —В—А–Є–≥–µ—А—Л –≤ PostgreSQL. –Р —В–µ–њ–µ—А—М –њ–Њ –њ–∞—А–∞–Љ–µ—В—А–∞–Љ:
- type
–≠—В–Њ —В–Є–њ —Б–Є–љ—Е—А–Њ–љ–Є–Ј–∞—Ж–Є–Є. –°—Г—Й–µ—Б—В–≤—Г–µ—В 3 —В–Є–њ–∞:
- Fullcopy. –Я–Њ–ї–љ–Њ–µ –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є–µ.
- Pushdelta. Master-slave —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П.
- Swap. Master-master —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П.
–Ф–ї—П —А–∞–±–Њ—В—Л –≤ —В–∞–Ї–Њ–Љ —А–µ–ґ–Є–Љ–µ –њ–Њ—В—А–µ–±—Г–µ—В—Б—П —Г–Ї–∞–Ј–∞—В—М –Ї–∞–Ї Bucardo –і–Њ–ї–ґ–µ–љ —А–µ—И–∞—В—М –Ї–Њ–љ—Д–ї–Є–Ї—В—Л —Б–Є–љ—Е—А–Њ–љ–Є–Ј–∞—Ж–Є–Є.
–Ф–ї—П —Н—В–Њ–≥–Њ –≤ —В–∞–±–ї–Є—Ж–µ «goat» (–≤ –Ї–Њ—В–Њ—А–Њ–є –љ–∞—Е–Њ–і—П—В—Б—П —В–∞–±–ї–Є—Ж—Л –Є –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ–Њ—Б—В–Є) –љ—Г–ґ–љ–Њ –≤ «standard_conflict»
–њ–Њ–ї–µ –њ–Њ—Б—В–∞–≤–Є—В—М –Ј–љ–∞—З–µ–љ–Є–µ (—Н—В–Њ –Ј–љ–∞—З–µ–љ–Є–µ –Љ–Њ–ґ–µ—В –±—Л—В—М —А–∞–Ј–љ—Л–Љ –і–ї—П —А–∞–Ј–љ—Л—Е —В–∞–±–ї–Є—Ж –Є –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ–Њ—Б—В–µ–є):
- source -- –њ—А–Є –Ї–Њ–љ—Д–ї–Є–Ї—В–µ –Љ—Л –Ї–Њ–њ–Є—А—Г–µ–Љ –і–∞–љ–љ—Л–µ —Б source (master_db –≤ –љ–∞—И–µ–Љ —Б–ї—Г—З–∞–µ).
- target -- –њ—А–Є –Ї–Њ–љ—Д–ї–Є–Ї—В–µ –Љ—Л –Ї–Њ–њ–Є—А—Г–µ–Љ –і–∞–љ–љ—Л–µ —Б target (slave_db –≤ –љ–∞—И–µ–Љ —Б–ї—Г—З–∞–µ).
- skip -- –Ї–Њ–љ—Д–ї–Є–Ї—В –Љ—Л –њ—А–Њ—Б—В–Њ –љ–µ —А–µ–њ–ї–Є—Ж–Є—А—Г–µ–Љ. –Э–µ —А–µ–Ї–Њ–Љ–µ–љ–і—Г–µ—В—Б—П.
- random -- –Ї–∞–ґ–і–∞—П –С–Ф –Є–Љ–µ–µ—В –Њ–і–Є–љ–∞–Ї–Њ–≤—Л–є —И–∞–љ—Б, —З—В–Њ –µ—С –Є–Ј–Љ–µ–љ–µ–љ–Є–µ –±—Г–і–µ—В –≤–Ј—П—В–Њ –і–ї—П —А–µ—И–µ–љ–Є–µ –Ї–Њ–љ—Д–ї–Є–Ї—В–∞.
- latest -- –Ј–∞–њ–Є—Б—М, –Ї–Њ—В–Њ—А–∞—П –±—Л–ї–∞ –њ–Њ—Б–ї–µ–і–љ–µ–є –Є–Ј–Љ–µ–љ–µ–љ–∞ —А–µ—И–∞–µ—В –Ї–Њ–љ—Д–ї–Є–Ї—В.
- abort -- —Б–Є–љ—Е—А–Њ–љ–Є–Ј–∞—Ж–Є—П –њ—А–µ—А—Л–≤–∞–µ—В—Б—П.
- source
–Ш—Б—В–Њ—З–љ–Є–Ї —Б–Є–љ—Е—А–Њ–љ–Є–Ј–∞—Ж–Є–Є.
- targetdb
–С–Ф, –≤ –Ї–Њ—В–Њ—А—Г–Љ –њ—А–Њ–Є–Ј–≤–Њ–і–Є–Љ —А–µ–њ–ї–Є–Ї–∞—Ж–Є—О.
–Ф–ї—П master-master:

4 –Ч–∞–њ—Г—Б–Ї/–Ю—Б—В–∞–љ–Њ–≤–Ї–∞ —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є
–Ч–∞–њ—Г—Б–Ї —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є:![\begin{lstlisting}[label=lst:bucardo11,caption=–Ч–∞–њ—Г—Б–Ї —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є]
bucardo_ctl start
\end{lstlisting}](postgresql-img39.png)
–Ю—Б—В–∞–љ–Њ–≤–Ї–∞ —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є:
![\begin{lstlisting}[label=lst:bucardo12,caption=–Ю—Б—В–∞–љ–Њ–≤–Ї–∞ —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є]
bucardo_ctl stop
\end{lstlisting}](postgresql-img40.png)
4 –Ю–±—Й–Є–µ –Ј–∞–і–∞—З–Є
1 –Я—А–Њ—Б–Љ–Њ—В—А –Ј–љ–∞—З–µ–љ–Є–є –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–Є
–Я—А–Њ—Б—В–Њ –Є—Б–њ–Њ–ї—М–Ј—Г—П —Н—В—Г –Ї–Њ–Љ–∞–љ–і—Г:![\begin{lstlisting}[label=lst:bucardo13,caption=–Я—А–Њ—Б–Љ–Њ—В—А –Ј–љ–∞—З–µ–љ–Є–є –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–Є]
bucardo_ctl show all
\end{lstlisting}](postgresql-img41.png)
2 –Ш–Ј–Љ–µ–љ–µ–љ–Є—П –Ј–љ–∞—З–µ–љ–Є–є –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–Є
![\begin{lstlisting}[label=lst:bucardo14,caption=–Ш–Ј–Љ–µ–љ–µ–љ–Є—П –Ј–љ–∞—З–µ–љ–Є–є –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–Є–Є]
bucardo_ctl set name=value
\end{lstlisting}](postgresql-img42.png)
–Э–∞–њ—А–Є–Љ–µ—А:
![\begin{lstlisting}[label=lst:bucardo15,caption=–Ш–Ј–Љ–µ–љ–µ–љ–Є—П –Ј–љ–∞—З–µ–љ–Є...
...љ—Д–Є–≥—Г—А–∞—Ж–Є–Є]
bucardo_ctl set syslog_facility=LOG_LOCAL3
\end{lstlisting}](postgresql-img43.png)
3 –Я–µ—А–µ–≥—А—Г–Ј–Ї–∞ –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–Є
![\begin{lstlisting}[label=lst:bucardo16,caption=–Я–µ—А–µ–≥—А—Г–Ј–Ї–∞ –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–Є]
bucardo_ctl reload_config
\end{lstlisting}](postgresql-img44.png)
–С–Њ–ї–µ–µ –њ–Њ–ї–љ—Л–є —Б–њ–Є—Б–Њ–Ї –Ї–Њ–Љ–∞–љ–і -- http://bucardo.org/wiki/Bucardo_ctl
3 –Ч–∞–Ї–ї—О—З–µ–љ–Є–µ
–†–µ–њ–ї–Є–Ї–∞—Ж–Є—П -- –Њ–і–љ–∞ –Є–Ј –≤–∞–ґ–љ–µ–є—И–Є—Е —З–∞—Б—В–µ–є –Ї—А—Г–њ–љ—Л—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є, –Ї–Њ—В–Њ—А—Л–µ —А–∞–±–Њ—В–∞—О—В –љ–∞ PostgreSQL. –Ю–љ–∞ –њ–Њ–Љ–Њ–≥–∞–µ—В —А–∞—Б–њ—А–µ–і–µ–ї—П—В—М –љ–∞–≥—А—Г–Ј–Ї—Г –љ–∞ –±–∞–Ј—Г –і–∞–љ–љ—Л—Е, –і–µ–ї–∞—В—М —Д–Њ–љ–Њ–≤—Л–є –±—Н–Ї–∞–њ –Њ–і–љ–Њ–є –Є–Ј –Ї–Њ–њ–Є–є –±–µ–Ј –љ–∞–≥—А—Г–Ј–Ї–Є –љ–∞ —Ж–µ–љ—В—А–∞–ї—М–љ—Л–є —Б–µ—А–≤–µ—А, —Б–Њ–Ј–і–∞–≤–∞—В—М –Њ—В–і–µ–ї—М–љ—Л–є —Б–µ—А–≤–µ—А –і–ї—П –ї–Њ–≥–Є—А–Њ–≤–∞–љ–Є—П –Є –Љ.–і.–Т –≥–ї–∞–≤–µ –±—Л–ї–Њ —А–∞—Б—Б–Љ–Њ—В—А–µ–љ–Њ –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –≤–Є–і–Њ–≤ —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є PostgreSQL. –Э–µ–ї—М–Ј—П —З–µ—В–Ї–Њ —Б–Ї–∞–Ј–∞—В—М –Ї–∞–Ї–∞—П –ї—Г—З—И–µ –≤—Б–µ—Е. –Я–Њ—В–Њ–Ї–Њ–≤–∞—П —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П -- –Њ–і–љ–∞ –Є–Ј —Б–∞–Љ—Л—Е –ї—Г—З—И–Є—Е –≤–∞—А–Є–∞–љ—В–Њ–≤ –і–ї—П –њ–Њ–і–і–µ—А–ґ–Ї–Є –Є–і–µ–љ—В–Є—З–љ—Л—Е –Ї–ї–∞—Б—В–µ—А–Њ–≤ –±–∞–Ј –і–∞–љ–љ—Л—Е, –љ–Њ –і–Њ—Б—В—Г–њ–љ–∞ —В–Њ–ї—М–Ї–Њ —Б 9.0 –≤–µ—А—Б–Є–Є PostgreSQL. Slony-I -- –≥—А–Њ–Љ–Њ–Ј–і–Ї–∞—П –Є —Б–ї–Њ–ґ–љ–∞—П –≤ –љ–∞—Б—В—А–Њ–є–Ї–µ —Б–Є—Б—В–µ–Љ–∞, –љ–Њ –Є–Љ–µ—О—Й–∞—П –≤ —Б–≤–Њ–µ–Љ –∞—А—Б–µ–љ–∞–ї–µ –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ —Д—Г–љ–Ї—Ж–Є–є, —В–∞–Ї–Є—Е –Ї–∞–Ї –њ–Њ–і–і–µ—А–ґ–Ї–∞ –Ї–∞—Б–Ї–∞–і–љ–Њ–є —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є, –Њ—В–Ї–∞–Ј–Њ—Г—Б—В–Њ–є—З–Є–≤–Њ—Б—В–Є (failover) –Є –њ–µ—А–µ–Ї–ї—О—З–µ–љ–Є–µ –Љ–µ–ґ–і—Г —Б–µ—А–≤–µ—А–∞–Љ–Є (switchover). –Т —В–Њ–ґ–µ –≤—А–µ–Љ—П Londiste –љ–µ –Њ–±–ї–∞–і–∞–µ—В –њ–Њ–і–Њ–±–љ—Л–Љ —Д—Г–љ–Ї—Ж–Є–Њ–љ–∞–ї–Њ–Љ, –љ–Њ –Ї–Њ–Љ–њ–∞–Ї—В–љ—Л–є –Є –њ—А–Њ—Б—В –≤ —Г—Б—В–∞–љ–Њ–≤–Ї–µ. Bucardo -- —Б–Є—Б—В–µ–Љ–∞ –Ї–Њ—В–Њ—А–∞—П –Љ–Њ–ґ–µ—В –±—Л—В—М –Є–ї–Є master-master, –Є–ї–Є master-slave —А–µ–њ–ї–Є–Ї–∞—Ж–Є–µ–є, –љ–Њ –љ–µ –Љ–Њ–ґ–µ—В –Њ–±—А–∞–±–Њ—В–∞—В—М –Њ–≥—А–Њ–Љ–љ—Л–µ –Њ–±—М–µ–Ї—В—Л, –љ–µ—В –Њ—В–Ї–∞–Ј–Њ—Г—Б—В–Њ–є—З–Є–≤–Њ—Б—В–Є(failover) –Є –њ–µ—А–µ–Ї–ї—О—З–µ–љ–Є–µ –Љ–µ–ґ–і—Г —Б–µ—А–≤–µ—А–∞–Љ–Є (switchover). RubyRep, –Ї–∞–Ї –і–ї—П master-master —А–µ–њ–ї–Є–Ї–∞—Ж–Є–Є, –Њ—З–µ–љ—М –њ—А–Њ—Б—В–Њ –≤ —Г—Б—В–∞–љ–Њ–≤–Ї–µ –Є –љ–∞—Б—В—А–Њ–є–Ї–µ, –љ–Њ –Ј–∞ —Н—В–Њ –µ–Љ—Г –њ—А–Є—Е–Њ–і–Є—В—Б—П —А–∞—Б–њ–ї–∞—З–Є–≤–∞—В—Б—П —Б–Ї–Њ—А–Њ—Б—В—М—О —А–∞–±–Њ—В—Л -- —Б–∞–Љ—Л–є –Љ–µ–і–ї–µ–љ–љ—Л–є –Є–Ј –≤—Б–µ—Е (—Б–Є–љ—Е—А–Њ–љ–Є–Ј–∞—Ж–Є—П –±–Њ–ї—М—И–Є—Е –Њ–±—М–µ–Љ–Њ–≤ –і–∞–љ–љ—Л—Е –Љ–µ–ґ–і—Г —В–∞–±–ї–Є—Ж–∞–Љ–Є).
5 –®–∞—А–і–Є–љ–≥

1 –Т–≤–µ–і–µ–љ–Є–µ
–®–∞—А–і–Є–љ–≥ -- —А–∞–Ј–і–µ–ї–µ–љ–Є–µ –і–∞–љ–љ—Л—Е –љ–∞ —Г—А–Њ–≤–љ–µ —А–µ—Б—Г—А—Б–Њ–≤. –Ъ–Њ–љ—Ж–µ–њ—Ж–Є—П —И–∞—А–і–Є–љ–≥–∞ –Ј–∞–Ї–ї—О—З–∞–µ—В—Б—П –≤ –ї–Њ–≥–Є—З–µ—Б–Ї–Њ–Љ —А–∞–Ј–і–µ–ї–µ–љ–Є–Є –і–∞–љ–љ—Л—Е –њ–Њ —А–∞–Ј–ї–Є—З–љ—Л–Љ —А–µ—Б—Г—А—Б–∞–Љ –Є—Б—Е–Њ–і—П –Є–Ј —В—А–µ–±–Њ–≤–∞–љ–Є–є –Ї –љ–∞–≥—А—Г–Ј–Ї–µ.–†–∞—Б—Б–Љ–Њ—В—А–Є–Љ –њ—А–Є–Љ–µ—А. –Я—Г—Б—В—М —Г –љ–∞—Б –µ—Б—В—М –њ—А–Є–ї–Њ–ґ–µ–љ–Є–µ —Б —А–µ–≥–Є—Б—В—А–∞—Ж–Є–µ–є –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є, –Ї–Њ—В–Њ—А–Њ–µ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –њ–Є—Б–∞—В—М –і—А—Г–≥ –і—А—Г–≥—Г –ї–Є—З–љ—Л–µ —Б–Њ–Њ–±—Й–µ–љ–Є—П. –Ф–Њ–њ—Г—Б—В–Є–Љ –Њ–љ–Њ –Њ—З–µ–љ—М –њ–Њ–њ—Г–ї—П—А–љ–Њ –Є –Љ–љ–Њ–≥–Њ –ї—О–і–µ–є –Є–Љ –њ–Њ–ї—М–Ј—Г—О—В—Б—П –µ–ґ–µ–і–љ–µ–≤–љ–Њ. –Х—Б—В–µ—Б—В–≤–µ–љ–љ–Њ, —З—В–Њ —В–∞–±–ї–Є—Ж–∞ —Б –ї–Є—З–љ—Л–Љ–Є —Б–Њ–Њ–±—Й–µ–љ–Є—П–Љ–Є –±—Г–і–µ—В –љ–∞–Љ–љ–Њ–≥–Њ –±–Њ–ї—М—И–µ –≤—Б–µ—Е –Њ—Б—В–∞–ї—М–љ—Л—Е —В–∞–±–ї–Є—Ж –≤ –±–∞–Ј–µ (—Б–Ї–∞–ґ–µ–Љ, –±—Г–і–µ—В –Ј–∞–љ–Є–Љ–∞—В—М 90% –≤—Б–µ—Е —А–µ—Б—Г—А—Б–Њ–≤). –Ч–љ–∞—П —Н—В–Њ, –Љ—Л –Љ–Њ–ґ–µ–Љ –њ–Њ–і–≥–Њ—В–Њ–≤–Є—В—М –і–ї—П —Н—В–Њ–є (—В–Њ–ї—М–Ї–Њ –Њ–і–љ–Њ–є!) —В–∞–±–ї–Є—Ж—Л –≤—Л–і–µ–ї–µ–љ–љ—Л–є —Б–µ—А–≤–µ—А –њ–Њ–Љ–Њ—Й–љ–µ–µ, –∞ –Њ—Б—В–∞–ї—М–љ—Л–µ –Њ—Б—В–∞–≤–Є—В—М –љ–∞ –і—А—Г–≥–Њ–Љ (–њ–Њ—Б–ї–∞–±–µ–µ). –Ґ–µ–њ–µ—А—М –Љ—Л –Љ–Њ–ґ–µ–Љ –Є–і–µ–∞–ї—М–љ–Њ –њ–Њ–і—Б—В—А–Њ–Є—В—М —Б–µ—А–≤–µ—А –і–ї—П —А–∞–±–Њ—В—Л —Б –Њ–і–љ–Њ–є —Б–њ–µ—Ж–Є—Д–Є—З–µ—Б–Ї–Њ–є —В–∞–±–ї–Є—Ж–µ–є, –њ–Њ—Б—В–∞—А–∞—В—М—Б—П —Г–Љ–µ—Б—В–Є—В—М –µ–µ –≤ –њ–∞–Љ—П—В—М, –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ, –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ–Њ –њ–∞—А—В–Є—Ж–Є–Њ–љ–Є—А–Њ–≤–∞—В—М –µ–µ –Є —В.–і. –Ґ–∞–Ї–Њ–µ —А–∞—Б–њ—А–µ–і–µ–ї–µ–љ–Є–µ –љ–∞–Ј—Л–≤–∞–µ—В—Б—П –≤–µ—А—В–Є–Ї–∞–ї—М–љ—Л–Љ —И–∞—А–і–Є–љ–≥–Њ–Љ.
–І—В–Њ –і–µ–ї–∞—В—М, –µ—Б–ї–Є –љ–∞—И–∞ —В–∞–±–ї–Є—Ж–∞ —Б —Б–Њ–Њ–±—Й–µ–љ–Є—П–Љ–Є —Б—В–∞–ї–∞ –љ–∞—Б—В–Њ–ї—М–Ї–Њ –±–Њ–ї—М—И–Њ–є, —З—В–Њ –і–∞–ґ–µ –≤—Л–і–µ–ї–µ–љ–љ—Л–є —Б–µ—А–≤–µ—А –њ–Њ–і –љ–µ–µ –Њ–і–љ—Г —Г–ґ–µ –љ–µ —Б–њ–∞—Б–∞–µ—В. –Э–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –і–µ–ї–∞—В—М –≥–Њ—А–Є–Ј–Њ–љ—В–∞–ї—М–љ—Л–є —И–∞—А–і–Є–љ–≥ -- —В.–µ. —А–∞–Ј–і–µ–ї–µ–љ–Є–µ –Њ–і–љ–Њ–є —В–∞–±–ї–Є—Ж—Л –њ–Њ —А–∞–Ј–љ—Л–Љ —А–µ—Б—Г—А—Б–∞–Љ. –Ъ–∞–Ї —Н—В–Њ –≤—Л–≥–ї—П–і–Є—В –љ–∞ –њ—А–∞–Ї—В–Є–Ї–µ? –Т—Б–µ –њ—А–Њ—Б—В–Њ. –Э–∞ —А–∞–Ј–љ—Л—Е —Б–µ—А–≤–µ—А–∞—Е —Г –љ–∞—Б –±—Г–і–µ—В —В–∞–±–ї–Є—Ж–∞ —Б –Њ–і–Є–љ–∞–Ї–Њ–≤–Њ–є —Б—В—А—Г–Ї—В—Г—А–Њ–є, –љ–Њ —А–∞–Ј–љ—Л–Љ–Є –і–∞–љ–љ—Л–Љ–Є. –Ф–ї—П –љ–∞—И–µ–≥–Њ —Б–ї—Г—З–∞—П —Б —Б–Њ–Њ–±—Й–µ–љ–Є—П–Љ–Є, –Љ—Л –Љ–Њ–ґ–µ–Љ —Е—А–∞–љ–Є—В—М –њ–µ—А–≤—Л–µ 10 –Љ–Є–ї–ї–Є–Њ–љ–Њ–≤ —Б–Њ–Њ–±—Й–µ–љ–Є–є –љ–∞ –Њ–і–љ–Њ–Љ —Б–µ—А–≤–µ—А–µ, –≤—В–Њ—А—Л–µ 10 - –љ–∞ –≤—В–Њ—А–Њ–Љ –Є —В.–і. –Ґ.–µ. –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –Є–Љ–µ—В—М –Ї—А–Є—В–µ—А–Є–є —И–∞—А–і–Є–љ–≥–∞ -- –Ї–∞–Ї–Њ–є-—В–Њ –њ–∞—А–∞–Љ–µ—В—А, –Ї–Њ—В–Њ—А—Л–є –њ–Њ–Ј–≤–Њ–ї–Є—В –Њ–њ—А–µ–і–µ–ї—П—В—М, –љ–∞ –Ї–∞–Ї–Њ–Љ –Є–Љ–µ–љ–љ–Њ —Б–µ—А–≤–µ—А–µ –ї–µ–ґ–∞—В —В–µ –Є–ї–Є –Є–љ—Л–µ –і–∞–љ–љ—Л–µ.
–Ю–±—Л—З–љ–Њ, –≤ –Ї–∞—З–µ—Б—В–≤–µ –њ–∞—А–∞–Љ–µ—В—А–∞ —И–∞—А–і–Є–љ–≥–∞ –≤—Л–±–Є—А–∞—О—В ID –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П (user_id) -- —Н—В–Њ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –і–µ–ї–Є—В—М –і–∞–љ–љ—Л–µ –њ–Њ —Б–µ—А–≤–µ—А–∞–Љ —А–∞–≤–љ–Њ–Љ–µ—А–љ–Њ –Є –њ—А–Њ—Б—В–Њ. –Ґ.–Њ. –њ—А–Є –њ–Њ–ї—Г—З–µ–љ–Є–Є –ї–Є—З–љ—Л—Е —Б–Њ–Њ–±—Й–µ–љ–Є–є –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є –∞–ї–≥–Њ—А–Є—В–Љ —А–∞–±–Њ—В—Л –±—Г–і–µ—В —В–∞–Ї–Њ–є:
- –Ю–њ—А–µ–і–µ–ї–Є—В—М, –љ–∞ –Ї–∞–Ї–Њ–Љ —Б–µ—А–≤–µ—А–µ –С–Ф –ї–µ–ґ–∞—В —Б–Њ–Њ–±—Й–µ–љ–Є—П –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П –Є—Б—Е–Њ–і—П –Є–Ј user_id
- –Ш–љ–Є—Ж–Є–∞–ї–Є–Ј–Є—А–Њ–≤–∞—В—М —Б–Њ–µ–і–Є–љ–µ–љ–Є–µ —Б —Н—В–Є–Љ —Б–µ—А–≤–µ—А–Њ–Љ
- –Т—Л–±—А–∞—В—М —Б–Њ–Њ–±—Й–µ–љ–Є—П
–Ч–∞–і–∞—З—Г –Њ–њ—А–µ–і–µ–ї–µ–љ–Є—П –Ї–Њ–љ–Ї—А–µ—В–љ–Њ–≥–Њ —Б–µ—А–≤–µ—А–∞ –Љ–Њ–ґ–љ–Њ —А–µ—И–∞—В—М –і–≤—Г–Љ—П –њ—Г—В—П–Љ–Є:
- –•—А–∞–љ–Є—В—М –≤ –Њ–і–љ–Њ–Љ –Љ–µ—Б—В–µ —Е–µ—И-—В–∞–±–ї–Є—Ж—Г —Б —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є—П–Љ–Є «–њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М=—Б–µ—А–≤–µ—А». –Ґ–Њ–≥–і–∞, –њ—А–Є –Њ–њ—А–µ–і–µ–ї–µ–љ–Є–Є —Б–µ—А–≤–µ—А–∞, –љ—Г–ґ–љ–Њ –±—Г–і–µ—В –≤—Л–±—А–∞—В—М —Б–µ—А–≤–µ—А –Є–Ј —Н—В–Њ–є —В–∞–±–ї–Є—Ж—Л. –Т —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ —Г–Ј–Ї–Њ–µ –Љ–µ—Б—В–Њ -- —Н—В–Њ –±–Њ–ї—М—И–∞—П —В–∞–±–ї–Є—Ж–∞ —Б–Њ–Њ—В–≤–µ—В—Б–≤–Є—П, –Ї–Њ—В–Њ—А—Г—О –љ—Г–ґ–љ–Њ —Е—А–∞–љ–Є—В—М –≤ –Њ–і–љ–Њ–Љ –Љ–µ—Б—В–µ. –Ф–ї—П —В–∞–Ї–Є—Е —Ж–µ–ї–µ–є –Њ—З–µ–љ—М —Е–Њ—А–Њ—И–Њ –њ–Њ–і—Е–Њ–і—П—В –±–∞–Ј—Л –і–∞–љ–љ—Л—Е «–Ї–ї—О—З=–Ј–љ–∞—З–µ–љ–Є–µ»
- –Ю–њ—А–µ–і–µ–ї—П—В—М –Є–Љ—П —Б–µ—А–≤–µ—А–∞ —Б –њ–Њ–Љ–Њ—Й—М—О —З–Є—Б–ї–Њ–≤–Њ–≥–Њ (–±—Г–Ї–≤–µ–љ–љ–Њ–≥–Њ) –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є—П. –Э–∞–њ—А–Є–Љ–µ—А, –Љ–Њ–ґ–љ–Њ –≤—Л—З–Є—Б–ї—П—В—М –љ–Њ–Љ–µ—А —Б–µ—А–≤–µ—А–∞, –Ї–∞–Ї –Њ—Б—В–∞—В–Њ–Ї –Њ—В –і–µ–ї–µ–љ–Є—П –љ–∞ –Њ–њ—А–µ–і–µ–ї–µ–љ–љ–Њ–µ —З–Є—Б–ї–Њ (–Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б–µ—А–≤–µ—А–Њ–≤, –Љ–µ–ґ–і—Г –Ї–Њ—В–Њ—А—Л–Љ–Є –Т—Л –і–µ–ї–Є—В–µ —В–∞–±–ї–Є—Ж—Г). –Т —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ —Г–Ј–Ї–Њ–µ –Љ–µ—Б—В–Њ -- —Н—В–Њ –њ—А–Њ–±–ї–µ–Љ–∞ –і–Њ–±–∞–≤–ї–µ–љ–Є—П –љ–Њ–≤—Л—Е —Б–µ—А–≤–µ—А–Њ–≤ -- –Т–∞–Љ –њ—А–Є–і–µ—В—Б—П –і–µ–ї–∞—В—М –њ–µ—А–µ—А–∞—Б–њ—А–µ–і–µ–ї–µ–љ–Є–µ –і–∞–љ–љ—Л—Е –Љ–µ–ґ–і—Г –љ–Њ–≤—Л–Љ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ–Љ —Б–µ—А–≤–µ—А–Њ–≤.
–Ф–ї—П —И–∞—А–і–Є–љ–≥–∞ –љ–µ —Б—Г—Й–µ—Б—В–≤—Г–µ—В —А–µ—И–µ–љ–Є—П –љ–∞ —Г—А–Њ–≤–љ–µ –Є–Ј–≤–µ—Б—В–љ—Л—Е –њ–ї–∞—В—Д–Њ—А–Љ, —В.–Ї. —Н—В–Њ –≤–µ—Б—М–Љ–∞ —Б–њ–µ—Ж–Є—Д–Є—З–µ—Б–Ї–∞—П –і–ї—П –Њ—В–і–µ–ї—М–љ–Њ –≤–Ј—П—В–Њ–≥–Њ –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П –Ј–∞–і–∞—З–∞.
–Х—Б—В–µ—Б—В–≤–µ–љ–љ–Њ, –і–µ–ї–∞—П –≥–Њ—А–Є–Ј–Њ–љ—В–∞–ї—М–љ—Л–є —И–∞—А–і–Є–љ–≥, –Т—Л –Њ–≥—А–∞–љ–Є—З–Є–≤–∞–µ—В–µ —Б–µ–±—П –≤ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є –≤—Л–±–Њ—А–Њ–Ї, –Ї–Њ—В–Њ—А—Л–µ —В—А–µ–±—Г—О—В –њ–µ—А–µ—Б–Љ–Њ—В—А–∞ –≤—Б–µ–є —В–∞–±–ї–Є—Ж—Л (–љ–∞–њ—А–Є–Љ–µ—А, –њ–Њ—Б–ї–µ–і–љ–Є–µ –њ–Њ—Б—В—Л –≤ –±–ї–Њ–≥–∞—Е –ї—О–і–µ–є –±—Г–і–µ—В –і–Њ—Б—В–∞—В—М –љ–µ–≤–Њ–Ј–Љ–Њ–ґ–љ–Њ, –µ—Б–ї–Є —В–∞–±–ї–Є—Ж–∞ –њ–Њ—Б—В–Њ–≤ —И–∞—А–і–Є—В—Б—П). –Ґ–∞–Ї–Є–µ –Ј–∞–і–∞—З–Є –њ—А–Є–і–µ—В—Б—П —А–µ—И–∞—В—М –і—А—Г–≥–Є–Љ–Є –њ–Њ–і—Е–Њ–і–∞–Љ–Є. –Э–∞–њ—А–Є–Љ–µ—А, –і–ї—П –Њ–њ–Є—Б–∞–љ–љ–Њ–≥–Њ –њ—А–Є–Љ–µ—А–∞, –Љ–Њ–ґ–љ–Њ –њ—А–Є –њ–Њ—П–≤–ї–µ–љ–Є–Є –љ–Њ–≤–Њ–≥–Њ –њ–Њ—Б—В–∞, –Ј–∞–љ–Њ—Б–Є—В—М –µ–≥–Њ ID –≤ –Њ–±—Й–Є–є —Б—В–µ–Ї, —А–∞–Ј–Љ–µ—А–Њ–Љ –≤ 100 —Н–ї–µ–Љ–µ–љ—В–Њ–Љ.
–У–Њ—А–Є–Ј–Њ–љ—В–∞–ї—М–љ—Л–є —И–∞—А–і–Є–љ–≥ –Є–Љ–µ–µ—В –Њ–і–љ–Њ —П–≤–љ–Њ–µ –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–Њ -- –Њ–љ –±–µ—Б–Ї–Њ–љ–µ—З–љ–Њ –Љ–∞—Б—И—В–∞–±–Є—А—Г–µ–Љ. –Ф–ї—П —Б–Њ–Ј–і–∞–љ–Є—П —И–∞—А–і–Є–љ–≥–∞ PostgreSQL —Б—Г—Й–µ—Б—В–≤—Г–µ—В –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ —А–µ—И–µ–љ–Є–є:
- Greenplum Database23
- GridSQL for EnterpriseDB Advanced Server24
- Sequoia25
- PL/Proxy26
- HadoopDB27 (Shared-nothing clustering)
2 –Ч–∞–Ї–ї—О—З–µ–љ–Є–µ
–Т –і–∞–љ–љ–Њ–є –≥–ї–∞–≤–µ —А–∞—Б–Љ–Њ—В—А–µ–љ–Њ –ї–Є—И –±–∞–Ј–Њ–≤—Л–µ –љ–∞—Б—В—А–Њ–є–Ї–Є –Ї–ї–∞—Б—В–µ—А–Њ–≤ –С–Ф. –Я—А–Њ –Ї–ї–∞—Б—В–µ—А—Л PostgreSQL –њ–Њ—В—А–µ–±—Г–µ—В—Б—П –љ–∞–њ–Є—Б–∞—В—М –Њ—В–і–µ–ї—М–љ—Г—О –Ї–љ–Є–≥—Г, —З—В–Њ–±—Л —А–∞—Б—В–Љ–Њ—В—А–µ—В—М –≤—Б–µ —И–∞–≥–Є —Б —Г—Б—В–∞–љ–Њ–≤–Ї–Њ–є, –љ–∞—Б—В—А–Њ–є–Ї–Њ–є –Є —А–∞–±–Њ—В–Њ–є –Ї–ї–∞—Б—В–µ—А–Њ–≤. –Э–∞–і–µ—О—Б—М, —З—В–Њ –љ–µ—Б–Љ–Њ—В—А—П –љ–∞ —Н—В–Њ, –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –±—Г–і–µ—В –њ–Њ–ї–µ–Ј–љ–∞ –Љ–љ–Њ–≥–Є–Љ —З–Є—В–∞—В–µ–ї—П–Љ.6 –Ь—Г–ї—М—В–Є–њ–ї–µ–Ї—Б–Њ—А—Л —Б–Њ–µ–і–Є–љ–µ–љ–Є–є

1 –Т–≤–µ–і–µ–љ–Є–µ
–Ь—Г–ї—М—В–Є–њ–ї–µ–Ї—Б–Њ—А—Л —Б–Њ–µ–і–Є–љ–µ–љ–Є–є(–њ—А–Њ–≥—А–∞–Љ–Љ—Л –і–ї—П —Б–Њ–Ј–і–∞–љ–Є—П –њ—Г–ї–∞ –Ї–Њ–љ–љ–µ–Ї—В–Њ–≤) –њ–Њ–Ј–≤–Њ–ї—П—О—В —Г–Љ–µ–љ—М—И–Є—В—М –љ–∞–Ї–ї–∞–і–љ—Л–µ —А–∞—Б—Е–Њ–і—Л –љ–∞ –±–∞–Ј—Г –і–∞–љ–љ—Л—Е, –Ї–Њ–≥–і–∞ –Њ–≥—А–Њ–Љ–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Д–Є–Ј–Є—З–µ—Б–Ї–Є—Е —Б–Њ–µ–і–Є–љ–µ–љ–Є–є —В—П–љ–µ—В –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М PostgreSQL –≤–љ–Є–Ј. –≠—В–Њ –Њ—Б–Њ–±–µ–љ–љ–Њ –≤–∞–ґ–љ–Њ –љ–∞ Windows, –Ї–Њ–≥–і–∞ —Б–Є—Б—В–µ–Љ–∞ –Њ–≥—А–∞–љ–Є—З–Є–≤–∞–µ—В –±–Њ–ї—М—И–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б–Њ–µ–і–Є–љ–µ–љ–Є–є. –≠—В–Њ —В–∞–Ї–ґ–µ –≤–∞–ґ–љ–Њ –і–ї—П –≤–µ–±-–њ—А–Є–ї–Њ–ґ–µ–љ–Є–є, –≥–і–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б–Њ–µ–і–Є–љ–µ–љ–Є–є –Љ–Њ–ґ–µ—В –±—Л—В—М –Њ—З–µ–љ—М –±–Њ–ї—М—И–Є–Љ.–Я—А–Њ–≥—А–∞–Љ–Љ—Л, –Ї–Њ—В–Њ—А—Л–µ —Б–Њ–Ј–і–∞—О—В –њ—Г–ї—Л —Б–Њ–µ–і–Є–љ–µ–љ–Є–є:
- PgBouncer
- Pgpool
–Ґ–∞–Ї–ґ–µ –љ–µ–Ї–Њ—В–Њ—А—Л–µ –∞–і–Љ–Є–љ–Є—Б—В—А–∞—В–Њ—А—Л PostgreSQL —Б —Г—Б–њ–µ—Е–Њ–Љ –Є—Б–њ–Њ–ї—М–Ј—Г—О—В Memcached –і–ї—П —Г–Љ–µ–љ—М—И–µ–љ–Є—П —А–∞–±–Њ—В—Л –С–Ф –Ј–∞ —Б—З–µ—В –Ї—Н—И–Є—А–Њ–≤–∞–љ–Є—П –і–∞–љ–љ—Л—Е.
2 PgBouncer
–≠—В–Њ –Љ—Г–ї—М—В–Є–њ–ї–µ–Ї—Б–Њ—А —Б–Њ–µ–і–Є–љ–µ–љ–Є–є –і–ї—П PostgreSQL –Њ—В –Ї–Њ–Љ–њ–∞–љ–Є–Є Skype. –°—Г—Й–µ—Б—В–≤—Г—О—В —В—А–Є —А–µ–ґ–Є–Љ–∞ —Г–њ—А–∞–≤–ї–µ–љ–Є—П.- Session Pooling. –Э–∞–Є–±–Њ–ї–µ–µ «–≤–µ–ґ–ї–Є–≤—Л–є» —А–µ–ґ–Є–Љ. –Я—А–Є –љ–∞—З–∞–ї–µ —Б–µ—Б—Б–Є–Є –Ї–ї–Є–µ–љ—В—Г –≤—Л–і–µ–ї—П–µ—В—Б—П —Б–Њ–µ–і–Є–љ–µ–љ–Є–µ —Б —Б–µ—А–≤–µ—А–Њ–Љ; –Њ–љ–Њ –њ—А–Є–њ–Є—Б–∞–љ–Њ –µ–Љ—Г –≤ —В–µ—З–µ–љ–Є–µ –≤—Б–µ–є —Б–µ—Б—Б–Є–Є –Є –≤–Њ–Ј–≤—А–∞—Й–∞–µ—В—Б—П –≤ –њ—Г–ї —В–Њ–ї—М–Ї–Њ –њ–Њ—Б–ї–µ –Њ—В—Б–Њ–µ–і–Є–љ–µ–љ–Є—П –Ї–ї–Є–µ–љ—В–∞.
- Transaction Pooling. –Ъ–ї–Є–µ–љ—В –≤–ї–∞–і–µ–µ—В —Б–Њ–µ–і–Є–љ–µ–љ–Є–µ–Љ —Б –±–∞–Ї–µ–љ–і–Њ–Љ —В–Њ–ї—М–Ї–Њ –≤ —В–µ—З–µ–љ–Є–µ —В—А–∞–љ–Ј–∞–Ї—Ж–Є–Є. –Ъ–Њ–≥–і–∞ PgBouncer –Ј–∞–Љ–µ—З–∞–µ—В, —З—В–Њ —В—А–∞–љ–Ј–∞–Ї—Ж–Є—П –Ј–∞–≤–µ—А—И–Є–ї–∞—Б—М, –Њ–љ –≤–Њ–Ј–≤—А–∞—Й–∞–µ—В —Б–Њ–µ–і–Є–љ–µ–љ–Є–µ –љ–∞–Ј–∞–і –≤ –њ—Г–ї.
- Statement Pooling. –Э–∞–Є–±–Њ–ї–µ–µ –∞–≥—А–µ—Б—Б–Є–≤–љ—Л–є —А–µ–ґ–Є–Љ. –°–Њ–µ–і–Є–љ–µ–љ–Є–µ —Б –±–∞–Ї–µ–љ–і–Њ–Љ –≤–Њ–Ј–≤—А–∞—Й–∞–µ—В—Б—П –љ–∞–Ј–∞–і –≤ –њ—Г–ї —Б—А–∞–Ј—Г –њ–Њ—Б–ї–µ –Ј–∞–≤–µ—А—И–µ–љ–Є—П –Ј–∞–њ—А–Њ—Б–∞. –Ґ—А–∞–љ–Ј–∞–Ї—Ж–Є–Є —Б –љ–µ—Б–Ї–Њ–ї—М–Ї–Є–Љ–Є –Ј–∞–њ—А–Њ—Б–∞–Љ–Є –≤ —Н—В–Њ–Љ —А–µ–ґ–Є–Љ–µ –љ–µ —А–∞–Ј—А–µ—И–µ–љ—Л, —В–∞–Ї –Ї–∞–Ї –Њ–љ–Є –≥–∞—А–∞–љ—В–Є—А–Њ–≤–∞–љ–Њ –±—Г–і—Г—В –Њ—В–Љ–µ–љ–µ–љ—Л. –Ґ–∞–Ї–ґ–µ –љ–µ —А–∞–±–Њ—В–∞—О—В –њ–Њ–і–≥–Њ—В–Њ–≤–ї–µ–љ–љ—Л–µ –≤—Л—А–∞–ґ–µ–љ–Є—П (prepared statements) –≤ —Н—В–Њ–Љ —А–µ–ґ–Є–Љ–µ.
–Ъ –і–Њ—Б—В–Њ–Є–љ—Б—В–≤–∞–Љ PgBouncer –Њ—В–љ–Њ—Б–Є—В—Б—П:
- –Љ–∞–ї–Њ–µ –њ–Њ—В—А–µ–±–ї–µ–љ–Є–µ –њ–∞–Љ—П—В–Є (–Љ–µ–љ–µ–µ 2 –Ъ–С –љ–∞ —Б–Њ–µ–і–Є–љ–µ–љ–Є–µ);
- –Њ—В—Б—Г—В—Б—В–≤–Є–µ –њ—А–Є–≤—П–Ј–Ї–Є –Ї –Њ–і–љ–Њ–Љ—Г —Б–µ—А–≤–µ—А—Г –±–∞–Ј –і–∞–љ–љ—Л—Е;
- —А–µ–Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є—П –љ–∞—Б—В—А–Њ–µ–Ї –±–µ–Ј —А–µ—Б—В–∞—А—В–∞.
–С–∞–Ј–Њ–≤–∞—П —Г—В–Є–ї–Є—В–∞ –Ј–∞–њ—Г—Б–Ї–∞–µ—В—Б—П —В–∞–Ї:
![\begin{lstlisting}[label=lst:pgbouncer1,caption=PgBouncer]
pgbouncer [-d][-R][-v][-u user] <pgbouncer.ini>
\end{lstlisting}](postgresql-img47.png)
–Я—А–Њ—Б—В–Њ–є –њ—А–Є–Љ–µ—А –і–ї—П –Ї–Њ–љ—Д–Є–≥–∞:
![\begin{lstlisting}[label=lst:pgbouncer2,caption=PgBouncer]
[databases]
template1...
... = pgbouncer.log
pidfile = pgbouncer.pid
admin_users = someuser
\end{lstlisting}](postgresql-img48.png)
–Э—Г–ґ–љ–Њ —Б–Њ–Ј–і–∞—В—М —Д–∞–є–ї –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є userlist.txt –њ—А–Є–Љ–µ—А–љ–Њ–≥–Њ —Б–Њ–і–µ—А–ґ–∞–љ–Є—П:''someuser'' ''same_password_as_in_server''
–Р–і–Љ–Є–љ—Б–Ї–Є–є –і–Њ—Б—В—Г–њ –Є–Ј –Ї–Њ–љ—Б–Њ–ї–Є –Ї –±–∞–Ј–µ –і–∞–љ–љ—Л—Е pgbouncer:
![\begin{lstlisting}[label=lst:pgbouncer3,caption=PgBouncer]
psql -h 127.0.0.1 -p 6543 pgbouncer
\end{lstlisting}](postgresql-img49.png)
–Ч–і–µ—Б—М –Љ–Њ–ґ–љ–Њ –њ–Њ–ї—Г—З–Є—В—М —А–∞–Ј–ї–Є—З–љ—Г—О —Б—В–∞—В–Є—Б—В–Є—З–µ—Б–Ї—Г—О –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—О —Б –њ–Њ–Љ–Њ—Й—М—О –Ї–Њ–Љ–∞–љ–і—Л SHOW.
3 PgPool-II vs PgBouncer
–Т—Б–µ –Њ—З–µ–љ—М –њ—А–Њ—Б—В–Њ. PgBouncer –љ–∞–Љ–љ–Њ–≥–Њ –ї—Г—З—И–µ —А–∞–±–Њ—В–∞–µ—В —Б –њ—Г–ї–∞–Љ–Є —Б–Њ–µ–і–Є–љ–µ–љ–Є–є, —З–µ–Љ PgPool-II. –Х—Б–ї–Є –≤–∞–Љ –љ–µ –љ—Г–ґ–љ—Л –Њ—Б—В–∞–ї—М–љ—Л–µ —Д–Є—З–Є, –Ї–Њ—В–Њ—А—Л–Љ–Є –≤–ї–∞–і–µ–µ—В PgPool-II (–≤–µ–і—М –њ—Г–ї—Л –Ї–Њ–љ–љ–µ–Ї—В–Њ–≤ —Н—В–Њ –Љ–µ–ї–Њ—З–Є –Ї –µ–≥–Њ —Д—Г–љ–Ї—Ж–Є–Њ–љ–∞–ї—Г), —В–Њ –Ї–Њ–љ–µ—З–љ–Њ –ї—Г—З—И–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М PgBouncer.
- PgBouncer –њ–Њ—В—А–µ–±–ї—П–µ—В –Љ–µ–љ—М—И–µ –њ–∞–Љ—П—В–Є, —З–µ–Љ PgPool-II
- —Г PgBouncer –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ –љ–∞—Б—В—А–Њ–Є—В—М –Њ—З–µ—А–µ–і—М —Б–Њ–µ–і–Є–љ–µ–љ–Є–є
- –≤ PgBouncer –Љ–Њ–ґ–љ–Њ –љ–∞—Б—В—А–∞–Є–≤–∞—В—М –њ—Б–µ–≤–і–Њ –±–∞–Ј—Л –і–∞–љ–љ—Л—Е (–љ–∞ —Б–µ—А–≤–µ—А–µ –Њ–љ–Є –Љ–Њ–≥—Г—В –љ–∞–Ј—Л–≤–∞—В—Б—П –њ–Њ –і—А—Г–≥–Њ–Љ—Г)
–•–Њ—В—П –љ–µ–Ї–Њ—В–Њ—А—Л–µ –Є—Б–њ–Њ–ї—М–Ј—Г—О—В PgBouncer –Є PgPool-II —Б–Њ–≤–Љ–µ—Б—В–љ–Њ.
7 –С—Н–Ї–∞–њ –Є –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ PostgreSQL

1 –Т–≤–µ–і–µ–љ–Є–µ
–Ы—О–±–Њ–є —Е–Њ—А–Њ—И–Є–є —Б–Є—Б–∞–і–Љ–Є–љ –Ј–љ–∞–µ—В -- –±—Н–Ї–∞–њ—Л –љ—Г–ґ–љ—Л –≤—Б–µ–≥–і–∞. –Э–∞ —Б–Ї–Њ–ї—М–Ї–Њ –±—Л –љ–∞–і–µ–ґ–љ–∞ –љ–µ –Ї–∞–Ј–∞–ї–∞—Б—М –Т–∞—И–∞ —Б–Є—Б—В–µ–Љ–∞, –≤—Б–µ–≥–і–∞ –Љ–Њ–ґ–µ—В –њ—А–Њ–Є–Ј–Њ–є—В–Є —Б–ї—Г—З–∞–є, –Ї–Њ—В–Њ—А—Л–є –±—Л–ї –љ–µ —Г—З—В–µ–љ, –Є –Є–Ј-–Ј–∞ –Ї–Њ—В–Њ—А–Њ–≥–Њ –Љ–Њ–≥—Г—В –±—Л—В—М –њ–Њ—В–µ—А—П–љ—Л –і–∞–љ–љ—Л–µ.–Ґ–Њ–ґ–µ —Б–∞–Љ–Њ–µ –Ї–∞—Б–∞–µ—В—Б—П –Є PostgreSQL –±–∞–Ј –і–∞–љ–љ—Л—Е. –С–µ–Ї–∞–њ—Л –і–Њ–ї–ґ–љ—Л –±—Л—В—М! –Я–Њ—Б—Л–њ–∞–≤—И–Є–є—Б—П –≤–Є–љ—З–µ—Б—В–µ—А –љ–∞ —Б–µ—А–≤–µ—А–µ, –Њ—И–Є–±–Ї–∞ –≤ —Д–∞–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ–µ, –Њ—И–Є–±–Ї–∞ –≤ –і—А—Г–≥–Њ–є –њ—А–Њ–≥—А–∞–Љ–Љ–µ, –Ї–Њ—В–Њ—А–∞—П –њ–µ—А–µ—В–µ—А–ї–∞ –≤–µ—Б—М –Ї–∞—В–∞–ї–Њ–≥ PostgreSQL –Є –Љ–љ–Њ–≥–Њ–µ –і—А—Г–≥–Њ–µ –њ—А–Є–≤–µ–і–µ—В —В–Њ–ї—М–Ї–Њ –Ї –њ–ї–∞—З–µ–≤–љ–Њ–Љ—Г —А–µ–Ј—Г–ї—М—В–∞—В—Г. –Ш –і–∞–ґ–µ –µ—Б–ї–Є —Г –Т–∞—Б —А–µ–њ–ї–Є–Ї–∞—Ж–Є—П —Б –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ–Љ —Б–ї–µ–є–≤–Њ–≤, —Н—В–Њ –љ–µ –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ —Б–Є—Б—В–µ–Љ–∞ –≤ –±–µ–Ј–Њ–њ–∞—Б–љ–Њ—Б—В–Є -- –љ–µ–≤–µ—А–љ—Л–є –Ј–∞–њ—А–Њ—Б –љ–∞ –Љ–∞—Б—В–µ—А (DELETE, DROP), –Є —Г —Б–ї–µ–є–≤–Њ–≤ —В–∞–Ї–∞—П –ґ–µ –њ–Њ—А—Ж–Є—П –і–∞–љ–љ—Л—Е (—В–Њ—З–љ–µ–µ –Є—Е –Њ—В—Б—Г—В—Б—В–≤–Є–µ).
–°—Г—Й–µ—Б—В–≤—Г—О—В —В—А–Є –њ—А–Є–љ—Ж–Є–њ–Є–∞–ї—М–љ–Њ —А–∞–Ј–ї–Є—З–љ—Л—Е –њ–Њ–і—Е–Њ–і–∞ –Ї —А–µ–Ј–µ—А–≤–љ–Њ–Љ—Г –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є—О –і–∞–љ–љ—Л—Е PostgreSQL:
- SQL –±—Н–Ї–∞–њ;
- –С–µ–Ї–∞–њ —Г—А–Њ–≤–љ—П —Д–∞–є–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л;
- –Э–µ–њ—А–µ—А—Л–≤–љ–Њ–µ —А–µ–Ј–µ—А–≤–љ–Њ–µ –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є–µ;
2 SQL –±—Н–Ї–∞–њ
–Ш–і–µ—П —Н—В–Њ–≥–Њ –њ–Њ–і—Е–Њ–і–∞ –≤ —Б–Њ–Ј–і–∞–љ–Є–Є —В–µ–Ї—Б—В–Њ–≤–Њ–≥–Њ —Д–∞–є–ї–∞ —Б –Ї–Њ–Љ–∞–љ–і–∞–Љ–Є SQL. –Ґ–∞–Ї–Њ–є —Д–∞–є–ї –Љ–Њ–ґ–љ–Њ –њ–µ—А–µ–і–∞—В—М –Њ–±—А–∞—В–љ–Њ –љ–∞ —Б–µ—А–≤–µ—А –Є –≤–Њ—Б—Б–Њ–Ј–і–∞—В—М –±–∞–Ј—Г –і–∞–љ–љ—Л—Е –≤ —В–Њ–Љ –ґ–µ —Б–Њ—Б—В–Њ—П–љ–Є–Є, –≤ –Ї–Њ—В–Њ—А–Њ–Љ –Њ–љ–∞ –±—Л–ї–∞ –≤–Њ –≤—А–µ–Љ—П –±—Н–Ї–∞–њ–∞. –£ PostgreSQL –і–ї—П —Н—В–Њ–≥–Њ –µ—Б—В—М —Б–њ–µ—Ж–Є–∞–ї—М–љ–∞—П —Г—В–Є–ї–Є—В–∞ -- pg_dump. –Я—А–Є–Љ–µ—А –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П pg_dump:![\begin{lstlisting}[label=lst:backups1,caption=–°–Њ–Ј–і–∞–µ–Љ –±—Н–Ї–∞–њ —Б –њ–Њ–Љ–Њ—Й—М—О pg\_dump]
pg_dump dbname > outfile
\end{lstlisting}](postgresql-img51.png)
–Ф–ї—П –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є—П —В–∞–Ї–Њ–≥–Њ –±—Н–Ї–∞–њ–∞ –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –≤—Л–њ–Њ–ї–љ–Є—В—М:
![\begin{lstlisting}[label=lst:backups2,caption=–Т–Њ—Б—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ–Љ –±—Н–Ї–∞–њ]
psql dbname < infile
\end{lstlisting}](postgresql-img52.png)
–Я—А–Є —Н—В–Њ–Љ –±–∞–Ј—Г –і–∞–љ–љ—Л—Е «dbname» –њ–Њ—В—А–µ–±—Г–µ—В—Б—П —Б–Њ–Ј–і–∞—В—М –њ–µ—А–µ–і –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ–Љ. –Ґ–∞–Ї–ґ–µ –њ–Њ—В—А–µ–±—Г–µ—В—Б—П —Б–Њ–Ј–і–∞—В—М –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є,
–Ї–Њ—В–Њ—А—Л–µ –Є–Љ–µ—О—В –і–Њ—Б—В—Г–њ –Ї –і–∞–љ–љ—Л–Љ, –Ї–Њ—В–Њ—А—Л–µ –≤–Њ—Б—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—О—В—Б—П (—Н—В–Њ –Љ–Њ–ґ–љ–Њ –Є –љ–µ –і–µ–ї–∞—В—М, –љ–Њ —В–Њ–≥–і–∞ –њ—А–Њ—Б—В–Њ –≤ –≤—Л–≤–Њ–і–µ –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є—П –±—Г–і—Г—В –Њ—И–Є–±–Ї–Є).
–Х—Б–ї–Є –љ–∞–Љ —В—А–µ–±—Г–µ—В—Б—П, —З—В–Њ–±—Л –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ –њ—А–µ–Ї—А–∞—В–Є–ї–Њ—Б—М –њ—А–Є –≤–Њ–Ј–љ–Є–Ї–љ–Њ–≤–µ–љ–Є–Є –Њ—И–Є–±–Ї–Є, —В–Њ–≥–і–∞ –њ–Њ—В—А–µ–±—Г–µ—В—Б—П –≤–Њ—Б—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М –±—Н–Ї–∞–њ —В–∞–Ї–Є–Љ —Б–њ–Њ—Б–Њ–±–Њ–Љ:
![\begin{lstlisting}[label=lst:backups3,caption=–Т–Њ—Б—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ–Љ –±—Н–Ї–∞–њ]
psql --set ON_ERROR_STOP=on dbname < infile
\end{lstlisting}](postgresql-img53.png)
–Ґ–∞–Ї–ґ–µ, –Љ–Њ–ґ–љ–Њ –і–µ–ї–∞—В—М –±—Н–Ї–∞–њ –Є —Б—А–∞–Ј—Г –≤–Њ—Б—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М –µ–≥–Њ –љ–∞ –і—А—Г–≥—Г—О –±–∞–Ј—Г:
![\begin{lstlisting}[label=lst:backups4,caption=–С–µ–Ї–∞–њ –≤ –і—А—Г–≥—Г—О –С–Ф]
pg_dump -h host1 dbname \vert psql -h host2 dbname
\end{lstlisting}](postgresql-img54.png)
–Я–Њ—Б–ї–µ –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є—П –±—Н–Ї–∞–њ–∞ –ґ–µ–ї–∞—В–µ–ї—М–љ–Њ –Ј–∞–њ—Г—Б—В–Є—В—М «ANALYZE», —З—В–Њ–±—Л –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А –Ј–∞–њ—А–Њ—Б–Њ–≤ –Њ–±–љ–Њ–≤–Є–ї —Б—В–∞—В–Є—Б—В–Є–Ї—Г.
–Р —З—В–Њ, –µ—Б–ї–Є –љ—Г–ґ–љ–Њ —Б–і–µ–ї–∞—В—М –±—Н–Ї–∞–њ –љ–µ –Њ–і–љ–Њ–є –±–∞–Ј—Л –і–∞–љ–љ—Л—Е, –∞ –≤—Б–µ—Е, –і–∞ –Є –µ—Й–µ –њ–Њ–ї—Г—З–Є—В—М –≤ –±—Н–Ї–∞–њ–µ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—О –њ—А–Њ —А–Њ–ї–Є –Є —В–∞–±–ї–Є—Ж—Л?
–Т —В–∞–Ї–Њ–Љ —Б–ї—Г—З–∞–µ —Г PostgreSQL –µ—Б—В—М —Г—В–Є–ї–Є—В–∞ pg_dumpall. pg_dumpall –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –і–ї—П —Б–Њ–Ј–і–∞–љ–Є—П –±—Н–Ї–∞–њ–∞ –і–∞–љ–љ—Л—Е –≤—Б–µ–≥–Њ –Ї–ї–∞—Б—В–µ—А–∞ PostgreSQL:
![\begin{lstlisting}[label=lst:backups5,caption=–С–µ–Ї–∞–њ –Ї–ї–∞—Б—В–µ—А–∞ PostgreSQL]
pg_dumpall > outfile
\end{lstlisting}](postgresql-img55.png)
–Ф–ї—П –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є—П —В–∞–Ї–Њ–≥–Њ –±—Н–Ї–∞–њ–∞ –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –≤—Л–њ–Њ–ї–љ–Є—В—М –Њ—В —Б—Г–њ–µ—А–њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П:
![\begin{lstlisting}[label=lst:backups6,caption=–Т–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є—П –±—Н–Ї–∞–њ–∞ PostgreSQL]
psql -f infile postgres
\end{lstlisting}](postgresql-img56.png)
1 SQL –±—Н–Ї–∞–њ –±–Њ–ї—М—И–Є—Е –±–∞–Ј –і–∞–љ–љ—Л—Е
–Э–µ–Ї–Њ—В–Њ—А—Л–µ –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ—Л–µ —Б–Є—Б—В–µ–Љ—Л –Є–Љ–µ—О—В –Њ–≥—А–∞–љ–Є—З–µ–љ–Є—П –љ–∞ –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ—Л–є —А–∞–Ј–Љ–µ—А —Д–∞–є–ї–∞, —З—В–Њ –Љ–Њ–ґ–µ—В –≤—Л–Ј—Л–≤–∞—О—В—М –њ—А–Њ–±–ї–µ–Љ—Л –њ—А–Є —Б–Њ–Ј–і–∞–љ–Є–Є –±–Њ–ї—М—И–Є—Е –±—Н–Ї–∞–њ–Њ–≤ —З–µ—А–µ–Ј pg_dump. –Ъ —Б—З–∞—Б—В—М—О, pg_dump –Љ–Њ–ґ–µ—В–µ –±—Н–Ї–∞–њ–Є—В—М –≤ —Б—В–∞–љ–і–∞—А—В–љ—Л–є –≤—Л–≤–Њ–і. –Ґ–∞–Ї —З—В–Њ –Љ–Њ–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —Б—В–∞–љ–і–∞—А—В–љ—Л–µ –Є–љ—Б—В—А—Г–Љ–µ–љ—В—Л Unix, —З—В–Њ–±—Л –Њ–±–Њ–є—В–Є —Н—В—Г –њ—А–Њ–±–ї–µ–Љ—Г. –Х—Б—В—М –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –≤–Њ–Ј–Љ–Њ–ґ–љ—Л—Е —Б–њ–Њ—Б–Њ–±–Њ–≤:- –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —Б–ґ–∞—В–Є–µ –і–ї—П –±—Н–Ї–∞–њ–∞.
–Ь–Њ–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –њ—А–Њ–≥—А–∞–Љ–Љ—Г —Б–ґ–∞—В–Є—П –і–∞–љ–љ—Л—Е, –љ–∞–њ—А–Є–Љ–µ—А GZIP:
![\begin{lstlisting}[label=lst:backups7,caption=–°–ґ–∞—В–Є–µ –±—Н–Ї–∞–њ–∞ PostgreSQL]
pg_dump dbname \vert gzip > filename.gz
\end{lstlisting}](postgresql-img57.png)
–Т–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ:
![\begin{lstlisting}[label=lst:backups8,caption=–Т–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ –±—Н–Ї–∞–њ–∞ PostgreSQL]
gunzip -c filename.gz \vert psql dbname
\end{lstlisting}](postgresql-img58.png)
–Є–ї–Є
![\begin{lstlisting}[label=lst:backups9,caption=–Т–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ –±—Н–Ї–∞–њ–∞ PostgreSQL]
cat filename.gz \vert gunzip \vert psql dbname
\end{lstlisting}](postgresql-img59.png)
- –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Ї–Њ–Љ–∞–љ–і—Г split.
–Ъ–Њ–Љ–∞–љ–і–∞ split –њ–Њ–Ј–≤–Њ–ї—П–µ—В —А–∞–Ј–і–µ–ї–Є—В—М –≤—Л–≤–Њ–і –≤ —Д–∞–є–ї—Л –Љ–µ–љ—М—И–µ–≥–Њ —А–∞–Ј–Љ–µ—А–∞, –Ї–Њ—В–Њ—А—Л–µ —П–≤–ї—П—О—В—Б—П –њ–Њ–і—Е–Њ–і—П—Й–Є–Љ–Є –њ–Њ —А–∞–Ј–Љ–µ—А—Г –і–ї—П —Д–∞–є–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л. –Э–∞–њ—А–Є–Љ–µ—А, –±—Н–Ї–∞–њ –і–µ–ї–Є—В—Б—П –љ–∞ –Ї—Г—Б–Ї–Є –њ–Њ 1 –Љ–µ–≥–∞–±–∞–є—В—Г:
![\begin{lstlisting}[label=lst:backups10,caption=–°–Њ–Ј–і–∞–љ–Є–µ –±—Н–Ї–∞–њ–∞ PostgreSQL]
pg_dump dbname \vert split -b 1m - filename
\end{lstlisting}](postgresql-img60.png)
–Т–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ:
![\begin{lstlisting}[label=lst:backups11,caption=–Т–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ –±—Н–Ї–∞–њ–∞ PostgreSQL]
cat filename* \vert psql dbname
\end{lstlisting}](postgresql-img61.png)
- –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М—Б–Ї–Є–є —Д–Њ—А–Љ–∞—В –і–∞–Љ–њ–∞ pg_dump
PostgreSQL –њ–Њ—Б—В—А–Њ–µ–љ –љ–∞ —Б–Є—Б—В–µ–Љ–µ —Б –±–Є–±–ї–Є–Њ—В–µ–Ї–Њ–є —Б–ґ–∞—В–Є—П Zlib, –њ–Њ—Н—В–Њ–Љ—Г –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М—Б–Ї–Є–є —Д–Њ—А–Љ–∞—В –±—Н–Ї–∞–њ–∞ –±—Г–і–µ—В –≤ —Б–ґ–∞—В–Њ–Љ –≤–Є–і–µ. –≠—В–Њ –њ–Њ—Е–Њ–ґ–µ –љ–∞ –Љ–µ—В–Њ–і —Б –Є–Љ–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ GZIP, –љ–Њ –Њ–љ –Є–Љ–µ–µ—В –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ–Њ–µ –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–Њ -- —В–∞–±–ї–Є—Ж—Л –Љ–Њ–≥—Г—В –±—Л—В—М –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ—Л –≤—Л–±–Њ—А–Њ—З–љ–Њ:
![\begin{lstlisting}[label=lst:backups12,caption=–°–Њ–Ј–і–∞–љ–Є–µ –±—Н–Ї–∞–њ–∞ PostgreSQL]
pg_dump -Fc dbname > filename
\end{lstlisting}](postgresql-img62.png)
–І–µ—А–µ–Ј psql —В–∞–Ї–Њ–є –±—Н–Ї–∞–њ –љ–µ –≤–Њ—Б—Б—В–∞–љ–Њ–≤–Є—В—М, –љ–Њ –і–ї—П —Н—В–Њ–≥–Њ –µ—Б—В—М —Г—В–Є–ї–Є—В–∞ pg_restore:
![\begin{lstlisting}[label=lst:backups13,caption=–Т–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ –±—Н–Ї–∞–њ–∞ PostgreSQL]
pg_restore -d dbname filename
\end{lstlisting}](postgresql-img63.png)
–Я—А–Є —Б–ї–Є—И–Ї–Њ–Љ –±–Њ–ї—М—И–Њ–є –±–∞–Ј–µ –і–∞–љ–љ—Л—Е, –≤–∞—А–Є–∞–љ—В —Б –Ї–Њ–Љ–∞–љ–і–Њ–є split –љ—Г–ґ–љ–Њ –Ї–Њ–Љ–±–Є–љ–Є—А–Њ–≤–∞—В—М —Б —Б–ґ–∞—В–Є–µ–Љ –і–∞–љ–љ—Л—Е.
3 –С–µ–Ї–∞–њ —Г—А–Њ–≤–љ—П —Д–∞–є–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л
–Р–ї—М—В–µ—А–љ–∞—В–Є–≤–љ—Л–є –Љ–µ—В–Њ–і —А–µ–Ј–µ—А–≤–љ–Њ–≥–Њ –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є—П –Ј–∞–Ї–ї—О—З–∞–µ—В—Б—П –≤ –љ–µ–њ–Њ—Б—А–µ–і—Б—В–≤–µ–љ–љ–Њ–Љ –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є–Є —Д–∞–є–ї–Њ–≤, –Ї–Њ—В–Њ—А—Л–µ PostgreSQL –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В –і–ї—П —Е—А–∞–љ–µ–љ–Є—П –і–∞–љ–љ—Л—Е –≤ –±–∞–Ј–µ –і–∞–љ–љ—Л—Е. –Э–∞–њ—А–Є–Љ–µ—А:![\begin{lstlisting}[label=lst:backups14,caption=–С—Н–Ї–∞–њ PostgreSQL —Д–∞–є–ї–Њ–≤]
tar -cf backup.tar /usr/local/pgsql/data
\end{lstlisting}](postgresql-img64.png)
–Э–Њ –µ—Б—В—М –і–≤–∞ –Њ–≥—А–∞–љ–Є—З–µ–љ–Є—П, –Ї–Њ—В–Њ—А—Л–µ –і–µ–ї–∞–µ—В —Н—В–Њ—В –Љ–µ—В–Њ–і –љ–µ—Ж–µ–ї–µ—Б–Њ–Њ–±—А–∞–Ј–љ—Л–Љ, –Є–ї–Є, –њ–Њ –Ї—А–∞–є–љ–µ–є –Љ–µ—А–µ, —Г—Б—В—Г–њ–∞—О—Й–Є–Љ SQL –±—Н–Ї–∞–њ—Г:
- PostgreSQL –±–∞–Ј–∞ –і–∞–љ–љ—Л—Е –і–Њ–ї–ґ–љ–∞ –±—Л—В—М –Њ—Б—В–∞–љ–Њ–≤–ї–µ–љ–љ–∞, –і–ї—П —В–Њ–≥–Њ, —З—В–Њ–±—Л –њ–Њ–ї—Г—З–Є—В—М –∞–Ї—В—Г–∞–ї—М–љ—Л–є –±—Н–Ї–∞–њ (PostgreSQL –і–µ—А–ґ–Є—В –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ –Њ–±—М–µ–Ї—В–Њ–≤ –≤ –њ–∞–Љ—П—В–Є, –±—Г—Д–µ—А–Є–Ј–∞—Ж–Є—П —Д–∞–є–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л). –Ш–Ј–ї–Є—И–љ–µ –≥–Њ–≤–Њ—А–Є—В—М, —З—В–Њ –≤–Њ –≤—А–µ–Љ—П –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є—П —В–∞–Ї–Њ–≥–Њ –±—Н–Ї–∞–њ–∞ –њ–Њ—В—А–µ–±—Г–µ—В—Б—П —В–∞–Ї–ґ–µ –Њ—Б—В–∞–љ–Њ–≤–Є—В—М PostgreSQL.
- –Э–µ –њ–Њ–ї—Г—З–Є—В—Б—П –≤–Њ—Б—В–∞–љ–Њ–≤–Є—В—М —В–Њ–ї—М–Ї–Њ –Њ–њ—А–µ–і–µ–ї–µ–љ–љ—Л–µ –і–∞–љ–љ—Л–µ —Б —В–∞–Ї–Њ–≥–Њ –±—Н–Ї–∞–њ–∞.
–Ъ–∞–Ї –∞–ї—М—В–µ—А–љ–∞—В–Є–≤–∞, –Љ–Њ–ґ–љ–Њ –і–µ–ї–∞—В—М —Б–љ–Є–Љ–Ї–Є (snapshot) —Д–∞–є–ї–Њ–≤ —Б–Є—Б—В–µ–Љ—Л (–њ–∞–њ–Ї–Є —Б —Д–∞–є–ї–∞–Љ–Є PostgreSQL). –Т —В–∞–Ї–Њ–Љ —Б–ї—Г—З–∞–µ –Њ—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—В—М PostgreSQL –љ–µ —В—А–µ–±—Г–µ—В—Б—П. –Ю–і–љ–∞–Ї–Њ, —А–µ–Ј–µ—А–≤–љ–∞—П –Ї–Њ–њ–Є—П, —Б–Њ–Ј–і–∞–љ–љ–∞—П —В–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, —Б–Њ—Е—А–∞–љ—П–µ—В —Д–∞–є–ї—Л –±–∞–Ј—Л –і–∞–љ–љ—Л—Е –≤ —Б–Њ—Б—В–Њ—П–љ–Є–Є, –Ї–∞–Ї –µ—Б–ї–Є –±—Л —Б–µ—А–≤–µ—А –±–∞–Ј—Л –і–∞–љ–љ—Л—Е –±—Л–ї –љ–µ–њ—А–∞–≤–Є–ї—М–љ–Њ –Њ—Б—В–∞–љ–Њ–≤–ї–µ–љ. –Я–Њ—Н—В–Њ–Љ—Г –њ—А–Є –Ј–∞–њ—Г—Б–Ї–µ PostgreSQL –Є–Ј —А–µ–Ј–µ—А–≤–љ–Њ–є –Ї–Њ–њ–Є–Є, –Њ–љ –±—Г–і–µ—В –і—Г–Љ–∞—В—М, —З—В–Њ –њ—А–µ–і—Л–і—Г—Й–Є–є —Н–Ї–Ј–µ–Љ–њ–ї—П—А —Б–µ—А–≤–µ—А–∞ –≤—Л—И–µ–ї –Є–Ј —Б—В—А–Њ—П –Є –њ–Њ–≤—В–Њ—А–Є—В –ґ—Г—А–љ–∞–ї–∞ WAL. –≠—В–Њ –љ–µ –њ—А–Њ–±–ї–µ–Љ–∞, –њ—А–Њ—Б—В–Њ –љ–∞–і–Њ –Ј–љ–∞—В—М –њ—А–Њ —Н—В–Њ (–Є –љ–µ –Ј–∞–±—Л—В—М –≤–Ї–ї—О—З–Є—В—М WAL —Д–∞–є–ї—Л –≤ —А–µ–Ј–µ—А–≤–љ—Г—О –Ї–Њ–њ–Є—О). –Ґ–∞–Ї–ґ–µ, –µ—Б–ї–Є —Д–∞–є–ї–Њ–≤–∞—П —Б–Є—Б—В–µ–Љ–∞ PostgreSQL —А–∞—Б–њ—А–µ–і–µ–ї–µ–љ–∞ –њ–Њ —А–∞–Ј–љ—Л–Љ —Д–∞–є–ї–Њ–≤—Л–Љ —Б–Є—Б—В–µ–Љ–∞, —В–Њ —В–∞–Ї–Њ–є –Љ–µ—В–Њ–і –±—Н–Ї–∞–њ–∞ –±—Г–і–µ—В –Њ—З–µ–љ—М –љ–µ –љ–∞–і–µ–ґ–љ—Л–Љ -- —Б–љ–Є–Љ–Ї–Є —Д–∞–є–ї–Њ–≤ —Б–Є—Б—В–µ–Љ—Л –і–Њ–ї–ґ–љ—Л –±—Л—В—М —Б–і–µ–ї–∞–љ—Л –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ–Њ(!!!). –Я–Њ—З–Є—В–∞–є—В–µ –і–Њ–Ї—Г–Љ–µ–љ—В–∞—Ж–Є—О —Д–∞–є–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л –Њ—З–µ–љ—М –≤–љ–Є–Љ–∞—В–µ–ї—М–љ–Њ, –њ—А–µ–ґ–і–µ —З–µ–Љ –і–Њ–≤–µ—А—П—В—М —Б–љ–Є–Љ–Ї–∞–Љ —Д–∞–є–ї–Њ–≤ —Б–Є—Б—В–µ–Љ—Л –≤ —В–∞–Ї–Є—Е —Б–Є—В—Г–∞—Ж–Є—П—Е.
–Ґ–∞–Ї–ґ–µ –≤–Њ–Ј–Љ–Њ–ґ–µ–љ –≤–∞—А–Є–∞–љ—В —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ rsync. –Я–µ—А–≤—Л–Љ –Ј–∞–њ—Г—Б–Ї–Њ–Љ rsync –Љ—Л –Ї–Њ–њ–Є—А—Г–µ–Љ –Њ—Б–љ–Њ–≤–љ—Л–µ —Д–∞–є–ї—Л —Б –і–Є—А–µ–Ї—В–Њ—А–Є–Є PostgreSQL (PostgreSQL –њ—А–Є —Н—В–Њ–Љ –њ—А–Њ–і–Њ–ї–ґ–∞–µ—В —А–∞–±–Њ—В—Г). –Я–Њ—Б–ї–µ —Н—В–Њ–≥–Њ –Љ—Л –Њ—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ–Љ PostgreSQL –Є –Ј–∞–њ—Г—Б–Ї–∞–µ–Љ –њ–Њ–≤—В–Њ—А–љ–Њ rsync. –Т—В–Њ—А–Њ–є –Ј–∞–њ—Г—Б–Ї rsync –њ—А–Њ–є–і–µ—В –≥–Њ—А–∞–Ј–і–Њ –±—Л—Б—В—А–µ–µ, —З–µ–Љ –њ–µ—А–≤—Л–є, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –±—Г–і–µ—В –њ–µ—А–µ–і–∞–≤–∞—В—М –Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–Њ –љ–µ–±–Њ–ї—М—И–Њ–є —А–∞–Ј–Љ–µ—А –і–∞–љ–љ—Л—Е, –Є –Ї–Њ–љ–µ—З–љ—Л–є —А–µ–Ј—Г–ї—М—В–∞—В –±—Г–і–µ—В —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Њ–≤–∞—В—М –Њ—Б—В–∞–љ–Њ–≤–ї–µ–љ–љ–Њ–є –°–£–С–Ф. –≠—В–Њ—В –Љ–µ—В–Њ–і –њ–Њ–Ј–≤–Њ–ї—П–µ—В –і–µ–ї–∞—В—М –±–µ–Ї–∞–њ —Г—А–Њ–≤–љ—П —Д–∞–є–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л —Б –Љ–Є–љ–Є–Љ–∞–ї—М–љ—Л–Љ –≤—А–µ–Љ–µ–љ–µ–Љ –њ—А–Њ—Б—В–Њ—П.
4 –Э–µ–њ—А–µ—А—Л–≤–љ–Њ–µ —А–µ–Ј–µ—А–≤–љ–Њ–µ –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є–µ
PostgreSQL –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В —Г–њ—А–µ–ґ–і–∞—О—И–Є—О –Ј–∞–њ–Є—Б—М –ї–Њ–≥–Њ–≤ (Write Ahead Log, WAL) –≤ pg_xlog –і–Є—А–µ–Ї—В–Њ—А–Є—О, –Ї–Њ—В–Њ—А–∞—П –љ–∞—Е–Њ–і–Є—В—Б—П –≤ –і–Є—А–µ–Ї—В–Њ—А–Є–Є –і–∞–љ–љ—Л—Е –°–£–С–Ф. –Т –ї–Њ–≥–Є –њ–Є—И—Г—В—Б—П –≤—Б–µ –Є–Ј–Љ–µ–љ–µ–љ–Є—П —Б–і–µ–ї–∞–љ—Л–µ —Б –і–∞–љ–љ—Л–Љ–Є –≤ –°–£–С–Ф. –≠—В–Њ—В –ґ—Г—А–љ–∞–ї —Б—Г—Й–µ—Б—В–≤—Г–µ—В –њ—А–µ–ґ–і–µ –≤—Б–µ–≥–Њ –і–ї—П –±–µ–Ј–Њ–њ–∞—Б–љ–Њ—Б—В–Є –≤–Њ –≤—А–µ–Љ—П –Ї—А–∞—Е–∞ PostgreSQL: –µ—Б–ї–Є –њ—А–Њ–Є—Б—Е–Њ–і—П—В —Б–±–Њ–Є –≤ —Б–Є—Б—В–µ–Љ–µ, –±–∞–Ј—Л –і–∞–љ–љ—Л—Е –Љ–Њ–≥—Г—В –±—Л—В—М –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ—Л —Б –њ–Њ–Љ–Њ—Й—М—О «–њ–µ—А–µ–Ј–∞–њ—Г—Б–Ї–∞» —Н—В–Њ–≥–Њ –ґ—Г—А–љ–∞–ї–∞. –Ґ–µ–Љ –љ–µ –Љ–µ–љ–µ–µ, —Б—Г—Й–µ—Б—В–≤–Њ–≤–∞–љ–Є–µ –ґ—Г—А–љ–∞–ї–∞ –і–µ–ї–∞–µ—В –≤–Њ–Ј–Љ–Њ–ґ–љ—Л–Љ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —В—А–µ—В—М—О —Б—В—А–∞—В–µ–≥–Є–Є –і–ї—П —А–µ–Ј–µ—А–≤–љ–Њ–≥–Њ –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є—П –±–∞–Ј –і–∞–љ–љ—Л—Е: –Љ—Л –Љ–Њ–ґ–µ–Љ –Њ–±—К–µ–і–Є–љ–Є—В—М –±–µ–Ї–∞–њ —Г—А–Њ–≤–љ—П —Д–∞–є–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л —Б —А–µ–Ј–µ—А–≤–љ–Њ–є –Ї–Њ–њ–Є–µ–є WAL —Д–∞–є–ї–Њ–≤. –Х—Б–ї–Є —В—А–µ–±—Г–µ—В—Б—П –≤–Њ—Б—Б—В–∞–љ–Њ–≤–Є—В—М —В–∞–Ї–Њ–є –±—Н–Ї–∞–њ, —В–Њ –Љ—Л –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–Є–≤–∞–µ–Љ —Д–∞–є–ї—Л —А–µ–Ј–µ—А–≤–љ–Њ–є –Ї–Њ–њ–Є–Є —Д–∞–є–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л, –∞ –Ј–∞—В–µ–Љ «–њ–µ—А–µ–Ј–∞–њ—Г—Б–Ї–∞–µ–Љ» —Б —А–µ–Ј–µ—А–≤–љ–Њ–є –Ї–Њ–њ–Є–Є —Д–∞–є–ї–Њ–≤ WAL –і–ї—П –њ—А–Є–≤–µ–і–µ–љ–Є—П —Б–Є—Б—В–µ–Љ—Л –Ї –∞–Ї—В—Г–∞–ї—М–љ–Њ–Љ—Г —Б–Њ—Б—В–Њ—П–љ–Є—О. –≠—В–Њ—В –њ–Њ–і—Е–Њ–і —П–≤–ї—П–µ—В—Б—П –±–Њ–ї–µ–µ —Б–ї–Њ–ґ–љ—Л–Љ –і–ї—П –∞–і–Љ–Є–љ–Є—Б—В—А–Є—А–Њ–≤–∞–љ–Є—П, —З–µ–Љ –ї—О–±–Њ–є –Є–Ј –њ—А–µ–і—Л–і—Г—Й–Є—Е –њ–Њ–і—Е–Њ–і–Њ–≤, –љ–Њ –Њ–љ –Є–Љ–µ–µ—В –љ–µ–Ї–Њ—В–Њ—А—Л–µ –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–∞:- –Э–µ –љ—Г–ґ–љ–Њ —Б–Њ–≥–ї–∞—Б–Њ–≤—Л–≤–∞—В—М —Д–∞–є–ї—Л —А–µ–Ј–µ—А–≤–љ–Њ–є –Ї–Њ–њ–Є–Є —Б–Є—Б—В–µ–Љ—Л. –Ы—О–±–∞—П –≤–љ—Г—В—А–µ–љ–љ—П—П –њ—А–Њ—В–Є–≤–Њ—А–µ—З–Є–≤–Њ—Б—В—М –≤ —А–µ–Ј–µ—А–≤–љ–Њ–є –Ї–Њ–њ–Є–Є –±—Г–і–µ—В –Є—Б–њ—А–∞–≤–ї–µ–љ–∞ –њ—Г—В–µ–Љ –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є—П –ґ—Г—А–љ–∞–ї–∞ (–љ–µ –Њ—В–ї–Є—З–∞–µ—В—Б—П –Њ—В —В–Њ–≥–Њ, —З—В–Њ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –≤–Њ –≤—А–µ–Љ—П –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є—П –њ–Њ—Б–ї–µ —Б–±–Њ—П).
- –Т–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ —Б–Њ—Б—В–Њ—П–љ–Є—П —Б–µ—А–≤–µ—А–∞ –і–ї—П –Њ–њ—А–µ–і–µ–ї–µ–љ–љ–Њ–≥–Њ –Љ–Њ–Љ–µ–љ—В–∞ –≤—А–µ–Љ–µ–љ–Є.
- –Х—Б–ї–Є –Љ—Л –њ–Њ—Б—В–Њ—П–љ–љ–Њ –±—Г–і–µ–Љ «—Б–Ї–∞—А–Љ–ї–Є–≤–∞—В—М» —Д–∞–є–ї—Л WAL –љ–∞ –і—А—Г–≥—Г—О –Љ–∞—И–Є–љ—Г, –Ї–Њ—В–Њ—А–∞—П –±—Л–ї–∞ –Ј–∞–≥—А—Г–ґ–µ–љ–∞ —Б —В–µ—Е –ґ–µ —Д–∞–є–ї–Њ–≤ —А–µ–Ј–µ—А–≤–љ–Њ–є –±–∞–Ј—Л, —В–Њ —Г –љ–∞—Б –±—Г–і–µ—В —А–µ–Ј–µ—А–≤–љ—Л–є —Б–µ—А–≤–µ—А PostgreSQL –≤—Б–µ–≥–і–∞ –≤ –∞–Ї—В—Г–∞–ї—М–љ–Њ–Љ —Б–Њ—Б—В–Њ—П–љ–Є–Є (—Б–Њ–Ј–і–∞–љ–Є–µ —Б–µ—А–≤–µ—А–∞ –≥–Њ—А—П—З–µ–≥–Њ —А–µ–Ј–µ—А–≤–∞).
–Ъ–∞–Ї –Є –±—Н–Ї–∞–њ —Д–∞–є–ї–Њ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л, —Н—В–Њ—В –Љ–µ—В–Њ–і –Љ–Њ–ґ–µ—В –њ–Њ–і–і–µ—А–ґ–Є–≤–∞—В—М —В–Њ–ї—М–Ї–Њ –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є–µ –≤—Б–µ–є –±–∞–Ј—Л –і–∞–љ–љ—Л—Е –Ї–ї–∞—Б—В–µ—А–∞. –Ъ—А–Њ–Љ–µ —В–Њ–≥–Њ, –Њ–љ —В—А–µ–±—Г–µ—В –Љ–љ–Њ–≥–Њ –Љ–µ—Б—В–∞ –і–ї—П —Е—А–∞–љ–µ–љ–Є—П WAL —Д–∞–є–ї–Њ–≤.
1 –Э–∞—Б—В—А–Њ–є–Ї–∞
–Я–µ—А–≤—Л–є —И–∞–≥ -- –∞–Ї—В–Є–≤–Є—А–Њ–≤–∞—В—М –∞—А—Е–Є–≤–Є—А–Њ–≤–∞–љ–Є–µ. –≠—В–∞ –њ—А–Њ—Ж–µ–і—Г—А–∞ –±—Г–і–µ—В –Ї–Њ–њ–Є—А–Њ–≤–∞—В—М WAL —Д–∞–є–ї—Л –≤ –∞—А—Е–Є–≤–љ—Л–є –Ї–∞—В–∞–ї–Њ–≥ –Є–Ј —Б—В–∞–љ–і–∞—А—В–љ–Њ–≥–Њ –Ї–∞—В–∞–ї–Њ–≥–∞ pg_xlog. –≠—В–Њ –і–µ–ї–∞–µ—В—Б—П –≤ —Д–∞–є–ї–µ postgresql.conf:
–Я–Њ—Б–ї–µ —Н—В–Њ–≥–Њ –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –њ–µ—А–µ–љ–µ—Б—В–Є —Д–∞–є–ї—Л (–≤ –њ–Њ—А—П–і–Ї–µ –Є—Е –њ–Њ—П–≤–ї–µ–љ–Є—П) –≤ –∞—А—Е–Є–≤–љ—Л–є –Ї–∞—В–∞–ї–Њ–≥.
–Ф–ї—П —Н—В–Њ–≥–Њ –Љ–Њ–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —Д—Г–љ–Ї—Ж–Є—О rsync.
–Ь–Њ–ґ–љ–Њ –њ–Њ—Б—В–∞–≤–Є—В—М —Д—Г–љ–Ї—Ж–Є—О –≤ —Б–њ–Є—Б–Њ–Ї –Ј–∞–і–∞—З –Ї—А–Њ–љ–∞ –Є, —В–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, —Д–∞–є–ї—Л –Љ–Њ–≥—Г—В –∞–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Є –њ–µ—А–µ–Љ–µ—Й–∞—В—М—Б—П –Љ–µ–ґ–і—Г
—Е–Њ—Б—В–Љ–Є –Ї–∞–ґ–і—Л–µ –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –Љ–Є–љ—Г—В.

–Т –Ї–Њ–љ—Ж–µ, –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ —Б–Ї–Њ–њ–Є—А–Њ–≤–∞—В—М —Д–∞–є–ї—Л –≤ –Ї–∞—В–∞–ї–Њ–≥ pg_xlog –љ–∞ —Б–µ—А–≤–µ—А–µ PostgreSQL (–Њ–љ –і–Њ–ї–ґ–µ–љ –±—Л—В—М –≤ —А–µ–ґ–Є–Љ–µ –≤–Њ—Б—Б—В–∞–љ–Њ–≤–ї–µ–љ–Є—П).
–Ф–ї—П —Н—В–Њ–≥–Њ —Б–Њ–Ј–і–∞–µ—В—Б—П –≤ –Ї–∞—В–∞–ї–Њ–≥–µ –і–∞–љ–љ—Л—Е PostgreSQL —Б–Њ–Ј–і–∞—В—М —Д–∞–є–ї recovery.conf —Б –Ј–∞–і–∞–љ–љ–Њ–є –Ї–Њ–Љ–∞–љ–і–Њ–є –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є—П
—Д–∞–є–ї–Њ–≤ –Є–Ј –∞—А—Е–Є–≤–∞ –≤ –љ—Г–ґ–љ—Г—О –і–Є—А–µ–Ї—В–Њ—А–Є—О:
![\begin{lstlisting}[label=lst:backups17,caption=recovery.conf]
restore_command = 'cp /data/pgsql/archives/%f ''%p'''
\end{lstlisting}](postgresql-img67.png)
–Ф–Њ–Ї—Г–Љ–µ–љ—В–∞—Ж–Є—П PostgreSQL –њ—А–µ–і–ї–∞–≥–∞–µ—В —Е–Њ—А–Њ—И–µ–µ –Њ–њ–Є—Б–∞–љ–Є–µ –љ–∞—Б—В—А–Њ–є–Ї–Є –љ–µ–њ—А–µ—А—Л–≤–љ–Њ–≥–Њ –Ї–Њ–њ–Є—А–Њ–≤–∞–љ–Є—П, –њ–Њ—Н—В–Њ–Љ—Г —П –љ–µ —Г–≥–ї—Г–±–ї—П–ї—Б—П –≤ –і–µ—В–∞–ї–Є (–љ–∞–њ—А–Є–Љ–µ—А, –Ї–∞–Ї –њ–µ—А–µ–љ–µ—Б—В–Є –і–Є—А–µ–Ї—В–Њ—А–Є—О –°–£–С–Ф —Б –Њ–і–љ–Њ–≥–Њ —Б–µ—А–≤–µ—А–∞ –љ–∞ –і—А—Г–≥–Њ–є, –Ї–∞–Ї–Є–µ –Љ–Њ–≥—Г—В –±—Л—В—М –њ—А–Њ–±–ї–µ–Љ—Л). –С–Њ–ї–µ–µ –њ–Њ–і—А–Њ–±–љ–Њ –≤—Л –Љ–Њ–ґ–µ—В–µ –њ–Њ—З–Є—В–∞—В—М –њ–Њ —Н—В–Њ–є —Б—Б—Л–ї–Ї–µ http://www.postgresql.org/docs/9.0/static/continuous-archiving.html.
5 –Ч–∞–Ї–ї—О—З–µ–љ–Є–µ
–Т –ї—О–±–Њ–Љ —Б–ї—Г—З–∞–µ, —Г—Б–Є–ї–Є—П –Є –≤—А–µ–Љ—П, –Ј–∞—В—А–∞—З–µ–љ–љ—Л–µ –љ–∞ —Б–Њ–Ј–і–∞–љ–Є–µ –Њ–њ—В–Є–Љ–∞–ї—М–љ–Њ–є —Б–Є—Б—В–µ–Љ—Л —Б–Њ–Ј–і–∞–љ–Є—П –±—Н–Ї–∞–њ–Њ–≤, –±—Г–і—Г—В –Њ–њ—А–∞–≤–і–∞–љ—Л. –Э–µ–≤–Њ–Ј–Љ–Њ–ґ–љ–Њ –њ—А–µ–і—Г–≥–∞–і–∞—В—М –Ї–Њ–≥–і–∞ –њ—А–Њ–Є–Ј–Њ–є–і—Г—В –њ—А–Њ–±–ї–µ–Љ—Л —Б –±–∞–Ј–Њ–є –і–∞–љ–љ—Л—Е, –њ–Њ—Н—В–Њ–Љ—Г –±—Н–Ї–∞–њ—Л –і–Њ–ї–ґ–љ—Л –±—Л—В—М –љ–∞—Б—В—А–Њ–µ–љ—Л –і–ї—П PostgreSQL (–Њ—Б–Њ–±–µ–љ–љ–Њ, –µ—Б–ї–Є —Н—В–Њ –њ—А–Њ–і–∞–Ї—И–љ —Б–Є—Б—В–µ–Љ–∞).
Footnotes
- ... –Љ—Г—Б–Њ—А1
- –њ–Њ–і –Ї–Њ—В–Њ—А—Л–Љ –њ–Њ–љ–Є–Љ–∞—О—В—Б—П —Б—В–∞—А—Л–µ –≤–µ—А—Б–Є–Є –Є–Ј–Љ–µ–љ—С–љ–љ—Л—Е/—Г–і–∞–ї—С–љ–љ—Л—Е –Ј–∞–њ–Є—Б–µ–є
- ... —З–∞—Б—В–Њ2
- «—Б–ї–Є—И–Ї–Њ–Љ —З–∞—Б—В–Њ» –Љ–Њ–ґ–љ–Њ –Њ–њ—А–µ–і–µ–ї–Є—В—М –Ї–∞–Ї «—З–∞—Й–µ —А–∞–Ј–∞ –≤ –Љ–Є–љ—Г—В—Г». –Т—Л —В–∞–Ї–ґ–µ –Љ–Њ–ґ–µ—В–µ –Ј–∞–і–∞—В—М –њ–∞—А–∞–Љ–µ—В—А checkpoint_warning (–≤ —Б–µ–Ї—Г–љ–і–∞—Е): –≤ –ґ—Г—А–љ–∞–ї —Б–µ—А–≤–µ—А–∞ –±—Г–і—Г—В –њ–Є—Б–∞—В—М—Б—П –њ—А–µ–і—Г–њ—А–µ–ґ–і–µ–љ–Є—П, –µ—Б–ї–Є –Ї–Њ–љ—В—А–Њ–ї—М–љ—Л–µ —В–Њ—З–Ї–Є –њ—А–Њ–Є—Б—Е–Њ–і—П—В —З–∞—Й–µ –Ј–∞–і–∞–љ–љ–Њ–≥–Њ.
- ... –ї–Њ–≥–Њ–≤3
- –±—Г—Д–µ—А –љ–∞—Е–Њ–і–Є—В—Б—П –≤ —А–∞–Ј–і–µ–ї—П–µ–Љ–Њ–є –њ–∞–Љ—П—В–Є –Є —П–≤–ї—П–µ—В—Б—П –Њ–±—Й–Є–Љ –і–ї—П –≤—Б–µ—Е –њ—А–Њ—Ж–µ—Б—Б–Њ–≤
- ... –Ј–∞–њ—А–Њ—Б–∞4
- –£–Ї–∞–Ј—Л–≤–∞–µ—В –њ–ї–∞–љ–Є—А–Њ–≤—Й–Є–Ї—Г –љ–∞ —А–∞–Ј–Љ–µ—А —Б–∞–Љ–Њ–≥–Њ –±–Њ–ї—М—И–Њ–≥–Њ –Њ–±—К–µ–Ї—В–∞ –≤ –±–∞–Ј–µ –і–∞–љ–љ—Л—Е, –Ї–Њ—В–Њ—А—Л–є —В–µ–Њ—А–µ—В–Є—З–µ—Б–Ї–Є –Љ–Њ–ґ–µ—В –±—Л—В—М –Ј–∞–Ї–µ—И–Є—А–Њ–≤–∞–љ
- ... noatime5
- –њ—А–Є —Н—В–Њ–Љ –љ–µ –±—Г–і–µ—В –Њ—В—Б–ї–µ–ґ–Є–≤–∞—В—М—Б—П –≤—А–µ–Љ—П –њ–Њ—Б–ї–µ–і–љ–µ–≥–Њ –і–Њ—Б—В—Г–њ–∞ –Ї —Д–∞–є–ї—Г
- ... –і–Є—Б–Ї–Њ–≤6
- –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –ї–Њ–≥–Є—З–µ—Б–Ї–Є—Е —А–∞–Ј–і–µ–ї–Њ–≤ –љ–∞ –Њ–і–љ–Њ–Љ –і–Є—Б–Ї–µ –Ј–і–µ—Б—М, –Њ—З–µ–≤–Є–і–љ–Њ, –љ–µ –њ–Њ–Љ–Њ–≥—Г—В: –≥–Њ–ї–Њ–≤–Ї–∞ –≤—Б—С —А–∞–≤–љ–Њ –±—Г–і–µ—В –Њ–і–љ–∞
- ... pgtune7
- http://pgtune.projects.postgresql.org/
- ... –Ј–∞–њ—А–Њ—Б8
- –Є –њ–Њ—Н—В–Њ–Љ—Г EXPLAIN ANALYZE DELETE ... -- –љ–µ —Б–ї–Є—И–Ї–Њ–Љ —Е–Њ—А–Њ—И–∞—П –Є–і–µ—П
- ... –њ—А–∞–≤–Є–ї–∞9
- RULE -- —А–µ–∞–ї–Є–Ј–Њ–≤–∞–љ–љ–Њ–µ –≤ PostgreSQL —А–∞—Б—И–Є—А–µ–љ–Є–µ —Б—В–∞–љ–і–∞—А—В–∞ SQL, –њ–Њ–Ј–≤–Њ–ї—П—О—Й–µ–µ, –≤ —З–∞—Б—В–љ–Њ—Б—В–Є, —Б–Њ–Ј–і–∞–≤–∞—В—М –Њ–±–љ–Њ–≤–ї—П–µ–Љ—Л–µ –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–Є—П
- ... –њ–Њ—А—П–і–Њ–Ї10
- «–љ–∞ –љ–∞—И–µ–Љ —Д–Њ—А—Г–Љ–µ –±–Њ–ї–µ–µ 10000 –Ј–∞—А–µ–≥–Є—Б—В—А–Є—А–Њ–≤–∞–љ–љ—Л—Е –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є, –Њ—Б—В–∞–≤–Є–≤—И–Є—Е –±–Њ–ї–µ–µ 50000 —Б–Њ–Њ–±—Й–µ–љ–Є–є!»
- ... pgFouine11
- http://pgfouine.projects.postgresql.org/
- ...Slony-I12
- http://www.slony.info/
- ...PGCluster13
- http://pgfoundry.org/projects/pgcluster/
- ...pgpool-I/II14
- http://pgpool.projects.postgresql.org/
- ...Bucardo15
- http://bucardo.org/
- ...Londiste16
- http://skytools.projects.postgresql.org/doc/londiste.ref.html
- ... Skytools17
- http://pgfoundry.org/projects/skytools/
- ... Replicator18
- http://www.commandprompt.com/products/mammothreplicator/
- ...Postgres-R19
- http://www.postgres-r.org/
- ...RubyRep20
- http://www.rubyrep.org/
- ... –Є—Б—Е–Њ–і–љ–Є–Ї–Њ–≤21
- http://search.cpan.org/CPAN/authors/id/T/TU/TURNSTEP/
- ... –°–Ї–∞—З–Є–≤–∞–µ–Љ22
- http://bucardo.org/wiki/Bucardo#Obtaining_Bucardo
- ... Database23
- http://www.greenplum.com/index.php?page=greenplum-database
- ... Server24
- http://www.enterprisedb.com/products/gridsql.do
- ...Sequoia25
- http://www.continuent.com/community/lab-projects/sequoia
- ...PL/Proxy26
- http://plproxy.projects.postgresql.org/doc/tutorial.html
- ...HadoopDB27
- http://db.cs.yale.edu/hadoopdb/hadoopdb.html